短いレビュー
この投稿は、「サポートベクター法による指値注文の高頻度ポートフォリオのダイナミクスのモデリング」というタイトルの記事に基づいています 。 大まかに言って、 SparkとSpark MLLibを使用して、この記事で説明するアイデアを段階的に実装します。 著者は省略された例を使用しますが、私はニューヨーク証券取引所( NYSE )からの完全注文仕訳帳を使用します(サンプルデータはNYSE FTPで入手可能です)。 Spark MLLibは最初にマルチクラス分類をサポートしているため、サポートベクターメソッドを使用する代わりに、分類に決定木アルゴリズムを使用します。
問題と提案された解決策をよりよく理解したい場合は、その記事を読む必要があります。 1つまたは2つのセクションで問題の完全なレビューを行いますが、科学用語はあまり使いません。
予測モデリングは、モデルを選択または作成するプロセスであり、その目的は、可能な結果を最も正確に予測することです。
モデルアーキテクチャ
著者は、フォーマットされていない注文仕訳帳から特徴ベクトルを抽出するためのフレームワークを提案します。これは、分類法(サポートベクトル法や決定木の構築など)の入力データのセットとして使用して、有価証券の価格の変化(増加、減少、および変化しない)を予測できます。 ラベルが割り当てられた一連のテストデータ(価格変更)に基づいて、分類アルゴリズムは、定義済みのカテゴリのいずれかに新しいインスタンスを配置するモデルを構築します。
Time(sec) Price($) Volume Event Type Direction - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - - 34203.011926972 598.68 10 submission ask 34203.011926973 594.47 15 submission bid 34203.011926974 594.49 20 submission bid 34203.011926981 597.68 30 submission ask 34203.011926991 594.47 15 execution ask 34203.011927072 597.68 10 cancellation ask 34203.011927082 599.88 12 submission ask 34203.011927097 598.38 11 submission ask
表の各行は取引操作を表し、注文の受け取り、注文のキャンセル、またはその実行を反映しています。 到着時間は真夜中から数秒とナノ秒でカウントされ、価格は米ドルで、ボリュームはシェア数です。 質問とは、自分の株の一部について表示価格を売って要求することを意味し、入札とは、表示価格で購入したいことを意味します。
このマガジンから、各操作の完了後に注文ポートフォリオの状態を復元するのは非常に簡単です。 Investopediaで注文帳と指値注文ポートフォリオの詳細をご覧ください。 詳細は説明しません。 一般的な考え方は非常にシンプルで簡単です。
これは、価格レベルでソートされた特定の証券または金融商品の売り注文と買い注文の電子リストです。
特徴ベクトルを抽出し、テストデータを準備する
注文ポートフォリオから注文ポートフォリオが復元された後、属性を抽出し、
入力として使用される特徴ベクトルを生成できます。
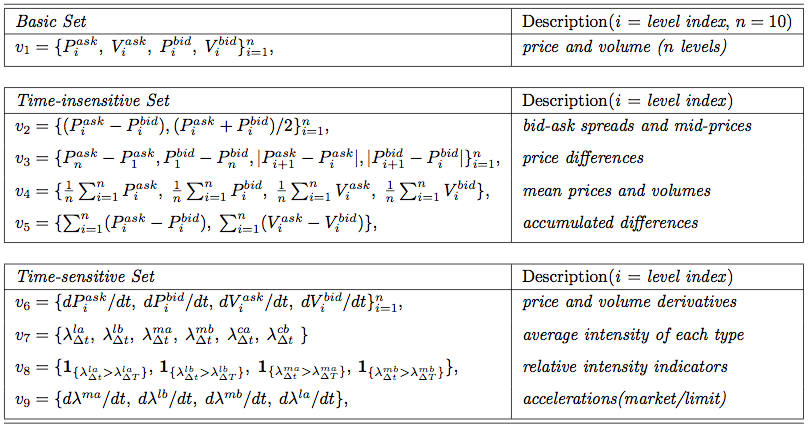
属性は、基本、時間に依存しない、時間に依存する3つのカテゴリに分類されます。 各カテゴリは、取得したデータに基づいて直接計算できます。 基本属性は、注文フラグから直接取得できる、n = 10の異なるレベル(特定の瞬間における注文ポートフォリオの価格レベルを表す)の値で、アスクフラグと入札フラグの両方の価格とボリュームです。 時間に依存しない属性は、基本セットの属性を使用して、単一の時点で簡単に計算できます。 これには、ビッドアスクスプレッドと平均スプレッド価格、価格帯、およびさまざまな価格レベルでの平均価格とボリュームが含まれます。これらは
v5
それぞれ属性セット
v2
、
v3
、
v5
計算されます。 キットv5は、askとbidの間の価格と株式の量の累積的な差を追跡するために必要です。 次に、過去の期間のデータの有意性を考慮して、時間依存カテゴリのパラメーターを計算します。 元の記事で属性計算の詳細を読むことができます。
テストデータのマークアップ
機械学習用のテストデータの準備には、シェアの値の変化が観察される各時点のラベル付けが必要です(たとえば、1秒)。 これは、現在の注文ポートフォリオとしばらくして形成された注文ポートフォリオの2つの注文ポートフォリオのみを必要とする単純なタスクです。
MeanPriceMove
ラベルを使用します。これは、
Stationary
、
Up
または
Down
値を取ることができます(変更、拡大、減少しません)。
trait Label[L] extends Serializable { label => def apply(current: OrderBook, future: OrderBook): Option[L] } sealed trait MeanPriceMove object MeanPriceMove { case object Up extends MeanPriceMove case object Down extends MeanPriceMove case object Stationary extends MeanPriceMove } object MeanPriceMovementLabel extends Label[MeanPriceMove] { private[this] val basicSet = BasicSet.apply(BasicSet.Config.default) def apply(current: OrderBook, future: OrderBook): Option[MeanPriceMove] = { val currentMeanPrice = basicSet.meanPrice(current) val futureMeanPrice = basicSet.meanPrice(future) val cell: Cell[MeanPriceMove] = currentMeanPrice.zipMap(futureMeanPrice) { (currentMeanValue, futureMeanValue) => if (currentMeanValue == futureMeanValue) MeanPriceMove.Stationary else if (currentMeanValue > futureMeanValue) MeanPriceMove.Down else MeanPriceMove.Up } cell.toOption } }
注文ログ
NYSE TAQ OpenBook注文マガジンを使用し、 Scala OpenBookライブラリを使用して解析します。 2取引日の無料のデータセットは、 NYSE FTPからダウンロードできます。入手は非常に簡単です。
TAQ(Trades and Quotes)データベースは、クローズドマーケットのT + 1基準で価格ガラスの時変値を提供します。 TAQデータ処理の結果は、取引戦略の開発とテスト、実際のデータの市場動向の分析、および監視または監査を目的とした市場調査に使用されます。
テストデータの準備
OrderBook
は2つのソートされたテーブルで構成されます。キーは価格で、値は株式数です。
case class OrderBook(symbol: String, buy: TreeMap[Int, Int] = TreeMap.empty, sell: TreeMap[Int, Int] = TreeMap.empty)
パラメータセット
Framianライブラリーの
Cell
ツールを使用して、抽出された特性値
Value
、
NA
または
NM
を視覚化し
NM
。
元の記事で定義したように、3つの属性セットがあります。 最初の2つの値は
OrderBook
データに基づいて計算されます。後者は、基本的にフォーマットされていない注文ジャーナルである
OrdersTrail
テーブルを作成する必要があり、その上でウィンドウフーリエ変換が実行されました。
sealed trait BasicAttribute[T] extends Serializable { self => def apply(orderBook: OrderBook): Cell[T] def map[T2](f: T => T2): BasicAttribute[T2] = new BasicAttribute[T2] { def apply(orderBook: OrderBook): Cell[T2] = self(orderBook).map(f) } }
sealed trait TimeInsensitiveAttribute[T] extends Serializable { self => def apply(orderBook: OrderBook): Cell[T] def map[T2](f: T => T2): TimeInsensitiveAttribute[T2] = new TimeInsensitiveAttribute[T2] { def apply(orderBook: OrderBook): Cell[T2] = self(orderBook).map(f) } }
trait TimeSensitiveAttribute[T] extends Serializable { self => def apply(ordersTrail: Vector[OpenBookMsg]): Cell[T] def map[T2](f: T => T2): TimeSensitiveAttribute[T2] = new TimeSensitiveAttribute[T2] { def apply(ordersTrail: Vector[OpenBookMsg]): Cell[T2] = self(ordersTrail).map(f) } }
そして、ここにサインの計算があります:
class BasicSet private[attribute] (val config: BasicSet.Config) extends Serializable { private[attribute] def askPrice(orderBook: OrderBook)(i: Int): Cell[Int] = { Cell.fromOption { orderBook.sell.keySet.drop(i - 1).headOption } } private[attribute] def bidPrice(orderBook: OrderBook)(i: Int): Cell[Int] = { Cell.fromOption { val bidPrices = orderBook.buy.keySet if (bidPrices.size >= i) { bidPrices.drop(bidPrices.size - i).headOption } else None } } private def attribute[T](f: OrderBook => Cell[T]): BasicAttribute[T] = new BasicAttribute[T] { def apply(orderBook: OrderBook): Cell[T] = f(orderBook) } def askPrice(i: Int): BasicAttribute[Int] = attribute(askPrice(_)(i)) def bidPrice(i: Int): BasicAttribute[Int] = attribute(bidPrice(_)(i)) val meanPrice: BasicAttribute[Double] = { val ask1 = askPrice(1) val bid1 = bidPrice(1) BasicAttribute.from(orderBook => ask1(orderBook).zipMap(bid1(orderBook)) { (ask, bid) => (ask.toDouble + bid.toDouble) / 2 }) } }
テストデータのラベル付け
注文からラベル付きデータを抽出するには、
LabeledPointsExtractor
を使用し
LabeledPointsExtractor
。
class LabeledPointsExtractor[L: LabelEncode] { def labeledPoints(orders: Vector[OpenBookMsg]): Vector[LabeledPoint] = { log.debug(s"Extract labeled points from orders log. Log size: ${orders.size}") // ... } }
そして、これはビルダーの助けを借りて改善できる方法です:
val extractor = { import com.scalafi.dynamics.attribute.LabeledPointsExtractor._ (LabeledPointsExtractor.newBuilder() += basic(_.askPrice(1)) += basic(_.bidPrice(1)) += basic(_.meanPrice) ).result(symbol, MeanPriceMovementLabel, LabeledPointsExtractor.Config(1.millisecond)) }
Extractor
、
MeanPriceMovementLabel
を使用して、
MeanPriceMovementLabel
を尋ねる、セット価格(ビッド価格)、平均価格(平均価格)の3つの属性を持つマークされたポイントを
MeanPriceMovementLabel
します。
分類モデルの起動
「実際の」アプリケーションでは、3つのセットすべてから36個の属性を使用します。 NYSE FTPからダウンロードしたデータの例を使用して、テストを実行します
EQY_US_NYSE_BOOK_20130403
はモデルを
EQY_US_NYSE_BOOK_20130404
し、
EQY_US_NYSE_BOOK_20130404
は適切な動作を確認します。
object DecisionTreeDynamics extends App with ConfiguredSparkContext with FeaturesExtractor { private val log = LoggerFactory.getLogger(this.getClass) case class Config(training: String = "", validation: String = "", filter: Option[String] = None, symbol: Option[String] = None) val parser = new OptionParser[Config]("Order Book Dynamics") { // .... } parser.parse(args, Config()) map { implicit config => val trainingFiles = openBookFiles("Training", config.training, config.filter) val validationFiles = openBookFiles("Validation", config.validation, config.filter) val trainingOrderLog = orderLog(trainingFiles) log.info(s"Training order log size: ${trainingOrderLog.count()}") // Configure DecisionTree model val labelEncode = implicitly[LabelEncode[MeanPriceMove]] val numClasses = labelEncode.numClasses val categoricalFeaturesInfo = Map.empty[Int, Int] val impurity = "gini" val maxDepth = 5 val maxBins = 100 val trainingData = trainingOrderLog.extractLabeledData(featuresExtractor(_: String)) val trainedModels = (trainingData map { case LabeledOrderLog(symbol, labeledPoints) => log.info(s"$symbol: Train Decision Tree model. Training data size: ${labeledPoints.count()}") val model = DecisionTree.trainClassifier(labeledPoints, numClasses, categoricalFeaturesInfo, impurity, maxDepth, maxBins) val labelCounts = labeledPoints.map(_.label).countByValue().map { case (key, count) => (labelEncode.decode(key.toInt), count) } log.info(s"$symbol: Label counts: [${labelCounts.mkString(", ")}]") symbol -> model }).toMap val validationOrderLog = orderLog(validationFiles) log.info(s"Validation order log size: ${validationOrderLog.count()}") val validationData = validationOrderLog.extractLabeledData(featuresExtractor(_: String)) // Evaluate model on validation data and compute training error validationData.map { case LabeledOrderLog(symbol, labeledPoints) => val model = trainedModels(symbol) log.info(s"$symbol: Evaluate model on validation data. Validation data size: ${labeledPoints.count()}") log.info(s"$symbol: Learned classification tree model: $model") val labelAndPrediction = labeledPoints.map { point => val prediction = model.predict(point.features) (point.label, prediction) } val trainingError = labelAndPrediction.filter(r => r._1 != r._2).count().toDouble / labeledPoints.count log.info(s"$symbol: Training Error = " + trainingError) } } }
学習エラー
個々の
ORCL
ティッカーの決定木構築方法による分類結果:
ORCL: Train Decision Tree model. Training data size: 64064 ORCL: Trained model in 3740 millis ORCL: Label counts: [Stationary -> 42137, Down -> 10714, Up -> 11213] ORCL: Evaluate model on validation data. Validation data size: 54749 ORCL: Training Error = 0.28603262160039455
ご覧のとおり、この非常に単純なモデルでは、データの約70%を正常に分類できました。
注 :モデルが非常にうまく機能するという事実にもかかわらず、これは、収益性の高い自動取引戦略を構築するためにモデルを正常に使用できるという意味ではありません。 最初に、私のモデルが95%の確率で平均70%の精度で価格の変化を予測するかどうかをチェックしません。 モデルは、証券価格のダイナミクスの「強度」を測定しません。さらに、実際には、モデルは取引コストをカバーするのに十分効率的に機能する必要があります。 実際の取引システムを構築するために重要な他のささいなことは言うまでもありません。
実際、システムを改善し、結果を検証するために多くのことができます。 残念ながら、十分なデータを取得することは非常に困難です。2取引日のデータでは、結論を導き、世界のすべてのお金を稼ぐことができるシステムの作成を開始するには不十分です。 しかし、これはかなり良い出発点だと思います。
結果
私は比較的簡単に、元の記事に記載されているよりも大規模なかなり複雑な研究プロジェクトを実施しました。
ビッグデータの分野における最近の技術により、サンプルを使用せずに利用可能なすべての情報を使用してモデルを作成できます。 すべての情報を使用すると、最適なモデルを作成し、完全なデータセットからすべての詳細を強調できます。
Githubアプリケーションコード