
写真:オーウェン・ハンフリーズ/ AP
調査結果は、調査質問に対する回答者の回答のベースとして理解されます。 研究の性質-後の分析のための社会学的、マーケティング、その他。 ESSに加えて、VTsIOM、Levada Center、TNS Russia、および他の多くの組織のWebサイトでさまざまな研究の例を見つけることができます。
連想ルールの定義と例
調査に適用されるトランザクションという用語は、1人の回答者から受け取った調査質問に対する一連の回答を意味します。 調査のトランザクション例:性別=女性、教育=高等、婚、状況=独身、...
調査の量的変数は、多くの場合、セグメントの形式で表示されます。年齢= 18〜25、過去6か月間の清涼飲料の消費量。 = 5〜10リットル。
したがって、研究の質問に対するあらゆる種類の答えが有限集合Iを決定し、調査データはトランザクションDの集合であり、その数は研究に対する回答者の数に等しい。
AをIの空でないサブセットとします。 Aのすべての要素を含むDのトランザクションの数は、 Aのサポートと呼ばれ、 supp(A)で示されます。
連想ルールX- > Yは、セットIからのX 、 Yの互いに素なサブセットのペアです。 ルールX- > Yの 2つの主な特徴-そのサポートと信頼性:
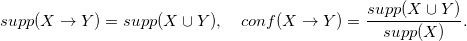
連想ルールの例年齢= 55+->社会的地位=高齢者。 彼の0.3のサポートは、調査回答者の30%が少なくとも55歳で退職していることを意味します。 ルール0.7の信頼性は、調査の回答者のうち少なくとも55歳のうち70%が年金受給者であることを示しています。
調査の量的変数は、多くの場合、セグメントの形式で表示されます。年齢= 18〜25、過去6か月間の清涼飲料の消費量。 = 5〜10リットル。
したがって、研究の質問に対するあらゆる種類の答えが有限集合Iを決定し、調査データはトランザクションDの集合であり、その数は研究に対する回答者の数に等しい。
AをIの空でないサブセットとします。 Aのすべての要素を含むDのトランザクションの数は、 Aのサポートと呼ばれ、 supp(A)で示されます。
連想ルールX- > Yは、セットIからのX 、 Yの互いに素なサブセットのペアです。 ルールX- > Yの 2つの主な特徴-そのサポートと信頼性:
連想ルールの例年齢= 55+->社会的地位=高齢者。 彼の0.3のサポートは、調査回答者の30%が少なくとも55歳で退職していることを意味します。 ルール0.7の信頼性は、調査の回答者のうち少なくとも55歳のうち70%が年金受給者であることを示しています。
世論調査の特徴は、調査のトランザクションが必ずしも等しく発生する可能性がないことです。 通常、調査の回答者は重みを特定しました。 Christian Borgelt(バージョン6.18)の実装のAprioriアルゴリズムでは、整数の正のトランザクションウェイトを使用して、その多重度を決定できます。
このプログラムのソースファイルは公開されています。 コードの小さな変更により、連想ルールを検索するためのアルゴリズムで正の実数値トランザクションウェイトを決定できます。
ESSは、欧州30か国以上の人口の態度、認識、意見、行動を測定するプロジェクトです。 プロジェクトのウェブサイトには、オープンな方法論と調査結果が含まれています。 例では、6波のデータが使用されました(バージョン2.1)。
問題の声明。
たとえば、 C = {デンマーク、ロシア、フランス}など、国Cのグループを分析用に選択します。
ESSデータに基づいて、 C国の1つのシェアが他のC国のこの特性のシェアを大幅に超える特性を特定する必要があります。
データ準備。
ルールX-> Yは、フィーチャXが Y国の代表者により特徴的であることを示す必要があります。
ESS調査の回答者の重み(dweight変数)を次のように表示します。
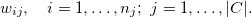 ここで、インデックスjは国を定義し、インデックスiはj番目の国の回答者をリストします。
ここで、インデックスjは国を定義し、インデックスiはj番目の国の回答者をリストします。
Cの各国の回答者の重みの合計が 100になるように重みを正規化する必要があります。

この重みの定義により、 supp(X-> Yj)ルールのサポートにより、国Yjの属性Xの割合が決まります。
特性Xのサポートは、 Cからのすべての国のこの特性のシェアの合計に等しくなります。
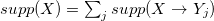 。
。
ルールX- > Yjの信頼性は、 Cからのすべての国のXのシェアの合計に対する、国Yjの属性Xのシェアの比率です。
調査データは、 外部パッケージを使用してR環境にアップロードされました。
国に共通の質問に対する回答者の回答は、 arulesパッケージを使用してトランザクションデータベースに変換されました。
問題の解決策を見つけて視覚化する。
ルールを見つけるときに、次の制限が使用されました。
1)ルールX- > YのYの右側には、国データのみが含まれます。
2) Xの左側は、2つ以下の要素(ステートメント)で構成されています。
3)ルールのサポートと信頼性の最小許容値は、それぞれ3%と2/3 * 100%です。
既知のように、取得される関連ルールの数は非常に多くなる可能性があります。 ソリューションを表示するために、 Tableau Publicサービスが使用されました。これにより、データの視覚化のためのコントロールパネルを作成できます。
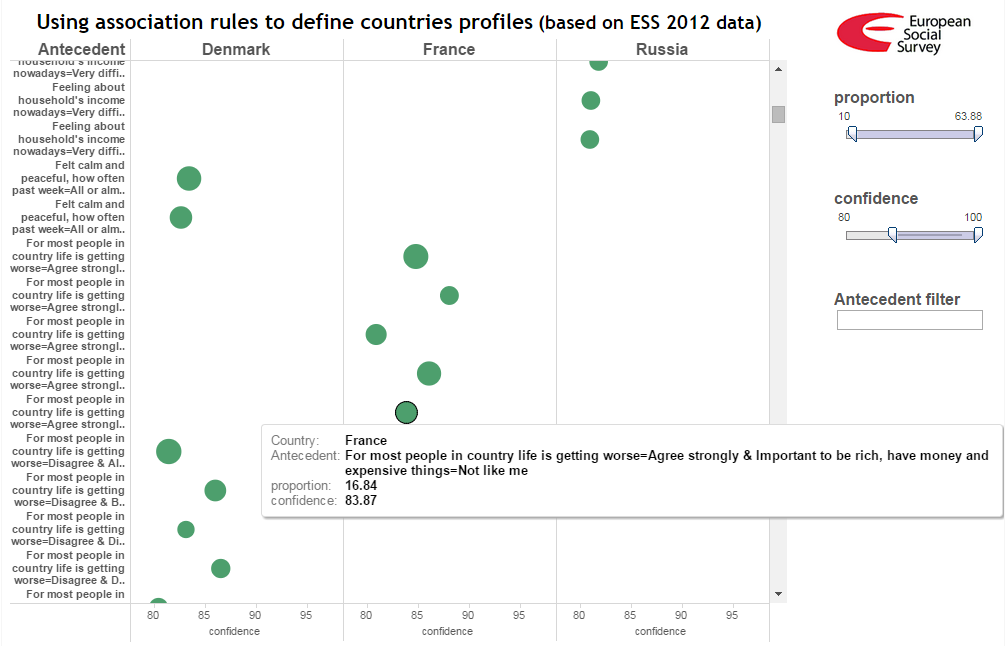
ハイライトされた規則は、15歳に達したフランスの居住者の約17%を報告しています。
-田舎のほとんどの居住者にとって、生活はすぐに悪化するという声明に完全に同意する
そして
-金持ちであること、大金、高価なものを持っていることが重要な人で自分を擬人化しないでください。
このルールの信頼度は高く、84%です。 デンマークとロシアでまったく同じと答えた回答者の合計シェアは、17%の5倍を下回っています(0.84 / 0.16> 5以降)。
各国ごとにこの規則の左側Xを個別に計算します。 次の結果が得られます

結果の規則を見ること自体に興味がある人はこのリンクに従うことができます。
マーケティング調査に関して。 その結果によれば、たとえば、同じタイプのさまざまなブランドの商品の忠実な消費者のグループでルールを検索することが可能です。 この場合、ブランドNのメーカーは「彼らの」顧客の特徴を明らかにし、競合他社の製品を好む消費者の特徴的な特性に関する情報を受け取ります。
加重トランザクションのデータベースでの連想ルールの検索により、回答者の投票によって得られたデータの探索的分析のタスクを解決できます。 このメソッドは、ポイント値(分数)に基づいて特性イベントを検出します。 記事の次の部分では、これらの結果を統計的に推定する方法を検討します。