簡単に言えば、プロジェクトの歴史に感謝する顧客を探して、退屈で面白くならないようにしました。 それが判明したかどうかは、判断するのはあなた次第です。 興味のある方はカットの下で聞いてください。
はじめに
オフトピック1、最初は読み飛ばすことができます
はい、私たちはそれがガチョウであり、アヒルではないことを知っています。 たまたま最初のページの画像を探していたとき、この不審なガチョウが一番好きでした。そして、私たちは、複数の写真バンクを通過しなかったと信じています。 そして、誰がアヒルを正確に何と言ったのですか? はい、それはガチョウであり、あなたを見ています。
いいえ、 DuckDuckGoプロジェクトとは提携していません。 したいのですが、いいえ。 私たちはDDGではなく、GDです。 一般的に、ある種のファッションは代替検索サービスを利用して、アヒルを主なものとして割り当てましたが、これを逃れませんでした。 しかし、彼らが名前を思いついたとき、それが他のもののように見えることは私の心を決して横切りませんでした。 本当だ!
よくある質問
はい、私たちはそれがガチョウであり、アヒルではないことを知っています。 たまたま最初のページの画像を探していたとき、この不審なガチョウが一番好きでした。そして、私たちは、複数の写真バンクを通過しなかったと信じています。 そして、誰がアヒルを正確に何と言ったのですか? はい、それはガチョウであり、あなたを見ています。
いいえ、 DuckDuckGoプロジェクトとは提携していません。 したいのですが、いいえ。 私たちはDDGではなく、GDです。 一般的に、ある種のファッションは代替検索サービスを利用して、アヒルを主なものとして割り当てましたが、これを逃れませんでした。 しかし、彼らが名前を思いついたとき、それが他のもののように見えることは私の心を決して横切りませんでした。 本当だ!
私たちのほとんどは、ブラウザにブックマークを保存する問題に精通しています。 私たちは常に新しいものを読んで、後ですぐに見つけられるように面白いものを先送りします。
私もそうしました。 面白いものはすべて、Google Chromeにブックマークとして保存しました。 多くのブックマークがあったとき、それらを分類する長いプロセスが始まりました-これが「Programming」フォルダが現れ、その中に「java」、そして「php」と「javascript」がその隣に置かれた方法です。 それから、どういうわけか私に興味を持ったたくさんの他の技術。 時間の経過とともに、これらすべてを理解することは困難になりました-標準機能では多くのことを行うことができません。 いくつかのリンクは一度に複数のフォルダーに起因する可能性があり、時々古い分類を忘れて、近所で新しい分類を作成しました。
たくさんのブックマークがあり、すぐにそれらをソートする時間がなかったとき、私は方法を見つけました-私は受信トレイフォルダを得ました。 金曜日にクリアすると約束し、そこで見つけたものをすべて捨て始めました。 しかし、これは機能しませんでした。金曜日には、常にもっと面白いことがありました。 そのため、ほとんどのブックマークは受信トレイにありました(400をはるかに超える場所にあると思っていた)。 時間が経つにつれて、私はちょうどそこに行き、そこから自分が必要なものと覚えているものを開いているという事実に気づきました。 覚えていないことですが、単に開いたのではなく、Googleで再度検索しました。
そこで、GrabDuckのアイデアが生まれました。 そして、なぜ検索エンジンで定期的に検索するのと同じように、ブックマークで検索できないのか-検索クエリを尋ねることによって。 結局、ほとんどの場合、私は必要な記事を見つけようとします(1)その記事が正確に何であるかを知っている(したがって、検索クエリの概要を説明できる)と(2)必要な記事がどこかにあったことを正確に覚えている(または多分1)。
「やめなさい」と私は自分に言いました。職場ではまさにそれをしているからです。 私はそれがどのように機能するかを知っています、実際の経験があります。 そして、ここにブーツなしの靴屋があります。
そこで、GrabDuckを開始しました。
プロジェクトについて
オフトピック2もスキップできます
いいえ、GrabDuckはスタートアップではありません。 すべてとすべての人を大きな言葉で呼ぶ伝統-スタートアップ。 投資家のためのこの終わりのない戦いに参加したくありません。 私たちはユーザーに利益をもたらす良いサービスを作りたいと思っています。
はい、私達はサービスを愛し、私達自身でそれを使用します。 私たちは皆それを知っていますが、実際には毎日GDを使用しています。 数か月前、友人に初期のプロトタイプを見せたとき、彼は尋ねました:「もしそうでなければどうしますか?」 「それは怖くない、サーバーは高価ではない、私はそれを自分で支払い、使用する」と私は答えた。 それ以来、私はそれを使用しています。
ありふれた(または継続的な回答)
いいえ、GrabDuckはスタートアップではありません。 すべてとすべての人を大きな言葉で呼ぶ伝統-スタートアップ。 投資家のためのこの終わりのない戦いに参加したくありません。 私たちはユーザーに利益をもたらす良いサービスを作りたいと思っています。
はい、私達はサービスを愛し、私達自身でそれを使用します。 私たちは皆それを知っていますが、実際には毎日GDを使用しています。 数か月前、友人に初期のプロトタイプを見せたとき、彼は尋ねました:「もしそうでなければどうしますか?」 「それは怖くない、サーバーは高価ではない、私はそれを自分で支払い、使用する」と私は答えた。 それ以来、私はそれを使用しています。
GrabDuckとは何ですか?
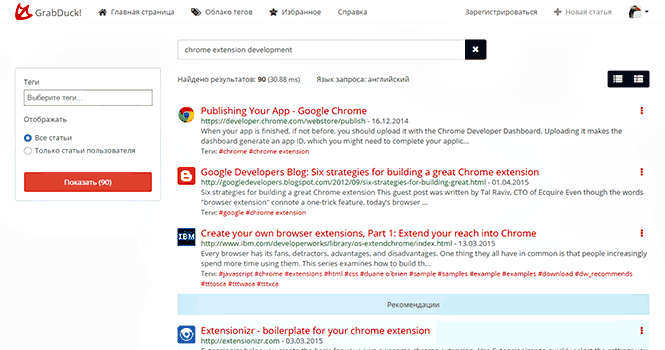
GrabDuckは、「Googleのように」検索できるブックマークストレージサービスです。 このサービスの主な目的は、ユーザーがドキュメントを「貯金箱」に入れて忘れることを許可することです。システムは必要なときにドキュメントを見つけるのに役立ちます。
したがって、GrabDuckは主に検索です。 保存したすべての資料(タイトルだけでなく、記事全体)の本格的な全文検索。 ユーザーが入力した単語のセットだけでなく、語彙に基づいて検索クエリのフレーズを見つけようとする検索。 これは、常に訓練されている検索、入力する検索クエリ、最も頻繁に開くドキュメントであり、自分の好みに適応します。
さらに、「無料」のボーナスとして、システムは、私の要求と好みに基づいて、再び私にとっても興味がある他のユーザーの記事からの推奨事項を提供します。 また、推奨記事が本当に興味深い場合は、この記事を自分に追加できます。
使用するもの
どのテクノロジーと何を使用しているかについてのコメント付きの短いレビュー。

私たちのサーバーは、いくつかのJavaアプリケーションを実行するApache Tomcatです。 Microservices Architectureの原則に従い、互いに通信する異なるモジュールでアプリケーションの異なる部分を取り出しました。 原則として、今ではすべてに対して1台のサーバーのみが必要ですが、将来、必要に応じて、たとえば、2番目のマシンで記事を解析する追加モジュールを展開して、他のすべてを変更せずにシステムの1つのコンポーネントのみの容量を増やすことができます。
フロントエンドサーバーとして、Nginxを使用します。 長い間、ApacheとNginxのどちらかを選択していましたが、その結果、2番目に落ち着きました。 理由は単純です-私たちにとっては、より軽量で構成が簡単であることがわかりました。
データを保存して操作するには、MySQL + Solrバンドルを使用します。 ハイブリッドの一種。各コンポーネントが最高の機能を発揮します。
MySQLは、データの整合性とストレージを正規化された方法で管理します。 ページコンテンツ、メタデータ、ブックマークにページがあるユーザー、タグなどの各ユーザーの個人情報など、ドキュメントに関するすべての必要な情報を常に複数のテーブルから収集できます。 このシステムの大きなマイナス点は、MySQLが非常に遅く、全文検索機能をほとんど提供しないことです。 一般に、検索の観点から見ると、現代のSQL製品が現在提供しているすべての全文検索ソリューションは、原則として、基本的な機能であり、非常に困難で、時には価値のあることを行うことはほとんど不可能です。
全体として、MySQLは検索にはあまり適していません。 したがって、ユーザーの要求に応じて何かを見つける必要がある場合、2番目のコンポーネント、つまり情報の検索と集約を担当するSolrが動作します。 データベースの各ドキュメントは、作成時または変更時にSolrに送信され、それに基づいて、検索に直接使用されるビューが作成されます。
したがって、NoSQLが提供する速度とパワーと組み合わされた従来のSQLデータベースのすべての利点があります。
仕組み
ユーザーがシステムに何かを追加するとどうなるかを考えてください。 これは、Chrome拡張機能を介して追加された単一のドキュメント、または多数のブックマークのインポートのいずれかであり、本質は変わらず、データは常に同じアルゴリズムに従います。
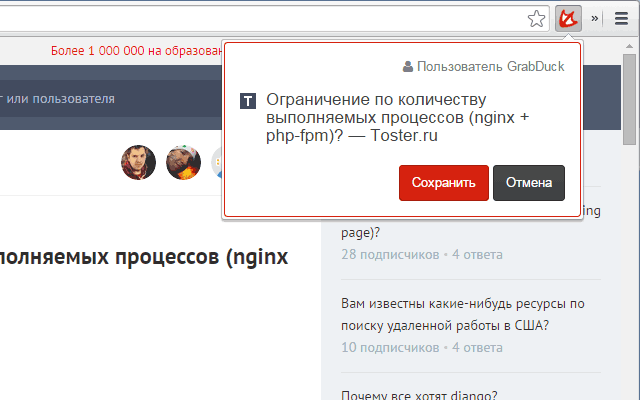
最初に、URLと、既知の場合はタイトルが保存される新しいドキュメントが作成されます。 この時点から、ユーザーはドキュメントを自宅で見ることができますが、もちろん全文検索はまだ利用できません。 しばらくして、原則として5分以内に解析タスクが開始されます。 ページを解析し、そこから記事を抽出するために、適応されたSnaktoryライブラリを使用します。 出力は、記事の内容、メタ情報、およびタグです。
次に、この記事が既にデータベースにあるかどうかを確認する必要があります。 その場合、保存する必要はなく、ユーザーは既存のものを「再利用」できます。 Canonical URLで一致を確認します 。 例として、ハブの記事には、少なくとも3つの異なる有効なURLがあります。google/ yandex用、モバイル表示用、デスクトップ用です。 この場合、正規URLは常に同じです。 同じスキームにより、たとえばユーザーが同じブックマークされたファイルを数回インポートしたい場合に、情報の重複を避けることができます。
リンクが重複していない場合、次のステップはドキュメントの言語を決定することです。 これは、2つのことに必要です。 まず、ドキュメントはこの特定の言語で検索するための検索インデックスに特別に適合されています(ロシア語と英語をサポートする現在、ドイツ語が次に並んでいます)。 そして第二に、この言語は推奨事項のフィルタリングに使用されます。 たとえば、ユーザーが英語とドイツ語で読んでいることに気付いている場合、ロシア語のドキュメントが検索クエリに含まれていても、ロシア語の推奨は表示されません。 言語を決定するために、言語検出ライブラリを使用します。 大きなマイナス、特にライブラリとおそらく言語を決定するためのすべてのアプローチの両方の両方-私たちの観察によれば、結果の100%では、少なくとも500文字を持っている必要があり、その後、品質が低下し始めます。
最後のステップでは、保存されたドキュメントに基づいて、Solr検索インデックスにエンティティを作成します。 この時点から、ドキュメントは全文検索と推奨事項の表示の両方で利用できます。
今どこにいるの
MVPの準備が整い、最初のユーザーが登場しました。 彼らが何かを探しているとき、私たちは一緒に幸せです。 ケースにコメントがある場合、特に動機付けられます。 ユーザーanton_slimの 1人に特別な感謝を申し上げます -ある人が実際にサービスを利用して、理解できず、曲がったもののリストを公開しました。
現在、サービスを積極的にテストしているため、すべての人に印象を共有してみてください。
ブログの検索トピックに、テクノロジーの使用方法、直面している問題、およびそれらの解決方法など、一般的に興味のあるすべてのものを書く予定です。
購読してチャットしましょう。