
このレビューでは、データ管理システムの編成と保護に対するHewlett-Packardのアプローチについて説明します。
バックアップと復元
現代の多くの組織では、データ量の増加や情報ビジネスシステムの可用性の要件に伴い、整合性、データ保護、緊急時の迅速な復旧を確保するためのシステムの要件が増加しています。 大部分の場合、情報システムはビジネスにとって重要性と重要性がさまざまであるため、組織は各クラスの要件を示して(ビジネスの重要性レベルに応じて)保護するシステムの分類子を開発します。
データバックアップシステムの主なメトリックは次のとおりです。
-RPO(復旧ポイント目標)-「復旧ポイント」、特定のシステムを復元する必要がある関連の瞬間。
-RTO(目標復旧時間)-システムを完全に復元する必要がある時間。
-バックアップウィンドウ-システムをバックアップする期間。
-保持ポリシー-システムのバックアップコピー(毎日、毎週、毎月、毎年)のポリシーと保持期間。
地理的に分散したITインフラストラクチャを備えた組織では、リモートオフィスとブランチのセキュリティ要件が上記の要件に追加されます。ローカルバックアップの保存ポリシー、通信チャネルの帯域幅、遅延などです。
上記の要件と機能、および保護するデータの量に応じて、さまざまなテクノロジーを使用してこれらの要件を満たすことができます。 ディスクアレイやテープライブラリなどのエンタープライズレベルのバックアップシステムの従来の機器には、この問題を部分的に解決するのに役立つテクノロジーが組み込まれています-ハードウェアスナップショットとデータクローン、マルチスレッドコピー、多重化、LANフリーバックアップ。
ただし、多くの場合、これでは十分ではありません。現在のデータ増加率を考慮に入れて、効果的かつ経済的な保護を確保することは重要な作業のようです。 最近では、バックアップシステムの多くのメーカーがさまざまな技術を使用して、重複情報のコピーを最小限に抑え始めています(重複排除技術)。 重複データの問題は、特にバックアップに関連しています。なぜなら、 組織の規制に従って、同じデータの複数のユニットから数十個のコピーにコピーして保存することが非常に頻繁に必要です。
重複排除
重複排除は、バックアップとリカバリに関連するいくつかのタスクを解決できるテクノロジーです。 次のことができます。
-データの完全なバックアップを作成する時間を大幅に(最大数十回)短縮します。
-バックアップからの復旧時間を短縮します。
-ユニモーダルデータブロックのみを保存することにより、バックアップの保存コストを大幅に削減します。
Hewlett-Packardのソリューションに重複排除テクノロジーを実装するアプローチは、次のようにユニークです。 HPでは、1つの統合ソリューションのフレームワーク内でのみ、ITインフラストラクチャのさまざまな部分で重複排除機能を組み合わせたり、重複排除されたブロックの異なるリポジトリ(ハードウェアとソフトウェアの両方)を使用したりできます。
重複排除の仕組み
Hewlett-Packardソリューションの重複排除プロセスは、一連の連続したアクションに分割できます。
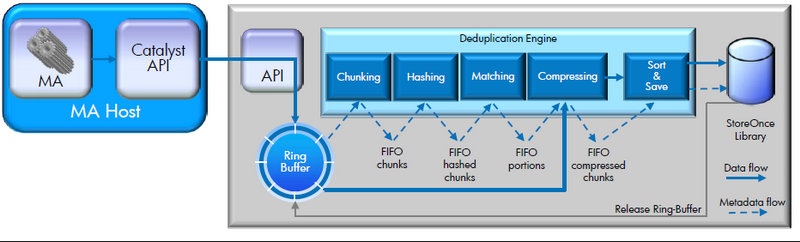
重複排除の前に、HP Data Protector Media Agentソフトウェアコンポーネントは、バックアップデータのストリームを特別なバッファーに転送します。 重複排除エンジンはこのバッファーからデータを選択し、次のアクションを実行します。
-データを可変長のブロックに分割します(平均ブロック長は4 KB)。
-ブロックのハッシュ和を計算します。
-ハッシュ量を比較して繰り返しブロックを定義します。
-一意のブロックを圧縮して、ストレージスペースを節約します。
-ブロックストレージにブロックをより最適に記録するためにブロックを並べ替えます。
その後、一意のデータのみがHP StoreOnceブロックストレージに保存されます。
重複排除の効率は、実際にコピーされた重複排除されたデータに対する(重複排除前の)コピーされるデータ量の比率に等しい係数として表されます。 重複排除の有効性に影響する主な要因は次のとおりです。
-バックアップ規制。 完全バックアップが多く、増分バックアップが少ないほど、重複排除の効率は高くなります。
-バックアップの保存期間。 保存期間が長いほど、そこに以前にコピーされたブロックが見つかる可能性が高くなり、したがって、重複排除の効率が高くなります。
-バックアップセッション間の相対的なデータ変更の割合。 これらの変更が多ければ多いほど、以前にコピーされたブロックがリポジトリにある可能性が低くなり、それに応じて重複排除係数が低くなります。
-ファイルサイズ。 重複排除ブロックのサイズに匹敵するサイズ(〜4 KB)のファイルの増分コピーは、これらのファイルの重複排除効率を低下させます。
HP StoreOnceフェデレーテッド重複排除
Hewlett-Packardソリューションのデータ重複排除は、ITインフラストラクチャの次のセクションで実行できます。
-保護されたアプリケーションのサーバー上。 この場合、保護されたサーバーからのデータはすでに重複排除された形式で提供されます。 このオプションは、シン通信チャネルで小規模なリモートブランチを保護するのに最適です。 ただし、重複排除はリソースを大量に消費するプロセスであり、アプリケーションサーバーの負荷が大幅に増加する可能性があることに注意してください。

-バックアップサーバー上。 この場合、クライアントからのデータは「そのまま」専用サーバーに送られ(重複排除なし)、このサーバーで重複排除され、中央のHP StoreOnceストレージに転送されます。 このオプションは、大規模なブランチを保護するのに適しています(クライアントからのトラフィックを保存する必要がなく、重複排除のためにサーバーを割り当てることをお勧めします)、保護されたサーバーの追加の負荷が望ましくない場合、およびアプリケーションサーバーOSのバージョンやビット深度が重複排除エンジンによってサポートされていない場合も同様です。

-専用ディスクライブラリ-バックアップストレージデバイス。 この場合、重複排除コンポーネントはすべてHP StoreOnceデバイスに組み込まれ、重複排除はHP StoreOnceのハードウェアリソースを使用して行われます。 このオプションの利点は、その比較的単純さと実装の速度、および現在のITインフラストラクチャに対する変更の最小化です。
一意のブロックのストレージとして、HP StoreOnceハードウェアディスクライブラリだけでなく、HP StoreOnce Virtual Storage Appliance(VSA)仮想ドライブ、およびHP Data Protector Software Storeも使用できます。
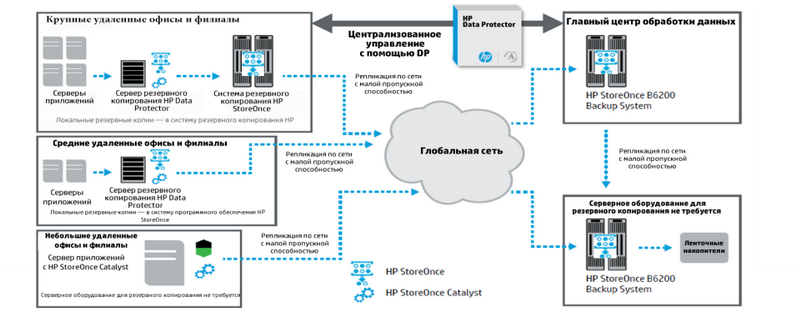
分散インフラストラクチャを効果的に保護するために、Hewlett-Packardソリューションには、特定の環境の要件に応じて、上記のタイプの重複排除を組み合わせる機能があります。 さらに、耐障害性を確保するために、異なるサイトにある複数のHP StoreOnceリポジトリ間でデータ複製を整理できます。 緊急時に、データをバックアップサイトに迅速に復元できます。 変更されたデータブロックのみがサイト間で送信されることに注意することが重要です。 これらのすべてのシナリオで、データのバックアップおよび回復プロセスの管理と監視は、単一のHP Data Protectorインターフェースから実行できます。
アーカイブ
Enterprise Strategy Group(ESG)による2013年の調査によると、現代のITのアーキテクチャとインフラストラクチャに影響を与える最も重要な傾向の1つは、保存されるデータ量の急激な増加です。 その影響は、ストレージサブシステムとアプリケーションサーバーの両方に及びます。 同時に、組織の保存データのビジネス価値は同じではありません。統計によると、ボリュームの約70〜80%は、古くなった、ほとんど必要のない、または重複した情報(たとえば、数か月または数年前に送受信された電子メール、データベースの古いレコード、多数のファイルのコピー)。 したがって、パフォーマンス、バックアップ頻度、回復時間などのSLA要件。 異なる情報のために異なる必要があります。

さらに、このような情報はすべて、たとえば、分析レポートまたは分析傾向を構築する目的、および情報セキュリティインシデントの監査または調査の場合に必要になることがあります。
中規模および大規模の組織で情報のストレージを最適化するために使用される最も効果的なアプローチの1つはアーカイブです。 バックアップとは異なり、アーカイブでは、原則として、生産的なデータのコピーは作成されません。
アーカイブされたオブジェクトは安価なストレージに転送されますが、インデックスが作成され、必要に応じてアーカイブからすばやく検索して復元できます。 さらに、特別な「スタブ」を生産的なサーバー(メールサーバーやファイルサーバーなど)にインストールできます。これにより、エンドユーザーは使い慣れたインターフェイスから対応するオブジェクトにすばやく切り替えることができます。
アーカイブは、バックアッププロセスの最適化の点でも役立ちます。 複数のリポジトリで同時にアーカイブを設定することにより、フォールトトレラントなアーカイブを取得できます。 同時に、生産性の高いサーバーがほとんどのデータの処理から解放されるため、アプリケーションのパフォーマンスインジケーターが向上し、そのようなサーバーのバックアップおよび復旧時間が大幅に短縮されます。 これにより、さまざまなデータクラスに柔軟なバックアップポリシーを実装できます。頻繁に使用される重要なデータはより頻繁にコピーされ、ディスクアレイ上のハードウェアイメージを使用して、古いデータはより少ない頻度で標準的な方法でコピーされます。

Hewlett-Packard社のポートフォリオには、構造化データ(データベース、構造化ファイル)と非構造化データ(メールオブジェクト、ファイル、MS SharePointオブジェクト、インスタントメッセージなど)の両方をアーカイブするための幅広いツールがあります。 アーカイブ内のオブジェクトをすばやく検索するには、HP Intelligent Data Operating Layer(IDOL)分析エンジンを使用します。これは、スケーラブルなアーキテクチャのおかげで、ほぼ無制限のデータ配列のインデックス作成と分析検索処理を整理できます。
素材の著者はマキシム・ルガンスキーです
ウクライナ 、 ジョージア 、 タジキスタンでのHPソリューションの配布。
CC MUK(Kiev) でのHPに関するトレーニングコース
4月20〜21日、 クラウドコンピューティング財団(EXIN)
6月1〜3日、 3PARディスクアレイの管理
6月4〜5日、 HP 3PARディスクアレイの管理:レプリケーションとパフォーマンス
MUK-Service-あらゆる種類のIT修理:保証、非保証修理、スペアパーツの販売、契約サービス