なぜこれが必要なのですか?
デバイスには非常に多くのデータが存在する可能性があります。 たとえば、この記事の執筆中に少し実験したCisco 2600ルーターは、12,000を超える値を生成します。

そして、私は言わなければならない、これは限界から遠いです。
この点で、いくつかの問題が発生します。この情報の山の中で有用なデータや必要なデータを見つける方法と、妥当な時間内にそれを行う方法です。
最初の解決策は表面にあります。「分割して征服する」という古代の戦略に従って、収集されたすべての値を比較的少数のカテゴリに分割する必要があります。 「どのように、どのカテゴリにデータを分割するか」という質問に対する答えも明らかです。これまでのデータ(すべて、またはほぼすべて)はMIBモジュールに分類され、通常、論理的に相互接続されたデータ要素(変数) 。
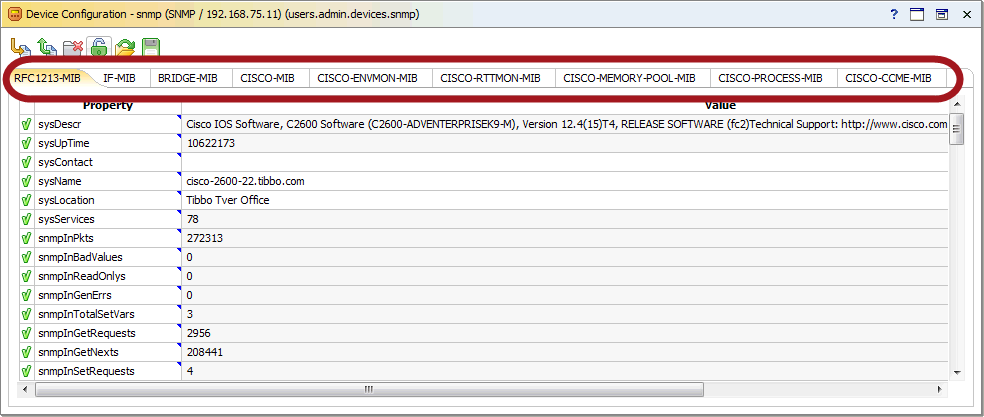
AggreGate Network ManagerでSNMPデータを分割する標準的な方法は、MIBモジュールによるものです。
したがって、必要な情報を抽出するサブタスクは、受信したデータをMIBモジュールにマッピングすることに削減されます(通信は変数の識別子-OIDによって実行されます )。
同様のことを行う多くのツールがあります。 そして、それらのすべて(少なくとも、私たちに知られているすべて)は、デバイスの完全な調査を実行します。
そのため、たとえば、 MIB WalkユーティリティはSolarWinds Engineerのツールセットの一部として実行されており、コンピューターから同じ「プッシー」を3.5〜4分間ポーリングします。 これはそれほど多くないようです。 ただし、これは「最大の」デバイスではなく、負荷の軽いローカルネットワークで利用できることを考慮する必要があります。 深刻なトラフィックがあり、デバイスが別のネットワーク上にある実際の「戦闘」プロジェクトの状況では、完全な調査の時間は桁違いに長くなる可能性があります。 そして、そのような調査が行われている間、デバイスを接続することを専門とする専門家は、「コンテキストを失う」と呼ばれる何らかの方法で気を散らします。ここでは、「タスクに戻る」ための時間を追加する必要があります(多くの場合、重要なアドオンであることが判明します)。 また、深刻なプロジェクトには多くのそのようなデバイスが存在することを考慮する必要があります。場合によっては、2〜3ダースのデバイスを調査する必要がありました。 最終的に、かなりの量が実行されます。
何らかの方法で、監視システムの実装に関する私たち自身の専門家、およびシステムを独立して構成するユーザーは、ある時点で、作業を著しく「妨げる」要因の1つとしてSNMPデバイスの完全な調査の完了の期待に言及し始めました。 そして、無駄な待ち時間を減らす方法を発明しなければなりませんでした。 その結果、システムに次のアルゴリズムを考案して実装しました。
SNMPデバイスで使用可能なMIBモジュールを迅速に検出するためのアルゴリズム
問題の良い声明は解決策の半分です。 この問題は次のように説明できます。
MIBモジュールとSNMPデバイスの リストが与えられたこの文言はすぐに疑問を提起します:「デバイスがサポートする MIBモジュール」とはどういう意味ですか?
これらの各MIBモジュールがこのデバイスによって「サポート」されているかどうかを判断する必要があります。
MIBモジュールは、SNMP変数のセットの説明です。 これに照らして、この質問に対する次の答えは論理的に聞こえます。MIBモジュールに記述されている変数の少なくとも1つがデバイスに存在する場合 、 MIBモジュールがサポートされると想定します 。
注 :困難はほとんどありません。同じ値を異なるMIBに記述できます。 以下でこれを考慮します。
最適化のアイデアは、この定義から直接得られます。 特定のMIBモジュールから1つの変数をデバイス上で見つけた場合、このモジュールの残りの変数は調査から除外できます 。 MIBモジュールの変数はほとんどの場合、かなり大きなブロックで処理されるため、目立って見えるだけでなく、実際に示すように、デバイスから取得する必要のあるデータの量を根本的に減らすことができます。 このため、ポーリング時間も短縮されます。
次のアルゴリズムを取得します。
- 最初に、ライブラリの各MIBに記述されているOIDのリストを作成します。 各OIDについて、そのMIBが属するMIBを覚えて(複数ある場合もありますか?)、これらのリストを1つのセットにマージし、OIDを辞書編集順にソートします
- GET_NEXTを使用してデバイスから次の変数を受け取り、それが属するMIBモジュールを定義したら、これらのモジュールをサポートされているもののリストに「含める」だけでなく、これらのMIBモジュール(のみ)に属するすべてのOIDをリストから削除することができますs。
- ポーリングリストに残っている最初の変数に対して既に行っている次のGET_NEXT。
したがって、デバイスを「ウォーク」(ウォーク)するのではなく、文字通り急いで急いで移動します。
MIBモジュール内のOIDの高い「グループ化」を念頭に置いて、OIDの初期リストを事前に「間引く」ことにより、アルゴリズムをわずかに改善できます。OIDのシーケンスが1つのMIBモジュールに属する場合(または、より一般的な場合、 MIBモジュールの1つのセットに)、それらすべてをチェックすることは意味がありません-それらの最初へのGET_NEXT要求は、いずれにしても、このグループのいずれかを提供するか、このデータブロックがデバイス上にないことを示します。
結果
図は、上記のCiscoルーターでMIBを検出した結果を示しています。
検出されたモジュールのリストの先頭:
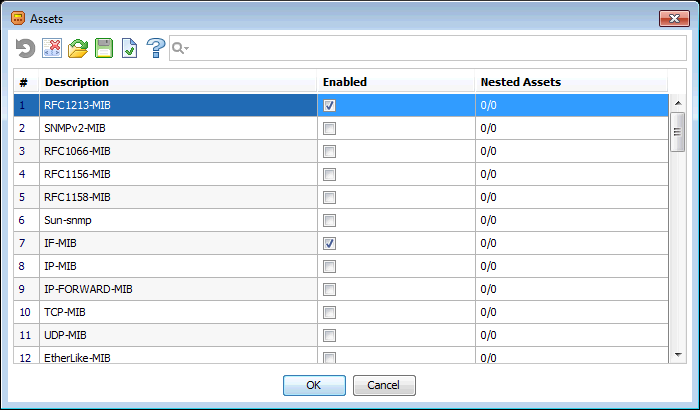
そして、これが彼の最後のページです。
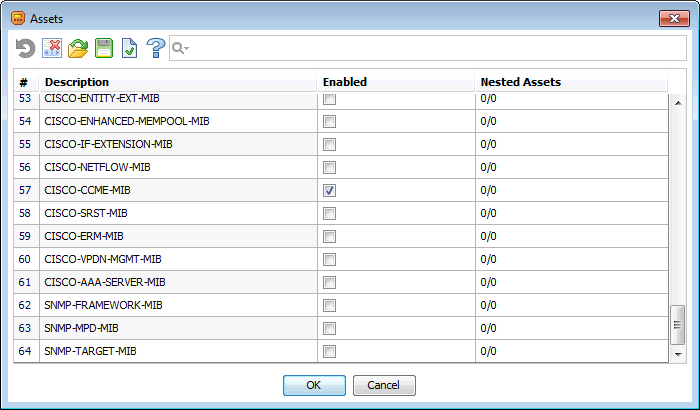
ご覧のとおり、 64個のMIBモジュールが検出されました 。 ちなみに、アルゴリズムの実行時間: 1-2秒。
次のスクリーンショットは、「非標準の」Hirschmann Railswitch RSB20デバイスでの検出結果を示しています。
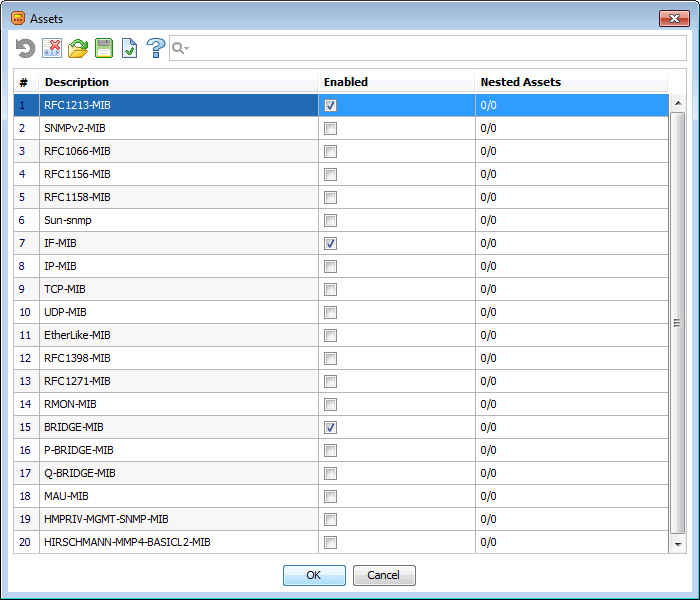
最後の2つのエントリは、このデバイスに付属する「カスタム」MIBモジュールを表します。
HirschmannでMIBモジュールを検出する「ライブ」プロセスは、 非標準デバイスの接続に関するビデオで見ることができます (グルメは英語版に興味があるかもしれません)。 確かに、MIBのすべての魔法は舞台裏に残り、2〜3秒の間隔に収まりますが、SNMPデバイスを操作するためのアプローチが明確になります。
おわりに
デバイスがサポートするMIBモジュールの高速検出アルゴリズムは、 AggreGate SNMPドライバーに実装されました。 現時点では、デバッグされており、ITインフラストラクチャをさまざまなレベルで数年間監視するためのさまざまなプロジェクトで着実に取り組んできました。 過去1年間、エラーは特定されておらず、少なくともアイデアが正しいことを示唆しています。 これまで、不正確な部分が時々発生していましたが、それらの99%はSNMP仕様の点で不正確なデバイス上のエージェントエージェントのさまざまな実装に関連していました。 しかし、クライアントは常に正しいので、そのような「機能」を考慮してドライバーを修正する必要がありました。 これは、このアルゴリズムの実装に関するものです。