
TarantoolはLuaのアプリケーションサーバーです 。 彼はデータをディスクに保存する方法を知っており、それらにすばやくアクセスできます。 Tarantoolは、単位時間あたりのデータフローが大きいタスクで使用されます。 数値について言えば、これらは毎秒数万から数十万の操作です。 たとえば、私のプロジェクトの1つでは、1秒あたり80,000を超えるリクエストが生成(フェッチ、挿入、更新、削除)され、負荷は12のTarantoolインスタンスを持つ4つのサーバーに均等に分散されます。 すべての最新のDBMSがこのような負荷を処理できるわけではありません。 さらに、非常に多くのデータがあるため、要求の完了を待機するのは非常に高価なので、プログラム自体はあるタスクから別のタスクにすばやく切り替える必要があります。 サーバー(すべてのコア)のCPUの効果的で均一なロードには、Tarantoolと非同期プログラミング技術が必要です。
tarantool-pythonコネクタはどのように機能しますか?
非同期Pythonコードについて話す前に、通常の同期PythonコードがどのようにTarantoolと対話するかを十分に理解する必要があります。 CentOS用のTarantool 1.6のバージョンを使用します。インストールは簡単で簡単で、プロジェクトのWebサイトで詳細に説明されています 。また、広範なユーザーガイドもあります。 最近、優れたドキュメントの出現により、Tarantoolインスタンスの起動方法と使用方法を理解しやすくなりました。 有用な記事「 Tarantool 1.6-始めましょう 」が最近Habréに掲載されました。
これで、Tarantoolがインストールされ、実行され、すぐに使用できます。 Python 2.7を使用するには、 pypiからtarantool-pythonコネクタを使用します 。
$ pip install tarantool-python
これで問題を解決できます。 そして、彼らは何ですか? 私のプロジェクトの1つでは、さらに処理するためにTarantoolでデータフローを「折り畳む」必要がありましたが、1つのデータパケットのサイズは約1.5 KBです。 問題の解決に進む前に、問題をよく研究し、選択したアプローチとツールをテストする必要があります。 パフォーマンステストスクリプトは初歩的で、数分で記述されます。
import tarantool import string mod_len = len(string.printable) data = [string.printable[it] * 1536 for it in range(mod_len)] tnt = tarantool.connect("127.0.0.1", 3301) for it in range(100000): r = tnt.insert("tester", (it, data[it % mod_len]))
簡単です。サイクルで、Tarantoolで10万個の挿入を順番に行います。 私の仮想マシンでは、このコードは平均で32秒で実行されます。つまり、1秒あたり約3000回の挿入です。 プログラムは単純であり、結果として得られるパフォーマンスが十分であれば、「早すぎる最適化は悪」であるため、これ以上何もできません。 しかし、これは私たちのプロジェクトにとって十分ではなく、Tarantool自体がはるかに優れた結果を示すことができます。
コードのプロファイリング
突発的な措置を講じる前に、コードとその仕組みを慎重に検討します。 Pythonコードのプロファイリングに関する一連の記事を書いてくれた同僚のDreadatourに感謝します。
プロファイラーを起動する前に、プログラムの仕組みを理解しておくと役立ちます。結局のところ、プロファイリングに最適なツールは開発者の頭です。 スクリプト自体は単純です。そこで学ぶ特別なものはありません。「深く掘り下げて」みます。 コネクタドライバーの実装を見ると、要求がmsgpackライブラリを使用してパッケージ化され、 sendall呼び出しを使用してソケットに送信され、応答の長さと応答自体がソケットから差し引かれていることがわかります。 もうおもしろい。 このコードの実行の結果、Tarantoolソケットで何回の操作が行われますか? この場合、1回のtnt.insertリクエストに対して、1回のsocket.sendall呼び出し (データの送信)と2回のsocket.recv呼び出し (応答の長さおよび応答自体の受信)が行われます。 gazeメソッドでは、10万件のレコードを挿入するために、200k + 100k = 300kの読み取り/書き込みシステムコールが行われます。 そしてプロファイラー(私はcProfileとkcachegrindを使用して結果を解釈しました)が結論を確認します:
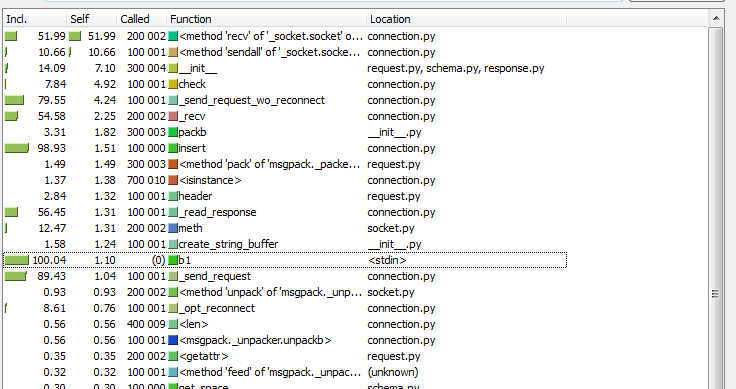
このスキームで何を変更できますか? もちろん、まず最初に、システムコールの数、つまりTarantoolソケットでの操作を減らしたいと思います。 これは、「バンドル」でtnt.insert要求をグループ化し、すべての要求に対してsocket.sendallを一度に呼び出すことで実行できます。 同様に、1つのsocket.recvのソケットからTarantoolからの応答パケットを読み取ることができます。 通常の古典的なプログラミングスタイルでは、これはそれほど単純ではありません。データ用のバッファー、バッファーにデータを蓄積するための遅延が必要であり、クエリ結果を遅延なく順番に返す必要もあります。 しかし、リクエストが多く、突然非常に少ないリクエストがあった場合はどうでしょうか? また、回避しようとする遅延があります。 一般に、根本的に新しいアプローチが必要ですが、最も重要なのは、元のタスクのコードを元のように単純なままにしておきたいことです。 私たちの問題を解決するために、非同期フレームワークが助けになります。
GeventとPython 2.7
いくつかの非同期フレームワークを処理する必要がありました: twisted 、 tornado 、 geventなど。 Habréでは、これらのツールの比較とベンチマークの問題、たとえば、 1回と2回は 、複数回提起されています。
私の選択はgeventに落ちました。 主な理由は、I / O操作での作業の効率性とコード記述の単純さです。 このライブラリの使用に関する優れたチュートリアルは、 ここにあります 。 また、 このチュートリアルには、クイッククローラーの典型的な例があります。
import time import gevent.monkey gevent.monkey.patch_socket() import gevent import urllib2 import json def fetch(pid): url = 'http://json-time.appspot.com/time.json' response = urllib2.urlopen(url) result = response.read() json_result = json.loads(result) return json_result['datetime'] def synchronous(): for i in range(1,10): fetch(i) def asynchronous(): threads = [] for i in range(1,10): threads.append(gevent.spawn(fetch, i)) gevent.joinall(threads) t1 = time.time() synchronous() t2 = time.time() print('Sync:', t2 - t1) t1 = time.time() asynchronous() t2 = time.time() print('Async:', t2 - t1)
このテスト用の仮想マシンでは、次の結果が得られました。
Sync: 1.529 Async: 0.238
素晴らしいパフォーマンスの向上! geventを使用して同期コードを非同期で動作させるには、URLのダウンロード自体を並列化するかのように、 gevent.spawnでfetch関数呼び出しをラップする必要がありました。 また、 monkey.patch_socket()を実行する必要があり、その後、ソケットを操作するためのすべての呼び出しが協調的になります。 したがって、1つのURLがダウンロードされ、プログラムがリモートサービスからの応答を待機している間、geventエンジンは他のタスクに切り替え、無駄な待機の代わりに他の利用可能なドキュメントをダウンロードしようとします。 Pythonの腸では、すべてのgeventスレッドが順番に実行されますが、期待(システムコールの待機 )がないため、最終結果はより速くなります。
見栄えがよく、最も重要なのは、このアプローチがタスクに非常に適していることです。 ただし、tarantool-pythonドライバーはgeventをそのまま使用する方法を認識していないため、その上にgtarantoolコネクターを作成する必要がありました。
GeventとTarantool
gtarantoolコネクタは、geventおよびTarantool 1.6で動作し、pypiで利用可能になりました。
$ pip install gtarantool
一方、私たちの問題の新しい解決策は次の形式を取ります。
import gevent import gtarantool import string mod_len = len(string.printable) data = [string.printable[it] * 1536 for it in range(mod_len)] cnt = 0 def insert_job(tnt): global cnt for i in range(10000): cnt += 1 tnt.insert("tester", (cnt, data[it % mod_len])) tnt = gtarantool.connect("127.0.0.1", 3301) jobs = [gevent.spawn(insert_job, tnt) for _ in range(10)] gevent.joinall(jobs)
同期コードと比較して何が変わったのですか? 10kエントリの挿入を10個の非同期グリーンスレッドに分割します。各スレッドは、ループでtnt.insertを約1万回呼び出し、すべてTarantoolへの単一接続を介して行います。 プログラムの実行時間は12秒に短縮されました。これは同期バージョンのほぼ3倍の効率であり、データベースへのデータ挿入数は1秒あたり8,000に増加しました。 なぜこのようなスキームは高速ですか? トリックは何ですか?
gtarantoolコネクターは、内部的にTarantoolソケットへのリクエストのバッファーを使用し、「グリーンスレッド」を分離してこのソケットの読み取り/書き込みを行います。 プロファイラーで結果を確認しようとします(今回はGreenletプロファイラーを使用しました-これはグリーンレット用に調整されたyappiプロファイラーです):

kcachegrindの結果を分析すると、 socket.recv呼び出しの数が100kから10kに減少し、 socket.send呼び出しの数が200kから2.5kに減少したことがわかります。 実際、これにより、Tarantoolでの作業がより効率的になります。グリーンライターが軽く、「安い」ため、システムコールが少なくなります。 そして、最も重要で楽しいことは、ソースプログラムコードが実際には「同期」のままであったことです。 いツイストコールバックはありません。
私たちはこのアプローチをプロジェクトでうまく使用しています。 利益は他に何ですか:
- フォークを放棄しました。 複数のPythonプロセスを使用し、各プロセスで単一のgtarantool接続(または接続プール)を使用できます。
- グリーンレットの内部では、切り替えはUnixプロセス間の切り替えよりもはるかに高速で効率的です。
- プロセスの数を減らすことで、メモリ消費が大幅に削減されました。
- Tarantoolソケットを使用した操作の数を減らすと、Tarantool自体の操作の効率が向上し、CPUの消費が少なくなりました。
Python 3とTarantoolはどうですか?
さまざまな非同期フレームワークの違いの1つは、Python 3で機能することです。たとえば、geventはそれをサポートしていません。 さらに、tarantool-pythonライブラリはPython 3でも機能しません(まだ移植できていません)。 まあ、どのように?
ジェダイの道は厄介です。 Pythonの2番目と3番目のバージョンのtarantoolと非同期作業を比較したかったので、Python 3.4ですべてを書き直すことにしました。 Python 2.7以降、コードを書くのは少し珍しいことでした:
- 「foo」が機能しない
- すべての文字列はクラスstrのオブジェクトです
- タイプロングなし
- ...
しかし、中毒は成功し、今すぐPython 2.7のコードを記述して、Python 3での変更なしで動作するようにしています。
tarantool-pythonコネクターを少し変更する必要がありました。
- StandartErrorは例外に置き換えられました
- strに置き換えられたベースストリング
- xrangeは範囲に置き換えられました
- 長い -削除済み
Python 3.4で動作する同期コネクタのフォークが判明しました。 徹底的なチェックの後、このコードはおそらくライブラリのメインブランチに注がれますが、現時点ではGithubから直接インストールできます。
$ pip install git+https://github.com/shveenkov/tarantool-python.git@for_python3.4
最初のベンチマーク結果は熱意を引き起こしませんでした。 サイズが1.5KBの100kレコードを挿入する通常の同期バージョンは、平均して1分強で実行され始めました。これは、Pythonの2番目のバージョンの同じコードの2倍の長さです。 プロファイリングが再び助けになります。

わあ! それで、400k socket.recv呼び出しはどこから来たのですか? 200k socket.sendall呼び出しはどこから来たのですか? 私は再びtarantool-pythonコネクタコードに突入しなければなりませんでした。判明したように、これはPython文字列とdictキーとしてのバイトの結果です。 たとえば、次のコードを比較できます。
Python 3.4:
>>> a=dict() >>> a[b"key"] = 1 >>> a["key"] Traceback (most recent call last): File "<stdin>", line 1, in <module> KeyError: 'key'
Python 2.7:
>>> a=dict() >>> a[b"key"] = 1 >>> a["key"] 1
このような些細なことは、コードをPython 3に移植する複雑さの鮮明な例であり、ここでのテストでさえも、正式にすべてが機能するため、必ずしも役立つわけではありませんが、2倍遅く動作しますが、これは大きな違いです。 コードを修正し、コネクタに「バイトのカップル」を追加します( コネクタコードの変更へのリンク、および別の変更 )-結果があります!

さて、今は悪くない! コネクターの同期バージョンは、平均で35秒でタスクに対処し始めました。これは、Python 2.7よりもわずかに遅いですが、既にそれを使用できます。
Python 3でasyncioに移行する
Asyncioは、そのままでPython 3のコルーチンです。 ドキュメント 、例、asyncioおよびPython 3用の既製ライブラリがあります。一見したところ、すべてが非常に複雑で混乱しています(少なくともgeventと比較して)が、さらに調べるとすべてが適切に配置されます。 それで、いくらかの努力の後、私はasyncioのTarantoolコネクタのバージョン-aiotarantoolを書きました。
このコネクタは、pypiからも利用できます。
$ pip install aiotarantool
asyncioでの元のタスクのコードは、元のバージョンよりも少し複雑になっています。 構造からの歩留まりが現れ、 @ asyncio.coroutineデコレータが現れましたが、一般的に私はそれが好きで、geventとそれほど違いはありません:
import asyncio import aiotarantool import string mod_len = len(string.printable) data = [string.printable[it] * 1536 for it in range(mod_len)] cnt = 0 @asyncio.coroutine def insert_job(tnt): global cnt for it in range(10000): cnt += 1 args = (cnt, data[it % mod_len]) yield from tnt.insert("tester", args) loop = asyncio.get_event_loop() tnt = aiotarantool.connect("127.0.0.1", 3301) tasks = [asyncio.async(insert_job(tnt)) for _ in range(10)] loop.run_until_complete(asyncio.wait(tasks)) loop.close()
このオプションは、タスクを平均して13秒で処理します(1秒あたり約7.5kの挿入が判明します)。これは、Python 2.7およびgeventのバージョンよりも若干遅いですが、すべての同期バージョンよりもはるかに優れています。 Aiotarantoolには、 asyncio.orgで利用できる他のライブラリとの小さなながらも非常に重要な違いが1つあります。tarantool.connect呼び出しはasyncio.event_loopの外部で行われます。 実際、この呼び出しは実際の接続を作成しません。tnt.insertからのyieldからの最初の呼び出し中にコルーチンの1つの内部で後で行われます 。 このアプローチは、asyncioでプログラミングするときに、より簡単で便利に思えました。
従来、プロファイリングの結果(私はyappiプロファイラーを使用しましたが、 asyncioを使用する場合、関数呼び出しの数を正確に計算できないと思われます):

その結果、 StreamReader.feed_dataとStreamWriter.writeの 5k呼び出しが表示されます。これは、間違いなく、同期バージョンのsocket.recvの 200k呼び出しとsocket.sendallの 100k呼び出しよりもはるかに優れています。
アプローチの比較
Tarantoolを使用する際に考慮されるオプションの比較結果を示します。 ベンチマークコードは、 gtarantoolおよびaiotrantoolライブラリの testsディレクトリにあります 。 ベンチマークでは、サイズが1.5 KBの100,000レコードを挿入、検索、変更、および削除します。 各テストは10回実行され、重要なのは正確な数値ではなく(特定の鉄に依存する)、その比率なので、表には平均の丸められた値が表示されます。
比較する:
- Python 2.7での同期tarantool-python;
- Python 3.4での同期tarantool-python;
- Python 2.7用gtarantoolを使用した非同期バージョン。
- Python 3.4でaiotarantoolを使用した非同期バージョン。
テスト実行時間(秒単位)(少ないほど良い):
| 運営
(10万エントリ) | tarantool-python
2.7 | tarantool-python
3.4 | ガランツール
(イベント) | アイオタランツール
(非同期) |
|---|---|---|---|---|
| 挿入する | 34 | 38 | 11 | 13 |
| 選択する | 23 | 23 | 10 | 13 |
| 更新する | 34 | 33 | 10 | 14 |
| 削除する | 35 | 35 | 10 | 13 |
| 運営
(10万エントリ) | tarantool-python
2.7 | tarantool-python
3.4 | ガランツール
(イベント) | アイオタランツール
(非同期) |
|---|---|---|---|---|
| 挿入する | 3000 | 2600 | 9100 | 7700 |
| 選択する | 4300 | 4300 | 10,000 | 7700 |
| 更新する | 2900 | 3000 | 10,000 | 7100 |
| 削除する | 2900 | 2900 | 10,000 | 7700 |
サーバーから最大を絞る
サーバーのリソースを最も効率的に使用するために、ベンチマークのコードを少し複雑にしてみましょう。 1つのPythonプロセスでデータの削除、挿入、変更、および選択(かなり一般的な負荷プロファイル)を同時に行い、そのようなプロセスをいくつか作成します(22(マジックナンバー)など)。 マシンに24個のコアがある場合、1つのコアをシステムに残し(念のため)、1つのコアをTarantoolに(それで十分です!)、残りの22個をPythonプロセスに割り当てます。 geventとasyncioの両方で比較を行います。ベンチマークコードは、gtarantoolの場合とaiotarantoolの場合です。
その後の比較のために、結果を明確かつ美しく表示することが非常に重要です。 Tarantool 1.6の新しいバージョンの機能を評価するときが来ました。実際、Luaのインタープリターです。つまり、データベースで直接Luaコードを実行できます。 私たちは最も簡単なプログラムを書いており、タランツールはすでにその統計をグラファイトに送信することができます。 Tarantoolの起動initスクリプトにコードを追加します(もちろん、実際のプロジェクトでは、そのようなものを別のモジュールに入れる方が良いでしょう)。
fiber = require('fiber') socket = require('socket') log = require('log') local host = '127.0.0.1' local port = 2003 fstat = function() local sock = socket('AF_INET', 'SOCK_DGRAM', 'udp') while true do local ts = tostring(math.floor(fiber.time())) info = { insert = box.stat.INSERT.rps, select = box.stat.SELECT.rps, update = box.stat.UPDATE.rps, delete = box.stat.DELETE.rps } for k, v in pairs(info) do metric = 'tnt.' .. k .. ' ' .. tostring(v) .. ' ' .. ts sock:sendto(host, port, metric) end fiber.sleep(1) log.info('send stat to graphite ' .. ts) end end fiber.create(fstat)
Tarantoolを起動して、統計付きのグラフを自動的に取得します。 かっこいい 私はこの機能が本当に気に入りました!
次に、2つのベンチマークを実行します。最初のベンチマークでは、データを同時に削除、挿入、変更、選択します。 2番目のベンチマークでは、サンプリングのみを実行します。 すべてのグラフで、横軸は時間を示し、縦軸は1秒あたりの操作数を示します。
- gtarantool(挿入、選択、更新、削除):

- aiotarantool(挿入、選択、更新、削除):

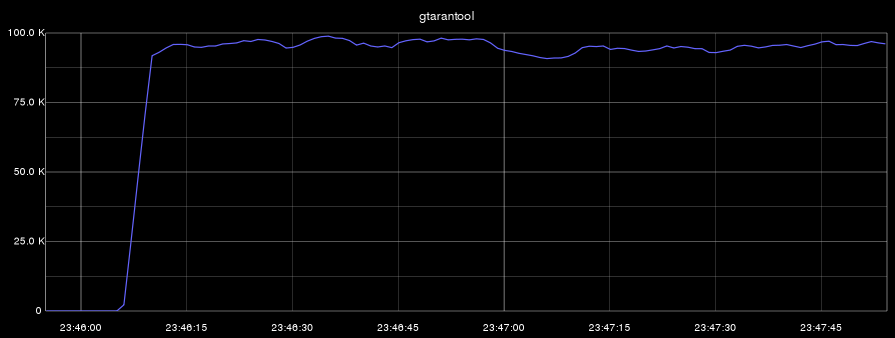
- gtarantool(選択のみ):
- aiotarantool(選択のみ):
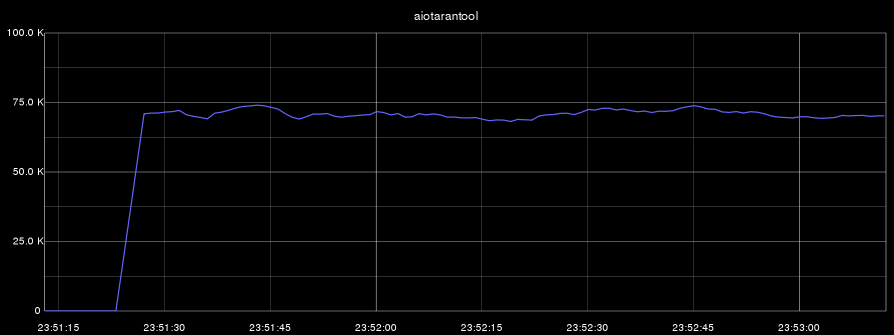
Tarantoolプロセスは1つのコアのみを使用したことを思い出させてください。 最初のベンチマークでは、CPU(このコア)の負荷は100%でした。2番目のテストでは、Tarantoolプロセスはコアを60%しか使用しませんでした。
得られた結果から、この記事で説明した手法は、プロジェクトで重い負荷を扱うのに適していると結論付けることができます。
結論
この記事の例は、もちろん人工的なものです。 これらのタスクはもう少し複雑で多様ですが、一般的な場合のソリューションは上記のコードに示されているとおりです。 このアプローチはどこに適用できますか? 「1秒間に大量の要求」が必要な場合:この場合、Tarantoolを効果的に使用するには非同期コードが必要です。 コルーチンは、イベント(システムコール)が予想される場合に効果的であり、クローラーはそのようなタスクの典型的な例です。
asyncioまたはgeventでコードを記述することは見た目ほど難しくありませんが、コードプロファイリングに多くの注意を払う必要があります。非同期コードは期待どおりに動作しないことがよくあります。
Tarantoolとそのプロトコルは、非同期開発スタイルでの作業に非常に適しています。 TarantoolとLuaの世界に突入するだけで、その強力な能力に際限なく驚くことができます。 PythonコードはTarantoolで効果的に機能し、Python 3はasyncioコルーチンで開発する可能性があります。
この記事の内容がコミュニティに利益をもたらし、Tarantoolと非同期プログラミングに関する知識ベースに追加されることを願っています。 私はasyncioとaiotarantoolが本番環境と私たちのプロジェクトで使用されるようになると思います。そして、Habrの読者と共有する何かがあるでしょう。
記事を書くときに使用されたリンク:
- tarantool.org
- habrahabr.ru/company/mailru/blog/252065-Tarantool 1.6の一人称
- habrahabr.ru/post/254533-Tarantool 1.6-さあ始めましょう
- emptysqua.re/blog/greenletprofiler-geventのプロファイラー
- code.google.com/p/yappi-別のプロファイラー
- habrahabr.ru/company/mailru/blog/202832-Pythonコードのプロファイリングに関する記事
- docs.python.org/3/library/asyncio.html-asyncioのドキュメント
- asyncio.org-既製ライブラリの例
- www.gevent.org -gevent
そして、もちろん、Tarantoolのコネクタのバージョン:
あなたのビジネスでそれらを試してみましょう!