ランダムプロセス
ランダムプロセス f(t)は、少し簡略化して、時間に依存するランダム変数です。 一定期間Tのf(t)の値のセットは、ランダムプロセスの実装または選択と呼ばれます。 たとえば、1日あたりのページビュー数は、離散的なランダムプロセス(またはランダムシーケンス)の例です。そのため、引数(時間)と値の範囲の両方、つまり f(t)の可能な値は離散量です。 したがって、ランダムプロセスのサンプルはベクトルf(t i )になります。 ランダムプロセスの2つのサンプルの例をグラフに示します(私のブログのすべてと同様に、計算はMathcad Expressを使用して準備されたので、 ここで取得できます )。
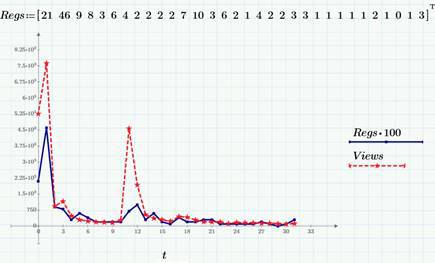
例として、2015年3月のHabréに関するこのブログのビュー(ビュー行、赤い点線)とクリック(Regs、係数100)のデータを引き続き使用します。 特に、2番目の記事では、Habrの各記事のリリース後数日で、ビューとクリックの数がほぼ一定のレベルである100〜200ビューと1日あたり1〜3クリックに達することがわかりました。 短期間の非定常性の後、ランダムなプロセスは定常的であると考えることができます(もちろん、弱い減少傾向と曜日依存の修正を無視します。これについては、トレンド除去を行うときに将来の記事で話したいと思います)。 次のグラフは、ビュー数の定常的な「テール」です(2015年3月末)。
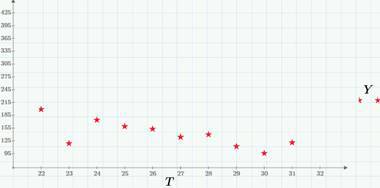
すでに見てきたように、ランダムなプロセスは、引数と値の性質(離散的または連続的)によって分類できます。 4つの組み合わせが可能であることは容易に理解できます(詳細については、Tikhonovの著書「Statistical Radio Engineering」を参照してください)。 連続時間を使用した離散プロセスの例は、ある時点(たとえば、記事が公開された瞬間から)で開始される、サイトの表示(またはサイトのクリック)の回数です。 次のグラフは、そのようなプロセスの実装の例を示しています-1日(2015年3月22日)のクリック数です。

最新のグラフを見ることで、ビュー/クリックモデルについて何が言えるでしょうか? 明らかに、ランダムに発生する可能性のある2つのランダムイベントシーケンス(イベントA-ビューとイベントB-リンクをクリック)があります。 したがって、ランダムプロセスb(t)(その実装は前のグラフに示されています)は、3月22日の午前0時から時刻tまでのクリック数として定義されます。
任意の期間(たとえば、1時間または1日)で、イベント(AまたはB)が発生する確率は、この期間の持続時間のみに依存すると仮定することは論理的です(このプロパティは、時間内のランダムプロセスの均一性と呼ばれます)。 たとえば、1時間で記事のビューが約6回ある場合、1日で約6 * 24〜140回になります。 または、1日あたり平均2回のクリックが発生する場合、1時間あたりの平均クリック数は1/12であると条件付きで言うことができます。 ヒストグラムは、「尾」に対応するビューの数の変化を示しています。 選択した平均値は、λ= 140ビューとλ2= 1.2クリック(1日あたり)です。
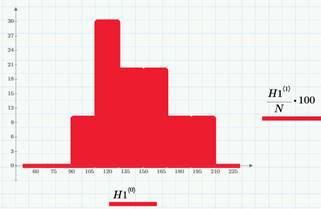
ここでいくつかの予約をすることが重要です。 まず、このアプローチは純粋に確率論的です。 1日あたりの正確なクリック数も、クリックが発生する瞬間も事前にはわかりません。 第二に、私たちはまだ状況について何かを知っています。約140人が1日に記事を開き、そのうちの1〜3人が記事の特定の場所をクリックします。 第三に、もちろん、毎日の傾向がデータに存在します(記事が夜よりもずっと読まれる日中)。 簡単にするため(および当面-トレンド除去を開始するとき)、それも無視します。 そして、4番目に(注意!)、イベントAとBの確率が何に等しいか(ビューとクリック)について説明します。
ポアソンのイベントストリーム
ランダムポアソンプロセスまたはイベントのポアソンストリームと呼ばれるモデルによって定式化された確率の理論から知られているように、ビューとクリックだけでなく、膨大な数の他の現実の現象:電話の呼び出し、機器の故障(間もなくこれに関する別の記事があります)、リクエストサービス用など 右側でサンプル関数を連続的に考慮することに同意した場合、上の対応する図に示すように、整数になり、整数ジャンプのみが増加します。 したがって、クリック数とビュー数の確率密度は、図に示すように離散的です(クリックの場合、赤い「棒」の形の行)。
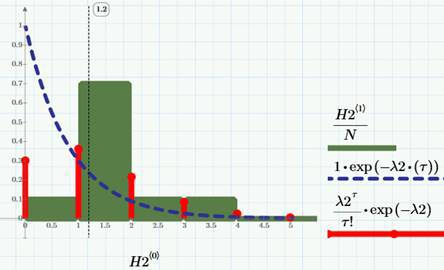
同じ図で、「列」(明確ですが、離散プロセスについて話しているため少し間違っています)は、クリック数による分布の対応するヒストグラムを示していますが、破線曲線の意味については後で説明します。 ポアソン確率密度の式は、グラフ(「スティック」の凡例)に示されています。 したがって-注意! -クリック数λ2= 1.2(1日あたりのクリック数)のサンプル平均値を計算することにより、予測のためのツールを取得し、コンバージョンデータ(前の記事を参照)と併せて、特定の目標を達成するために必要な訪問数を計算するためのアルゴリズムを取得しますクリック。
ポアソン過程を特徴付けるもう1つの重要な量は、最初のイベントτの待機時間です。 明らかに、 τは確率変数です。 確率理論から、その分布関数は指数関数であり、式F(t)= P( τ <t)= 1-exp(-λt)で与えられることが知られています。 したがって、クリック(またはビュー)がまだ発生していないイベントは、分布関数によって特徴付けられます
1-F(t)= exp(-λt)。 わかりやすくするために、この分布関数をグラフに描画し、時間単位(1日ではない)として時間を選択します。 青いP(t)曲線はビューを示し、赤はクリックを示します。
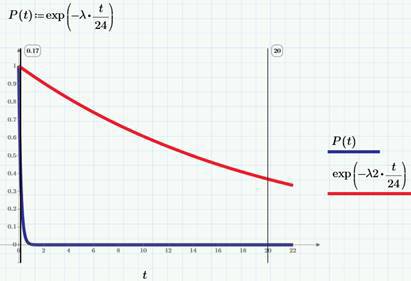
したがって、待機時間の確率密度は次のように記述されます。

分布密度と確率変数の確率密度との関係を思い出させるために、ビュー数の分布密度は関数p(t)で示されました。
最初のクリックを待つ時間の平均値は1 /λ2であり、それぞれ1 /λであると計算するのは簡単です。これは、単位時間あたりに発生し、最初のイベントを待つ平均時間に等しいイベントの平均数として、パラメーターλの単純な確率的感覚のアイデアを与えます。
参照:
- Pytiev Yu.P.、Shishmarev I.A.
物理学者のための確率論と数学統計学のコース。 M。:モスクワ州立大学、1983 - ティホノフV.I. 統計無線工学M:「ソビエト無線」、1966
- D.V. キリャノフ、E.N。 キリャノワ。 計算物理学。 M:Polybook Multimedia、2005。§5。 ランダムなプロセスとフィールド