
続けて、最初の部分はこちらです。
クラスター
それでは、クラスタを管理するソフトウェアのセットアップを始めましょう。
このPacemaker + Corosyncをノード間の通信のトランスポートバックエンドとして使用します。
Corosyncは、信頼性を高めるために、複数の通信リングでの操作をサポートしています。
さらに、3つ以上はプルされなくなりましたが、ドックはどこにもこれについて特に言及していませんが、構成で2つ以上を指定した場合にのみ起動時に誓います。
リングは、ノード間の通信がリングで行われるため、そのように名前が付けられます。ノードは互いにデータを順番に送信し、同時に互いの生存性をチェックします。 UDP上で動作し、マルチキャストと一意性の両方が可能です。 最後の1つがあります。その理由は以下のとおりです。
指輪
ノード間の通信には、やや偏執的なスキームを使用することにしました-スイッチを通る外側のリング(ここでは2つのスイッチの標準的なボンディング/イーサチャネル)+ノードを直接接続する内側のリング(3つあります-2つのストレージ+監視)
スキームは次のとおりです。

緑のネクタイは内側のリングで、黒いネクタイは外側のリングです。 このトポロジでは、外部デバイスの完全な障害が発生しても、ノードは一貫性を維持する必要があります(嵐はスイッチによって発生し、管理者(つまり、私)は曲がった手で何かを台無しにしました...可能性は低いですが、可能です)。
しかし、プラグがありました-内側のリング上のノード間でデータの無料交換を整理する方法は? しかし、これはまさにリングのトポロジーであり、イーサネットではあまり一般的ではありません。 リングを形成する3つのリンクのいずれかが切断された場合、2つのノード間の接続を維持する必要があります。
次のオプションが検討されました。
- 通常のイーサネットブリッジ+ループブレーク用のSTP。 STPタイマーを調整する場合、5〜6秒で収束を達成できます。
私たちにとってそれは永遠であり、機能しません。
- カーネルHSRプロトコルに比較的最近追加されました。 要するに、リングおよびメッシュトポロジのフェールオーバー通信で、瞬時に収束するように考案されました。 2つのインターフェイスは、追加のヘッダーとともに、一種のブリッジとパケットに結合され、両方のインターフェイスに同時に送られます。 弊社宛ではない着信パッケージは、リングに沿ってさらに転送されます。 クリッピングループの場合、パケットヘッダーの識別子が使用されます(つまり、その精神で既に転送されたものは破棄されます)。
それは美しくておいしいように見えますが、実装は不十分です。最後の安定したカーネル3.18でも、HSRデバイスが削除されると、このカーネル自体が落ちます(すでにGITで修正されています)。
しかし、それを削除しなかったとしても(奇妙なことに、リングの周りでiperfを実行して速度を測定することはできませんでした(公称速度の約50%になります))。
一般に、掃引も行います。
- OSPF L2接続はCorosyncにとって重要ではないことを考慮すると、これが最適なオプションであることが判明しました。 収束時間は約100ミリ秒であり、私たちに完全に適合しています。
クアッガ
OSPFを実装するには、Quagguを使用します。 チェコの隣人のBIRDプロジェクトもありますが、私はQuaggaにもっと精通しています。 BIRDは、いくつかのテストによると、より高速に動作し、メモリを消費しませんが、実際には、一般的にはドラムによるものです。
ホスト間の各リンクは、個別の24ネットワークになります。 はい、/ 30または/ 31を使用できますが、これらのネットワークはどこにもルーティングされないため、節約する意味はあまりありませんでした。
各ホストで、近隣へのアナウンス用にIPアドレス/ 32のダミーインターフェイスを作成します。Corosyncはそれらを介して通信します。 このアドレスをループバックに掛けることはできましたが、これらの目的のための別のインターフェースがより適切であるように思われました。
/ etc / network / interfacesのサンプルチャンク:
ストレージ1
# To Storage-2 auto int1 iface int1 inet static address 192.168.160.74 netmask 255.255.255.0 # To Witness auto ext2 iface ext2 inet static address 192.168.161.74 netmask 255.255.255.0 # Dummy loopback auto dummy0 iface dummy0 inet static address 192.168.163.74 netmask 255.255.255.255
ストレージ2
# To Storage-1 auto int1 iface int1 inet static address 192.168.160.75 netmask 255.255.255.0 # To Witness auto ext2 iface ext2 inet static address 192.168.162.75 netmask 255.255.255.0 # Dummy loopback auto dummy0 iface dummy0 inet static address 192.168.163.75 netmask 255.255.255.255
証人
ここで、ネットワークインターフェース(intN、extN)の名前を、組み込みか外部アダプター+そのポートのシリアル番号かという原則に基づいて命名すると、より便利です。
# To Storage-1 auto int2 iface int2 inet static address 192.168.161.76 netmask 255.255.255.0 # To Storage-2 auto ext2 iface ext2 inet static address 192.168.162.76 netmask 255.255.255.0 # Dummy loopback auto dummy0 iface dummy0 inet static address 192.168.163.76 netmask 255.255.255.255
次に、OSPFを構成します。
/etc/quagga/ospfd.conf :
ストレージ1
hostname storage1 interface int1 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3 interface ext2 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3 router ospf log-adjacency-changes network 192.168.160.0/24 area 0 network 192.168.161.0/24 area 0 network 192.168.163.74/32 area 0 passive-interface dummy0 timers throttle spf 10 10 100
ストレージ2
hostname storage2 interface int1 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3 interface ext2 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3 router ospf log-adjacency-changes network 192.168.160.0/24 area 0 network 192.168.162.0/24 area 0 network 192.168.163.75/32 area 0 passive-interface dummy0 timers throttle spf 10 10 100
証人
hostname witness interface int2 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3 interface ext2 ip ospf dead-interval minimal hello-multiplier 10 ip ospf retransmit-interval 3 router ospf log-adjacency-changes network 192.168.161.0/24 area 0 network 192.168.162.0/24 area 0 network 192.168.163.76/32 area 0 passive-interface dummy0 timers throttle spf 10 10 100
ホストでnet.ipv4.ip_forwardをオンにし、 quaggaを実行し、0.01秒の間隔でpingを実行して、リングを切断します。
root@witness:/# ping -i 0.01 -f 192.168.163.74 ... root@storage1:/# ip link set ext2 down root@witness:/# --- 192.168.163.74 ping statistics --- 2212 packets transmitted, 2202 received, 0% packet loss, time 26531ms rtt min/avg/max/mdev = 0.067/0.126/0.246/0.045 ms, ipg/ewma 11.999/0.183 ms
合計で10パケットが失われました。これは約100ミリ秒です。OSPFはルートを非常に迅速に変更しました。
コロシンク
ネットワークサブシステムの準備ができたので、操作のためにCorosyncを構成します。
すべてのホストの設定はほぼ同一である必要があり、内部リングのインターフェイスのアドレスdummy0のみが変更されます。
/etc/corosync/corosync.conf
compatibility: none totem { version: 2 # cluster_name: storage # authkey, . . secauth: on # heartbeat_failures_allowed: 3 threads: 6 # - . . rrp_mode: active # - , OSPF . transport: udpu # , interface { member { memberaddr: 10.1.195.74 } member { memberaddr: 10.1.195.75 } member { memberaddr: 10.1.195.76 } ringnumber: 0 # , bindnetaddr: 10.1.195.0 # . . (mcastport-1) . mcastport: 6405 } # interface { member { memberaddr: 192.168.163.74 } member { memberaddr: 192.168.163.75 } member { memberaddr: 192.168.163.76 } ringnumber: 1 # dummy0 bindnetaddr: 192.168.163.76 mcastport: 5405 } } # amf { mode: disabled } service { ver: 1 name: pacemaker } aisexec { user: root group: root } logging { syslog_priority: warning fileline: off to_stderr: yes to_logfile: no to_syslog: yes syslog_facility: daemon debug: off timestamp: on logger_subsys { subsys: AMF debug: off tags: enter|leave|trace1|trace2|trace3|trace4|trace6 } }
その後、Corosyncを起動して、サーバー上のリングのステータスと、Corosyncが結合するノードのリストを確認します。
root@storage1:/# corosync-cfgtool -s Printing ring status. Local node ID 1254293770 RING ID 0 id = 10.1.195.74 status = ring 0 active with no faults RING ID 1 id = 192.168.163.74 status = ring 1 active with no faults root@storage1:/# corosync-objctl | grep member totem.interface.member.memberaddr=10.1.195.74 totem.interface.member.memberaddr=10.1.195.75 totem.interface.member.memberaddr=10.1.195.76 totem.interface.member.memberaddr=192.168.163.74 totem.interface.member.memberaddr=192.168.163.75 totem.interface.member.memberaddr=192.168.163.76 runtime.totem.pg.mrp.srp.members.1254293770.ip=r(0) ip(10.1.195.74) r(1) ip(192.168.163.74) runtime.totem.pg.mrp.srp.members.1254293770.join_count=1 runtime.totem.pg.mrp.srp.members.1254293770.status=joined runtime.totem.pg.mrp.srp.members.1271070986.ip=r(0) ip(10.1.195.75) r(1) ip(192.168.163.75) runtime.totem.pg.mrp.srp.members.1271070986.join_count=2 runtime.totem.pg.mrp.srp.members.1271070986.status=joined runtime.totem.pg.mrp.srp.members.1287848202.ip=r(0) ip(10.1.195.76) r(1) ip(192.168.163.76) runtime.totem.pg.mrp.srp.members.1287848202.join_count=1 runtime.totem.pg.mrp.srp.members.1287848202.status=joined
ええ、うまくいきます。
ペースメーカー
クラスターのバックエンドが機能するようになったので、構成を開始できます。
各メモでPacemakerを起動し、それらのいずれかでクラスターステータスを確認します。
root@storage1:/# crm status ============ Last updated: Tue Mar 24 09:39:28 2015 Last change: Mon Mar 23 11:40:13 2015 via crmd on witness Stack: openais Current DC: witness - partition with quorum Version: 1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff 3 Nodes configured, 3 expected votes 0 Resources configured. ============ Online: [ storage1 storage2 witness ]
すべてのノードが表示されているため、構成を開始できます。
crm configure editを開始し 、デフォルトのエディター(nano)が開き、ここにそのような異端をもたらします:
クラスター構成
node storage1 node storage2 node witness # STONITH (Shoot The Other Node In The Head) . # , , IPMI RESET primitive ipmi_storage1 stonith:external/ipmi \ params hostname="storage1" ipaddr="10.1.1.74" userid="stonith" passwd="xxx" interface="lanplus" \ pcmk_host_check="static-list" pcmk_host_list="storage1" primitive ipmi_storage2 stonith:external/ipmi \ params hostname="storage2" ipaddr="10.1.1.75" userid="stonith" passwd="xxx" interface="lanplus" \ pcmk_host_check="static-list" pcmk_host_list="storage2" # ALUA, /etc/scst.conf primitive p_scst ocf:esos:scst \ params alua="true" device_group="default" \ local_tgt_grp="local" \ remote_tgt_grp="remote" \ m_alua_state="active" \ s_alua_state="nonoptimized" \ op monitor interval="10" role="Master" \ op monitor interval="20" role="Slave" \ op start interval="0" timeout="120" \ op stop interval="0" timeout="60" # Master-Slave ms ms_scst p_scst \ meta master-max="1" master-node-max="1" clone-max="2" clone-node-max="1" notify="true" interleave="true" \ target-role="Master" # storage1 Master- location prefer_ms_scst ms_scst inf: #uname eq storage1 # SCST witness location dont_run ms_scst -inf: #uname eq witness # STONITH , . C - ! location loc_ipmi_on_storage1 ipmi_storage1 -inf: #uname eq storage1 location loc_ipmi_on_storage2 ipmi_storage2 -inf: #uname eq storage2 property $id="cib-bootstrap-options" \ dc-version="1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff" \ cluster-infrastructure="openais" \ expected-quorum-votes="3" \ stonith-enabled="true" \ last-lrm-refresh="1427100013"
保存、適用(コミット)。
IPMIサーバーのSTONITHの場合、管理者権限を持つユーザーを作成する必要があります。作成しない場合、リソースは接続を拒否します。 原則として、Operatorで十分ですが、リソースコードを選択する必要はありませんでした。
クラスターの状態を確認します。
root@storage1:/# crm status ============ Last updated: Wed Mar 25 15:48:29 2015 Last change: Mon Mar 23 11:40:13 2015 via crmd on witness Stack: openais Current DC: witness - partition with quorum Version: 1.1.7-ee0730e13d124c3d58f00016c3376a1de5323cff 3 Nodes configured, 3 expected votes 4 Resources configured. ============ Online: [ storage1 storage2 witness ] Master/Slave Set: ms_scst [p_scst] Masters: [ storage1 ] Slaves: [ storage2 ] ipmi_storage1 (stonith:external/ipmi): Started witness ipmi_storage2 (stonith:external/ipmi): Started storage1
まあ、すべてが美しいようです。 原則として、イニシエーターから既に接続できます。
確かに、STONITHの動作を確認します。
: root@storage2:/# ip link set bond_hb_ext down ... . root@storage2:/# ip link set int1 down ... . : root@storage2:/# ip link set ext2 down ... :) .
マスター-スレーブリソースの操作に関する小さなメモ :Pacemakerには、リソースが現在マスターおよびスレーブで動作しているノードの場所を強制的に変更するチームはありません。 demoteコマンドを使用して、両方のノードのスレーブにリソースを転送できます。
2つのソリューション:
1)クラスター構成を編集し、マスターモードの優先ノードを別のノードに変更してコミットします。しばらくすると、クラスターはリソース自体の移動に取り組みます。
2)作業リソースが1つしかないため、実際にはマスターノードでPacemakerを単純に消すことができます:)これにより、2番目のノードにマスターモードに移行するように通知されます。 その後、以前のマスターノードを再起動して、アレイの所有権が別のノードに移るようにします。
予定された停止の場合、PacemakerおよびCorosync STONITHは機能しません 。
最後の仕上げ
- サーバーがフリーズし、STONITHが何らかの理由でそれを強制終了できない場合に備えて、すべてのサーバーで/ dev / watchdogを介してIPMIで動作するWatchdogデーモンをインストールします。
/etc/watchdog.conf:
watchdog-device = /dev/watchdog admin = root interval = 1 realtime = yes priority = 1
- /etc/sysctl.confのパラメーターを設定します。
これは、理解できない(およびOOPSおよびあらゆる種類のNMIが悪い)状況のカーネルがサーバーをリセットし、2番目のノードが完全に業務を開始できるようにするために必要です。 カーネルがさらに多かれ少なかれ生きていれば、この機能はWatchdogやSTONITHよりも速く動作するはずです。kernel.panic = 1 kernel.panic_on_io_nmi = 1 kernel.panic_on_oops = 1 kernel.panic_on_unrecovered_nmi = 1 kernel.unknown_nmi_panic = 1
- /etc/quagga/debian.confのwatchquaggaを設定して、Quaggaデーモンがクラッシュした場合に再起動します。
watchquagga_enable=yes watchquagga_options=(--daemon --unresponsive-restart -i 5 -t 5 -T 5 --restart-all '/etc/init.d/quagga restart')
- 問題が発生した場合に、NetConsoleを構成して、Witnessノード上のストレージサーバーからカーネルログを直接収集します。
/ etc / fstabに追加:
さらに、構成する小さなスクリプト:none /sys/kernel/config configfs defaults 0 0
netconsole.pl#!/usr/bin/perl -w use strict; use warnings; my $dir = '/sys/kernel/config/netconsole'; my %tgts = ( 'tgt1' => { 'dev_name' => 'ext2', 'local_ip' => '192.168.161.74', 'remote_ip' => '192.168.161.76', 'remote_mac' => '00:25:90:77:b8:8b', 'remote_port' => '6666' } ); foreach my $tgt (sort keys %tgts) { my $t = $tgts{$tgt}; my $tgtdir = $dir."/".$tgt; mkdir($tgtdir); foreach my $k (sort keys $t) { system("echo '".$t->{$k}."' > ".$tgtdir."/".$k); } system("echo 1 > ".$tgtdir."/enabled"); }
ESXi
ストレージクラスターをアクティブ化すると、LUNがイニシエーターに既に表示されます。

ここに表示されます(FCポートの1つ):
- 2つのデバイス、それぞれに4つのパス(メインストレージに2つ、バックアップに2つ)
- ハードウェアアクセラレーション=サポートとは、ストレージがVAAIプリミティブ(SCSIコマンドATS、XCOPY、WRITE SAME)をサポートすることを意味します。これにより、ホストからストレージへの操作のオフライン部分(ブロッキング、クローニング、ゼロでの詰まり)が可能になります
- SSD:ホストがこれらのLUNをホストキャッシュやSSDを必要とする他のサービスに使用できるようにします
ストレージへの複数のパスを完全に使用するには、次の2つが必要です。
- ラウンドロビンモードを設定する
- 1 IOごとにパスを変更するように設定します。 デフォルトでは、1000回のI / O操作ごとにパスを変更しますが、これは完全には最適ではありませんが、ホストCPUに多少の負担をかけます。 EMCからの優れた記事があり、パフォーマンスに対するこのパラメーターの影響が詳細に研究されています。
また、vSphere Clientから最初の項目を作成できる場合、コンソールから2番目の項目を作成する必要があります。 これを行うには、ホストでSSHをアクティブにし、それぞれにログインして、次を入力します。
Round Robin (, GUI): # for i in `ls /vmfs/devices/disks/ | grep "eui" | grep -v ":"`; do esxcli storage nmp device set --psp=VMW_PSP_RR --device=$i; done IOPS : # for i in `ls /vmfs/devices/disks/ | grep "eui" | grep -v ":"`; do esxcli storage nmp psp roundrobin deviceconfig set --type=iops --iops=1 --device=$i; done : # for i in `ls /vmfs/devices/disks/ | grep "eui" | grep -v ":"`; do esxcli storage nmp psp roundrobin deviceconfig get --device=$i | grep IOOperation; done IOOperation Limit: 1 IOOperation Limit: 1
素晴らしい。 次に、操作の結果を確認します。
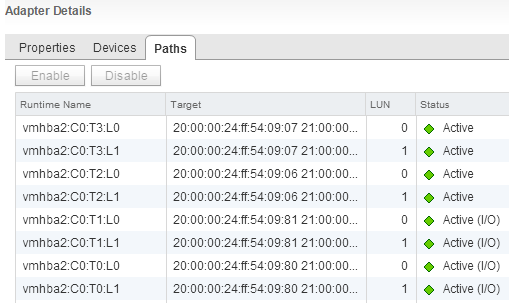
これは、FCアダプターのポートの1つを通るストレージのビューであり、2番目のポートはすべてまったく同じです。
さて、各LUNへの2つのアクティブパスと2つのバックアップパスがあります。
次に、各LUNにVMFSを作成し、それらに1つのDebian仮想マシンを配置します(ディスクは、ESXiが未使用ブロックの読み取り速度でチートしないように、Thick Provision Eager Zeroedです)。作業速度とバックアップストレージへの切り替えプロセスをテストします。
各VMにfioをインストールし、テストパラメーターを使用してread.fio ファイルを作成します。
[test] blocksize=512 filename=/dev/sda size=128G rw=randread direct=1 buffered=0 ioengine=libaio iodepth=64
つまり、128 GB(VMにはそのようなディスクがあります)を読み取るまで、キューの深さ64で512バイトのブロックでランダムに読み取りを行います。
私たちは見ます:


1つのVMでテストするとFioの結果:
フィオランダム
test: (g=0): rw=randread, bs=512-512/512-512, ioengine=libaio, iodepth=64 2.0.8 Starting 1 process Jobs: 1 (f=1): [r] [100.0% done] [77563K/0K /s] [155K/0 iops] [eta 00m:00s] test: (groupid=0, jobs=1): err= 0: pid=3100 read : io=131072MB, bw=75026KB/s, iops=150052 , runt=1788945msec slat (usec): min=0 , max=554 , avg= 2.92, stdev= 1.94 clat (usec): min=127 , max=1354.3K, avg=420.90, stdev=1247.77 lat (usec): min=130 , max=1354.3K, avg=424.51, stdev=1247.77 clat percentiles (usec): | 1.00th=[ 350], 5.00th=[ 378], 10.00th=[ 386], 20.00th=[ 398], | 30.00th=[ 406], 40.00th=[ 414], 50.00th=[ 418], 60.00th=[ 426], | 70.00th=[ 430], 80.00th=[ 438], 90.00th=[ 450], 95.00th=[ 462], | 99.00th=[ 494], 99.50th=[ 516], 99.90th=[ 636], 99.95th=[ 732], | 99.99th=[ 3696] bw (KB/s) : min= 606, max=77976, per=100.00%, avg=75175.70, stdev=3104.46 lat (usec) : 250=0.02%, 500=99.19%, 750=0.75%, 1000=0.03% lat (msec) : 2=0.01%, 4=0.01%, 10=0.01%, 20=0.01%, 250=0.01% lat (msec) : 500=0.01%, 750=0.01%, 1000=0.01%, 2000=0.01% cpu : usr=62.25%, sys=37.18%, ctx=58816, majf=0, minf=14 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0% issued : total=r=268435456/w=0/d=0, short=r=0/w=0/d=0 Run status group 0 (all jobs): READ: io=131072MB, aggrb=75026KB/s, minb=75026KB/s, maxb=75026KB/s, mint=1788945msec, maxt=1788945msec Disk stats (read/write): sda: ios=268419759/40, merge=0/2, ticks=62791530/0, in_queue=62785360, util=100.00%
フィオシーケンシャル
test: (g=0): rw=read, bs=1M-1M/1M-1M, ioengine=libaio, iodepth=64 2.0.8 Starting 1 process Jobs: 1 (f=1): [R] [100.0% done] [1572M/0K /s] [1572 /0 iops] [eta 00m:00s] test: (groupid=0, jobs=1): err= 0: pid=3280 read : io=131072MB, bw=1378.6MB/s, iops=1378 , runt= 95078msec slat (usec): min=36 , max=2945 , avg=80.13, stdev=16.73 clat (msec): min=11 , max=1495 , avg=46.33, stdev=29.87 lat (msec): min=11 , max=1495 , avg=46.42, stdev=29.87 clat percentiles (msec): | 1.00th=[ 35], 5.00th=[ 38], 10.00th=[ 39], 20.00th=[ 40], | 30.00th=[ 42], 40.00th=[ 43], 50.00th=[ 43], 60.00th=[ 44], | 70.00th=[ 52], 80.00th=[ 56], 90.00th=[ 57], 95.00th=[ 57], | 99.00th=[ 59], 99.50th=[ 62], 99.90th=[ 70], 99.95th=[ 529], | 99.99th=[ 1483] bw (MB/s) : min= 69, max= 1628, per=100.00%, avg=1420.43, stdev=219.51 lat (msec) : 20=0.04%, 50=68.57%, 100=31.33%, 750=0.02%, 2000=0.05% cpu : usr=0.57%, sys=13.40%, ctx=16171, majf=0, minf=550 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.1%, >=64=0.0% issued : total=r=131072/w=0/d=0, short=r=0/w=0/d=0 Run status group 0 (all jobs): READ: io=131072MB, aggrb=1378.6MB/s, minb=1378.6MB/s, maxb=1378.6MB/s, mint=95078msec, maxt=95078msec Disk stats (read/write): sda: ios=261725/14, merge=0/1, ticks=11798940/350, in_queue=11800870, util=99.95%
ハイライト:
- >合計300k IOPS。 テスト中にバックエンドが暗号化されたことを考えると、かなり良い
- 線形速度は1300〜1580 MB / s(2x8Gbit FCの制限に近い)内で変動します。ここでは暗号化速度によって制限されます
- リクエストの99.9%のランダムレイテンシは0.7msを超えません
- VMの1つでのテストが停止した場合、残りのVMのIOPSは同じままです。 これは、ESXiのデュアルポートFCカードの制限のようです。 これはやや奇妙ですが、チューニングを行う必要があります
- テスト中、ストレージCPUの負荷は約60%であるため、まだマージンがあります
または多分前髪? 強打してください
次に、システムがマスターノードの切断にどのように応答するかを確認します。
スケジュール済み :Pacemakerマスターノードで停止します。 ほぼ瞬時に、クラスターは2番目のノードをマスターモードに切り替えます。
[285401.041046] scst: Changed ALUA state of default/local into active [285401.086053] scst: Changed ALUA state of default/remote into nonoptimized
そして最初は、SCSTを順次無効にし、それに関連するすべてのモジュールをカーネルからアンロードします。
dmesg
[286491.713124] scst: Changed ALUA state of default/local into nonoptimized [286491.757573] scst: Changed ALUA state of default/remote into active [286491.794939] qla2x00t: Unloading QLogic Fibre Channel HBA Driver target mode addon driver [286491.795022] qla2x00t(0): session for loop_id 132 deleted [286491.795061] qla2x00t(0): session for loop_id 131 deleted [286491.795096] qla2x00t(0): session for loop_id 130 deleted [286491.795172] qla2xxx 0000:02:00.0: Performing ISP abort - ha= ffff880854e28550. [286492.428672] qla2xxx 0000:02:00.0: LIP reset occured (f7f7). [286492.488757] qla2xxx 0000:02:00.0: LOOP UP detected (8 Gbps). [286493.810720] scst: Waiting for 4 active commands to complete... This might take few minutes for disks or few hours for tapes, if you use long executed commands, like REWIND or FORMAT. In case, if you have a hung user space device (ie made using scst_user module) not responding to any commands, if might take virtually forever until the corresponding user space program recovers and starts responding or gets killed. [286493.810924] scst: All active commands completed [286493.810997] scst: Target 21:00:00:24:ff:54:09:80 for template qla2x00t unregistered successfully [286493.811072] qla2x00t(1): session for loop_id 0 deleted [286493.811111] qla2x00t(1): session for loop_id 1 deleted [286493.811146] qla2x00t(1): session for loop_id 2 deleted [286493.811182] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811226] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811266] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811305] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811345] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811384] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811424] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811463] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811502] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811541] qla2x00t(1): Unable to send command to SCST, sending BUSY status [286493.811672] qla2xxx 0000:02:00.1: Performing ISP abort - ha= ffff880854e08550. [286494.441653] qla2xxx 0000:02:00.1: LIP reset occured (f7f7). [286494.481727] qla2xxx 0000:02:00.1: LOOP UP detected (8 Gbps). [286495.833746] scst: Target 21:00:00:24:ff:54:09:81 for template qla2x00t unregistered successfully [286495.833828] qla2x00t(2): session for loop_id 132 deleted [286495.833866] qla2x00t(2): session for loop_id 131 deleted [286495.833902] qla2x00t(2): session for loop_id 130 deleted [286495.833991] qla2xxx 0000:03:00.0: Performing ISP abort - ha= ffff88084f310550. [286496.474662] qla2xxx 0000:03:00.0: LIP reset occured (f7f7). [286496.534750] qla2xxx 0000:03:00.0: LOOP UP detected (8 Gbps). [286497.856734] scst: Target 21:00:00:24:ff:54:09:32 for template qla2x00t unregistered successfully [286497.856815] qla2x00t(3): session for loop_id 0 deleted [286497.856852] qla2x00t(3): session for loop_id 1 deleted [286497.856888] qla2x00t(3): session for loop_id 130 deleted [286497.856926] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.856970] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857009] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857048] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857087] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857127] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857166] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857205] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857244] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857284] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857323] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857362] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857401] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857440] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857480] qla2x00t(3): Unable to send command to SCST, sending BUSY status [286497.857594] qla2xxx 0000:03:00.1: Performing ISP abort - ha= ffff88084dfc0550. [286498.487642] qla2xxx 0000:03:00.1: LIP reset occured (f7f7). [286498.547731] qla2xxx 0000:03:00.1: LOOP UP detected (8 Gbps). [286499.889733] scst: Target 21:00:00:24:ff:54:09:33 for template qla2x00t unregistered successfully [286499.889799] scst: Target template qla2x00t unregistered successfully [286499.890642] dev_vdisk: Detached virtual device SSD-RAID6-1 ("/dev/disk/by-id/scsi-3600605b008b4be401c91ac4abce21c9b") [286499.890718] scst: Detached from virtual device SSD-RAID6-1 (id 1) [286499.890756] dev_vdisk: Virtual device SSD-RAID6-1 unregistered [286499.890798] dev_vdisk: Detached virtual device SSD-RAID6-2 ("/dev/disk/by-id/scsi-3600605b008b4be401c91ac53bd668eda") [286499.890869] scst: Detached from virtual device SSD-RAID6-2 (id 2) [286499.890906] dev_vdisk: Virtual device SSD-RAID6-2 unregistered [286499.890945] scst: Device handler "vdisk_nullio" unloaded [286499.890981] scst: Device handler "vdisk_blockio" unloaded [286499.891017] scst: Device handler "vdisk_fileio" unloaded [286499.891052] scst: Device handler "vcdrom" unloaded [286499.891754] scst: Task management thread PID 5162 finished [286499.891801] scst: Management thread PID 5163 finished [286499.891847] scst: Init thread PID 5161 finished [286499.899867] scst: Detached from scsi0, channel 0, id 20, lun 0, type 13 [286499.899911] scst: Detached from scsi0, channel 0, id 36, lun 0, type 13 [286499.899951] scst: Detached from scsi0, channel 0, id 37, lun 0, type 13 [286499.899992] scst: Detached from scsi0, channel 0, id 38, lun 0, type 13 [286499.900031] scst: Detached from scsi0, channel 0, id 39, lun 0, type 13 [286499.900071] scst: Detached from scsi0, channel 0, id 40, lun 0, type 13 [286499.900110] scst: Detached from scsi0, channel 0, id 41, lun 0, type 13 [286499.900150] scst: Detached from scsi0, channel 0, id 42, lun 0, type 13 [286499.900189] scst: Detached from scsi0, channel 0, id 59, lun 0, type 13 [286499.900228] scst: Detached from scsi0, channel 0, id 60, lun 0, type 13 [286499.900268] scst: Detached from scsi0, channel 2, id 0, lun 0, type 0 [286499.900307] scst: Detached from scsi0, channel 2, id 1, lun 0, type 0 [286499.900346] scst: Detached from scsi1, channel 0, id 0, lun 0, type 0 [286499.900385] scst: Detached from scsi2, channel 0, id 0, lun 0, type 0 [286499.900595] scst: Exiting SCST sysfs hierarchy... [286502.914203] scst: User interface thread PID 5153 finished [286502.914248] scst: Exiting SCST sysfs hierarchy done [286502.914458] scst: SCST unloaded
仮想マシンでは、IOが約10〜15秒間フリーズし、古いパスに沿ってしばらくの間、特定のタイムアウトが新しいパスに切り替わった後にのみ、ESXiがポークするようです。 各VMのIOPSは120kから22kに低下します-これはI / O Shippingの価格です。
次に、最初のサーバーの電源を切るか再起動します。2番目のサーバーのSyncroは主な役割を傍受し、I / Oは通常の値に戻ります。
Pacemakerを元に戻すと、クラスターはこのノードに戻ります。これは、configでそう指示されているためです:)
スケジュールなし :ここでは、たとえば、kill -9を介してcorosyncプロセスを強制終了できます。クラスターはSTONITHを介してクラッシュします。 または、電源ノードをオフにします。 結果は1で、一般に、IO Shippingがないことを除いて、計画されたものと違いはありません。2番目のコントローラーはすぐにアレイを取得し、速度は22k IOPSに低下しません。
エピローグ
背後にはまだ自己監視ノード用のスクリプトがありますが、アクティビティには大きな分野があります:あらゆる種類のStorCLIを介してコントローラーの活力をチェックする、アレイがI / O要求に応答するかどうかをチェックする(ioping)などです。 誤動作が発生した場合、ノードはハラキリを実行する必要があります。
このような簡単な方法で、即興の素材をかなり信頼性が高く高速に保管できます。
質問、提案、批判を歓迎します。
すべてビーバー!