この投稿では、これらの問題をどのように解決したかを説明します。
与えられた:
- 記事の総数140,000;
- スパム:約16%。
- 不明瞭な重複の数:約63%;
目的:スパムと重複を取り除き、それ以上の発生を防ぎます。

パート1.スパム/非スパムの分類
私のサイトのすべての記事は同じトピックに関連しており、原則として、スパマー/広告メッセージは内容がかなり異なります。 多くの記事を手動でソートすることにしました。 そしてそれらに基づいて分類器を構築します。 分類のために、チェック対象の記事のベクトルと2つのグループ(スパム/非スパム)のベクトル間のコサイン距離を考慮します。 レビュー中の記事がどのグループに近いかは、そのグループを参照します。
まず、記事を手動で分類する必要があります。 このチェックボックスフォームをスケッチして、数時間で650件のスパム記事と2,000件の非スパム記事を収集しました。
すべての投稿からゴミが取り除かれます-ペイロード(聖体拝領、間投詞など)を含まないノイズワード。 これを行うために、インターネットで見つけたさまざまな辞書、ノイズ語のボキャブラリーから収集しました。
1つの単語のさまざまな形式の数を最小限に抑えるには、 Porterのstemmmを使用できます。 ここから完成したJava実装を取りました。 エドゥノフに感謝
分類された記事の単語から、ノイズワードを取り除き、ステミングを使用して、辞書をコンパイルする必要があります。
辞書から、1つの記事のみで見つかった単語を削除します。
手動で分類された記事ごとに、辞書から各単語の出現回数をカウントします。 次のようなベクトルを取得します。

各ベクトルの単語の重みを強化し、 TF-IDFをカウントします。 TF-IDFは、スパム/非スパムグループごとに個別に考慮されます。
まず、各記事のTF(期間頻度)を考慮します。 これは、記事内の単語の総数に対する特定の単語の出現回数の比率です。

ここで、n iはドキュメント内の単語の出現数で、分母はこのドキュメント内の単語の総数です。

次に、IDF(逆文書頻度)を検討します。 グループ文書で特定の単語が出現する頻度の逆数(スパム/非スパム)。 IDFは、グループでよく使用される単語の重みを減らします。 グループごとに考慮されます。

どこで
- | D | -グループ内のドキュメントの数。
- d i⊃ti-t iが発生するドキュメントの数(n i ≠0の場合)。

TF-IDFを検討してください。
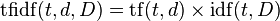
特定のドキュメント内で頻度が高く、他のドキュメントでの使用頻度が低い単語は、TF-IDFで多くの重要性が増します。
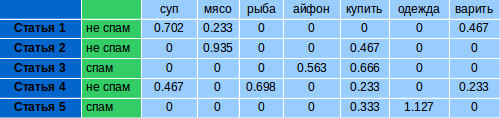
グループごとに、グループ内の各パラメーターの算術平均を考慮して、1つのベクトルを形成します。

記事のスパムをチェックするには、辞書から単語の出現回数を取得する必要があります。 スパムではなくスパムのこれらの単語TF-IDFをカウントします。 2つのベクトルを取得します(TF-IDFはスパムではなく、TF-IDFはスパムです)。 計算用のIDFは、分類サンプルで考慮されたものを使用します。

各ベクトルについて、それぞれスパムと非スパムのベクトルとのコサイン距離を考慮します。 コサイン距離は、2つのベクトルの類似性の尺度です。 ベクトルのスカラー積とそれらの間の角度θの余弦は、次の関係で関係しています。

2つのベクトルAとBを使用して、余弦距離-cos(θ)を取得します

Javaコード
public static double cosine(double[] a, double[] b) { double dotProd = 0; double sqA = 0; double sqB = 0; for (int i = 0; i < a.length; i++) { dotProd += a[i] * b[i]; sqA += a[i] * a[i]; sqB += b[i] * b[i]; } return dotProd/(Math.sqrt(sqA)*Math.sqrt(sqB)); }
結果は-1〜1の範囲です。-1は、ベクトルが完全に反対であることを意味し、1は同じです。
取得された値(スパムではなく、スパム)のどれが1に近くなり、記事をそのグループに関連付けます。
非スパムとの類似性を確認すると、結果は0.87です。

スパムの場合-0.62:

したがって、この記事はスパムではないと考えています。
テストのために、別の700レコードを手動で選択しました。 結果の精度は98%でした。 さらに、誤って分類されたものは、私にとっても、このカテゴリーまたはそのカテゴリーに帰属することは困難でした。
パート2.あいまいな重複の検索
スパムをクリアした後、118,000の記事が残りました。
重複を見つけるために、逆索引( Inverted index )を使用することにしました。 インデックスは、各単語について、どのドキュメントに含まれているかを示すデータ構造です。 したがって、単語のセットがある場合、これらの単語を含むドキュメントを簡単にリクエストできます。
Wikiの例。 次のドキュメントがあるとしましょう:
T[0] = "it is what it is" T[1] = "what is it" T[2] = "it is a banana"
これらのドキュメントについて、どのドキュメントに単語が含まれているかを示すことにより、インデックスを作成します。
"a": {2} "banana": {2} "is": {0, 1, 2} "it": {0, 1, 2} "what": {0, 1}
「what」、「is」、「it」という単語はすべてドキュメント0および1にあります。
{0,1} ∩ {0,1,2} ∩ {0,1,2} = {0,1}
MySQLデータベースにインデックスを保存しました。 インデックス作成には約2日かかりました。
同様の記事を検索するために、すべての単語が一致する必要はありません。したがって、インデックスでクエリを実行すると、少なくとも75%の一致する単語を持つすべての記事が取得されます。 見つかったものには、同様の複製が含まれているほか、元の単語の75%を含む他の記事が含まれています。たとえば、これらは非常に長い記事です。
重複していないものを取り除くには、オリジナルと見つかったものの間のコサイン距離を計算する必要があります。 75%以上一致するものは重複と見なされます。 75%の数値は経験的に導き出されました。 同じ記事のかなり修正されたバージョンを見つけることができます。
見つかった重複の例:
オプション1:
コンデンスミルク入りチーズケーキ(ベーキングなし)
成分
*脂肪分20%の450 grサワークリーム
* 300 gクッキー
*溶かしバター100 g
*良質のコンデンスミルク300グラム
*インスタントゼラチン10グラム
* 3/4カップの冷水
料理:
折りたたみフォームを羊皮紙でレイアウトします。
砕いたクッキーを溶かしたバターで小さなパン粉に混ぜます。 混合物は油性であってはなりませんが、乾燥してはいけません。 混合物を型に入れてしっかり締めます。 冷蔵庫に30分間入れます。
サワークリームと練乳を混ぜます。
3/4カップの水をゼラチンに注ぎ、10分間膨潤させます。 次に、完全に溶解するように水浴で溶かします。
コンデンスミルクとサワークリームの混合物にゼラチンを静かに注ぎ、十分に攪拌します。 次に、フォームに注ぎます。 完全に固まるまで冷蔵庫に約2〜3時間入れます。
固めたら、新鮮なクランベリーを追加するか、すりおろしたチョコレートやナッツを振りかけることができます。
いってらっしゃい!
オプション2:
コンデンスミルクで焼かないチーズケーキ
成分
20%脂肪450 gからサワークリーム
-300 grクッキー(オートミールを取りました)
-100 g溶かしバター
-300 grの高品質コンデンスミルク
-10 gインスタントゼラチン
-3/4カップの冷水
料理:
1)。 シェイプ(できれば取り外し可能)を羊皮紙で覆います。
2)。 クッキーを小さなパン粉で挽き、溶かしたバターと混ぜます。 塊は油性ではなく、乾燥しすぎてはいけません。 塊を型に入れてよくタンピングする。 半時間冷蔵します。
3)。 サワークリームとコンデンスミルクを混ぜます(コンデンスミルクは多少追加できますが、これは好みの問題です)。
4)ゼラチン3/4カップの水を注ぎ、10分間放置します。 膨らむ。 それを水浴で溶かして、完全に溶かします。
5)ゼラチンをサワークリームが凝縮した塊にゆっくりと導入し、よく攪拌します。 次に、フォームに注ぎます。 完全に固まるまで冷蔵庫に送ります。 すぐに凍りました。 約2時間。
固まるときに、新鮮なクランベリーの果実を追加しました-これは、ピリッと酸味を追加しました。 すりおろしたチョコレートまたはナッツを振りかけることができます。
コンデンスミルク入りチーズケーキ(ベーキングなし)
成分
*脂肪分20%の450 grサワークリーム
* 300 gクッキー
*溶かしバター100 g
*良質のコンデンスミルク300グラム
*インスタントゼラチン10グラム
* 3/4カップの冷水
料理:
折りたたみフォームを羊皮紙でレイアウトします。
砕いたクッキーを溶かしたバターで小さなパン粉に混ぜます。 混合物は油性であってはなりませんが、乾燥してはいけません。 混合物を型に入れてしっかり締めます。 冷蔵庫に30分間入れます。
サワークリームと練乳を混ぜます。
3/4カップの水をゼラチンに注ぎ、10分間膨潤させます。 次に、完全に溶解するように水浴で溶かします。
コンデンスミルクとサワークリームの混合物にゼラチンを静かに注ぎ、十分に攪拌します。 次に、フォームに注ぎます。 完全に固まるまで冷蔵庫に約2〜3時間入れます。
固めたら、新鮮なクランベリーを追加するか、すりおろしたチョコレートやナッツを振りかけることができます。
いってらっしゃい!
オプション2:
コンデンスミルクで焼かないチーズケーキ
成分
20%脂肪450 gからサワークリーム
-300 grクッキー(オートミールを取りました)
-100 g溶かしバター
-300 grの高品質コンデンスミルク
-10 gインスタントゼラチン
-3/4カップの冷水
料理:
1)。 シェイプ(できれば取り外し可能)を羊皮紙で覆います。
2)。 クッキーを小さなパン粉で挽き、溶かしたバターと混ぜます。 塊は油性ではなく、乾燥しすぎてはいけません。 塊を型に入れてよくタンピングする。 半時間冷蔵します。
3)。 サワークリームとコンデンスミルクを混ぜます(コンデンスミルクは多少追加できますが、これは好みの問題です)。
4)ゼラチン3/4カップの水を注ぎ、10分間放置します。 膨らむ。 それを水浴で溶かして、完全に溶かします。
5)ゼラチンをサワークリームが凝縮した塊にゆっくりと導入し、よく攪拌します。 次に、フォームに注ぎます。 完全に固まるまで冷蔵庫に送ります。 すぐに凍りました。 約2時間。
固まるときに、新鮮なクランベリーの果実を追加しました-これは、ピリッと酸味を追加しました。 すりおろしたチョコレートまたはナッツを振りかけることができます。
完全なクリーニングには約5時間かかりました。
インデックスを更新して重複を見つけるために、既存のデータを再構築する必要はありません。 インデックスは増分的に完了します。
サーバーのRAMの量が限られているため、インデックスをメモリに保持する方法がありません。そのため、記事自体が保存されているMySQLにインデックスを保持します。 メモリにすべてをロードしない場合、1つの記事をチェックすると、プログラムに約9秒かかります。 長い時間ですが、なぜなら 1日に数十件の新しい記事のみが表示されますが、これが必要になるまでスピードを気にしないことにしました。