
翻訳者注: RuxitネットワークモニタリングサービスエンジニアのAlois Mayrは、クラウドでネットワークを設定する際に新規参入者が直面する可能性のある困難について興味深い資料を作成し、それに合わせた翻訳を準備しました。
アプリケーションがAWSで実行されている場合 Amazon Web Services]またはそのようなクラウドプラットフォームのいずれか( 1cloudなど)。これは、とりわけ、ネットワークからクラウドサービスに作業を正常に「転送」したことを意味します。 当然、これは主にネットワークの物理インフラストラクチャを維持する必要がないため、非常に価値があります。 ただし、ネットワークへの直接アクセスの欠如は、ネットワークをまったく監視する必要がないという意味ではありません。
ちょっとした歴史
従来のタイプのアプリケーションアーキテクチャでは、ネットワークインフラストラクチャは専門家チームによって厳密に制御されていました。 このようなチームは、問題が発生する前に過負荷の機器を交換し、ネットワーク内の弱いリンクを特定して排除し、パフォーマンス制限の問題を解決し、データ転送中のレイテンシーパラメーターを監視し、ネットワークセキュリティの脅威を検出することも担当しました。 つまり、通常のネットワークチームは、OSIモデルの7つのレイヤーすべてをフォローしていました。
現代のアーキテクチャには、これまで以上にネットワーキングが必要です
クラウドテクノロジーを使用するアーキテクチャでは状況が異なり、現在ではネットワークの使用がはるかに大きな役割を果たしています。 クラウドサービスを使用した典型的なアーキテクチャを想像してください。 運用用に割り当てられた可変数のコンピューターでデータセンターを管理します(たとえば、価格設定メカニズムやプロセッサー要件の変更に応じて)。 データセンターは、たとえばマイクロサービスに基づいて開発された分散アプリケーションを提供します。 さらに、アプリケーションは、たとえばDockerコンテナーを使用して配布され 、チームにDevOps方法論を提供します。 開発オペレーション ]、行動の自由。 このような状況では、ネットワーキングがこれまで以上に重要になります。 ネットワークは、マイクロサービス通信に必要なすべての通信を処理する必要があります。 これは、アプリケーションの仮想「神経系」として機能します。
システム管理者はネットワークに直接アクセスできませんが、それでも動作し、注意が必要です。 サーバーが物理的に配置されている場所や、ネットワーク上の他のノードにどのように接続されているかを見つけるのは難しい場合がよくあります。 相互接続された仮想マシンとサービスは、同じ仮想ホスト上に存在することもできます。 この場合、ネットワークはメモリからのみデータを読み取ることができます。 これは、多くの場合、物理ネットワークが複数の仮想ネットワークに接続されることを意味します。
クラウドサービスを使用したネットワークでの作業の難しさ
ネットワークへの直接アクセスがないため(OSIモデルのレベル1〜2)、DevOpsの原則を遵守するチームは監視が非常に困難です。 NetworkInやNetworkOutなどのネットワークパフォーマンスインジケーターを読み取るCloud Watchなどのクラウドプロバイダーが提供する監視ツールを使用できますが、これらのインジケーターではネットワークの問題を特定するには不十分な場合があります。
以下に、DevOps手法を使用して仮想ネットワークのパフォーマンスを維持する際に発生する主な問題の一部を示します。
- 競合するプロセス間のネットワークリソースの分配(たとえば、 TCP Incastとして知られる問題)。
- 新しいオブジェクトまたは中断されたオブジェクトが存在する場合のネットワークインフラストラクチャの変更。
- ENIネットワークインターフェイスを使用したネットワークスケーラビリティ Elastic Network Interfaces ];
- データセンターの内部接続の品質。
- データセンターの外部にあるプライベートネットワークへの接続の品質。
ネットワーク使用状況の監視
ネットワークを監視する場合、上記のインフラストラクチャの変更に適応できる必要があります。 特に、仮想ネットワークインターフェイスを操作できる必要があります。 この点で、監視はホストで実行する必要があり、同時に仮想インフラストラクチャの変化を常に監視する必要があります。 この場合、他のプロセスやサービスに関連付けられたプロセス間のネットワーク接続を監視することができます。これにより、ネットワークデバイスだけでなく、ネットワークの実際の使用を監視できます。
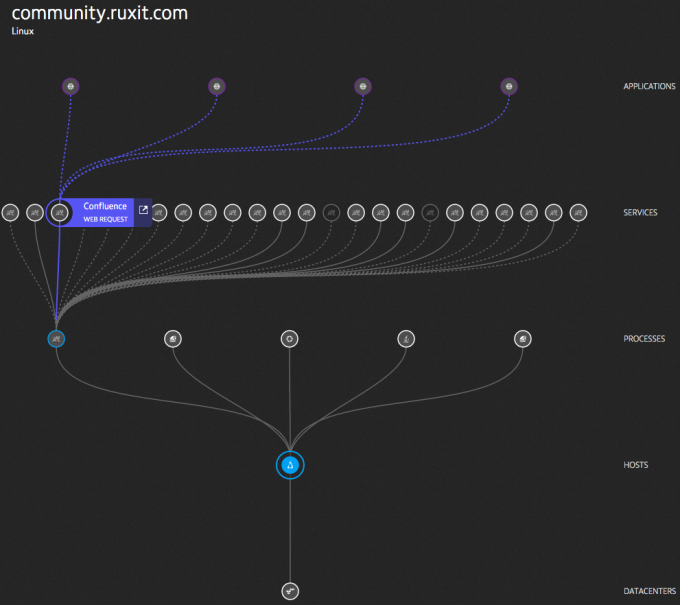
リソースの監視は非常に重要です...簡単です!
この監視方法では、ネットワークは、ネットワークインターフェイス、ルーティングテーブル、およびセキュリティグループの組み合わせだけとは見なされません。 代わりに、ネットワークはプロセスとアプリケーションが使用する限られたリソースと見なされます。 プロセスの観点から見ると、このリソースは中央処理装置、運用メモリ、外部メモリとともに監視でき、定量化することもできます。 さらに、フルスタックアプリケーションのパフォーマンスが監視され、ネットワークレベルの問題をアプリケーションレベルまで検出できます。
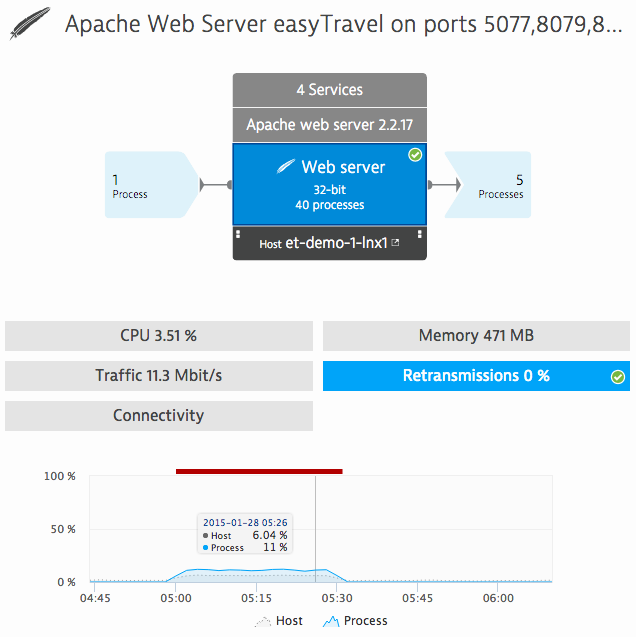
以下は、考慮すべきいくつかの主要なネットワークパフォーマンスメトリックです。
- ネットワークパフォーマンスの主な指標は、ネットワーク上のデータトラフィック(帯域幅)です。
- ネットワーク接続メトリックは、正常に完了したTCP接続の割合を測定し、サービスの可用性を示します。 TCP接続はタイムアウトで中断または終了する可能性があるため、接続の欠如はネットワーク上の送信側と受信側の間の問題の明確な兆候です。
- 確立されたTCP接続の品質を決定するとき、データの再送信の頻度にも注意を払う必要があります。 TCPプロトコルの目的は、信頼性の高い接続とデータ転送中のエラー検出です。 つまり、受信者は、ネットワークリンクを介して送信されたデータパケットを受信することに同意する必要があります。 それ以外の場合、それらは失われたと見なされ、送信者によって再送されます。 したがって、データの再送信の頻度は、ネットワーク内の弱いリンクの存在とそのインフラストラクチャの輻輳を示しています。
仮想化ネットワークは、多かれ少なかれ従来の管理方法には向いていません。 少なくともホストとプロセスの観点からそれらを監視し、ネットワークパフォーマンスの効果的な指標を得る必要があります。