1.標識の強調表示
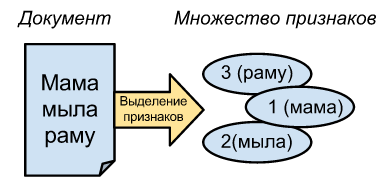
この記事のドキュメントでは、プレーンテキストを意味しますが、一般的な場合は、任意のバイト配列を使用できます。 問題は、MinHashを使用してドキュメントを比較するには、最初に多くの要素に変換する必要があることです。
テキストの場合、複数の単語IDに変換することをお勧めします。 「ママがフレームを洗い流した」-> [1、2、3]、および「ママが洗い流した」-> [1、2]としましょう。
これらのセットの類似度は2/3です。2は類似する要素の数、3は異なる単語の総数です。
また、これらのテキストをNグラムに分割することもできます。たとえば、「お母さんはフレームを洗いました」は「お母さん、ama、ma_、a_m、...」の3グラムに分割され、7/12の類似性が得られます。
2. MinHashを使用して署名を作成する
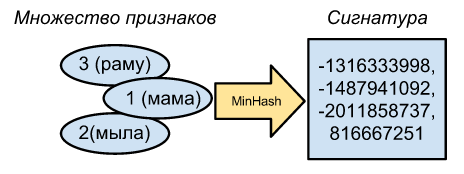
Captain Evidenceは、MinHashがセットのすべてのハッシュの最小ハッシュであることを示しています。 たとえば、単純なランダムハッシュ関数f(v)= vがある場合、単語ID [1、2、3]および[1、2]のセットは、ハッシュのセット[1078、2573、7113]および[1078、2573 ]、および各セットのminhashは1078です。 簡単そうです。
2つのセットの最小ハッシュが一致する可能性は、2つのセットの類似性とまったく同じです。 私はそれを証明したくありません、なぜなら 私は処方にアレルギーがありますが、これは非常に重要です。
さて、1つのミンハッシュがあれば、それほど多くはしませんが、同じセットが同じミンハッシュを与えることはすでに明らかであり、絶対に異なるセットと完全なハッシュ関数では異なることが保証されています。
結果を統合するために、多くの異なるハッシュ関数を使用して、それぞれのハッシュ値を見つけることができます。 簡単に言うと、ランダムではあるが異なる数値を多数生成し、これらの数値に最初のハッシュ関数を適用することで、さまざまなハッシュ関数を取得できます。 完全に乱数700および7000を生成するとします。これにより、2つの追加のハッシュ関数が得られます。 [1、2、3]のマッシュは(1078、2573、7113)-> 1078 、(1674、2225、6517)-> 1674 、(8046、4437、145)-> 145となり、[1、2 ]ハッシュ、その署名は(1078、2573)-> 1078 、(1674、2225)-> 1674 、(8046、4437)-> 4437です。 ご覧のとおり、最初の2組のミンハッシュは一致しています。これから、元のセットの類似性が2/3であると仮定することは非常に大まかに可能です。 ハッシュ関数が多いほど、元のセットの類似性をより正確に判断できることは明らかです。
3.局所性に敏感なハッシュを使用したキーの作成
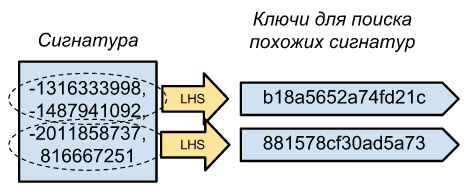
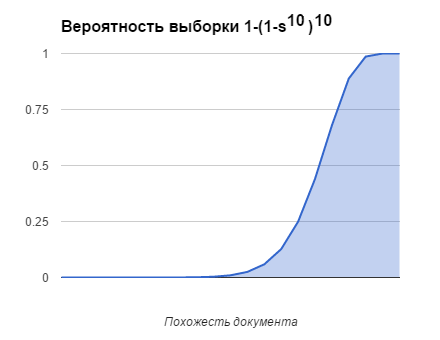
類似ドキュメントが署名(N個のminhash値)のみを使用している方法を判断できるようになりましたが、多かれ少なかれ類似したドキュメントから選択できるようにするには、Key-Valueリポジトリに何を書き込む必要がありますか? 署名全体をキーとして使用する場合、ほとんど同一のドキュメントからのみ選択を行います。 N minheshehが一致する確率はs ^ Nに等しくなります。sはドキュメントのIDです。
解決策は簡単です-署名が100個の数字で構成されているとしましょう。それをいくつかの部分(10個の数字の10個の部分)に分割し、その後これらすべての部分を署名全体のキーにします。
これで、データベースに同様のドキュメントが既にあると判断できました。 100個のハッシュの署名を取得し、10個のキーに分割し、それらに対応するすべての完全な署名について、その類似度(一致するハッシュの数)を計算する必要があります。
それぞれに10個の要素を持つ10個のキーの場合、ドキュメントの類似性に応じてドキュメントを選択する確率は次のようになります。