エラーと不正確さについてどこに書くべきか、あなたは知っています。
過去数か月、および@pedro_g_sや@ flipper83 (ちなみに2人のクールなAndroid開発者)などの同僚とTuentiについて議論した後、Androidアプリケーションの設計に関するメモを書くのが理にかなっていると判断しました。
この投稿の目的は、ここ数か月で推進している設計アプローチについて少しお話しするとともに、このアプローチの調査と実装中に学んだことをすべて共有することです。
はじめに
高品質のソフトウェアを書くことは複雑で多面的なタスクであることを知っています :プログラムは確立された要件を満たすだけでなく、機能を追加または変更するのに十分な信頼性、保守容易性、テスト可能性、柔軟性も必要です。 そして、ここに「スレンダーアーキテクチャ」の概念があります。これは、アプリケーションを開発するときに覚えておくと便利です。
考え方は単純です。 調和のとれたアーキテクチャは 、次のようなシステムを実装するメソッドのグループに基づいています。
- フレームワークに依存しません。
- テスト可能。
- UIに依存しません。
- DBに依存しません。
- 外部サービスに依存しません。
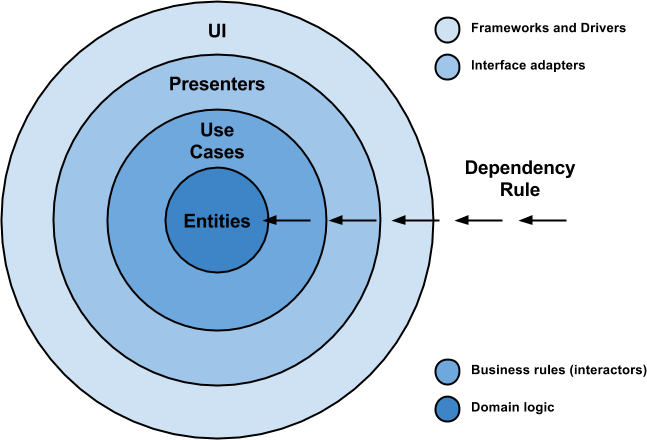
4つの円は必要ありません(図のように)。これは単なる図です。 依存関係のルールを考慮することが重要です。コードは、内側の円でのみ依存関係を持ち、外側の円で何が起こっているのかを把握してはなりません。
このアプローチをよりよく理解するために必要な用語の短い用語集は次のとおりです。
- エンティティ:これは、アプリケーションのビジネスロジックです。
- ユースケース:これらのメソッドは、エンティティへのデータフローとエンティティからのデータフローを編成します。 インタラクターとも呼ばれます。
- インターフェイスアダプター:このアダプターのセットは、用途とエンティティに便利な形式からデータを変換します。 これらのアダプターには、プレゼンターとコントローラーが含まれます。
- フレームワークとドライバー:パーツが集まる場所:UI、ツール、フレームワーク、データベースなど。
よりよく理解するには、 この記事またはこのビデオを参照してください 。
私たちのスクリプト
物事の仕組みを理解するために、簡単なものから始めました。クラウドから受け取った友達のリストを表示する簡単なアプリケーションを作成し、友達をクリックすると、新しい画面に詳細な情報を表示します。
議論されていることを理解するためのビデオをここに残します:
Androidアーキテクチャ
私たちの目標は、ビジネスロジックが外部の世界について何も知らないようにタスクを分離し 、依存関係や外部要素なしでテストできるようにすることです。
これを達成するために、プロジェクトを3つのレイヤーに分割することを提案します 。各レイヤーには独自の目標があり、他のレイヤーとは独立して作業できます。
各レイヤーが独自のデータモデルを使用するため、必要な独立性を実現できることに注意してください(コードでは、データ変換を実行するためにデータマッパーが必要であることがわかります。これは、アプリケーション内のモデルが重複しないようにするための強制料金です)。 これがどのように見えるかの図です:
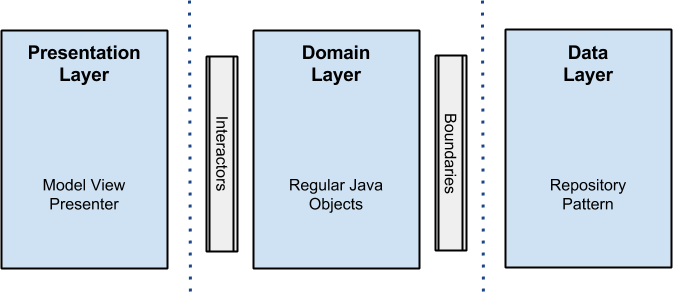
注:サンプルをより視覚的にするために、外部ライブラリー(テスト用のjsonおよびjunit、mockito、robolectric、espressoの解析にgsonを除く)は使用しませんでした。 いずれの場合でも、ORMを使用して情報や依存性注入フレームワークを保存することをためらわないでください。実際、生活を楽にするツールやライブラリーを忘れないでください(車輪の再発明はお勧めできません)。
プレゼンテーション層
ここで、ロジックはビューに関連付けられ、アニメーションが発生します。 これはモデルビュープレゼンター (つまりMVP )に過ぎませんが、MVCやMVVMなどの他のパターンを使用できます。 詳細には触れませんが、フラグメントとアクティビティは単なるビューであり、UIロジックとこのディスプレイ自体のレンダリング以外にロジックはありません。 このレイヤーのプレゼンターは、 インタラクターと通信します。これは、UIストリームではなく、新しいストリームで作業し、ビューに表示される情報をコールバックを通じて送信することを意味します。
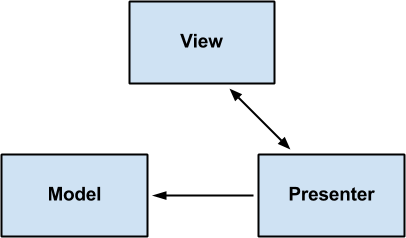
MVPとMVVMを使用する効果的なAndroid UIのクールな例をご覧になりたい場合は、私の友人PedroGómezの実装例をご覧ください。
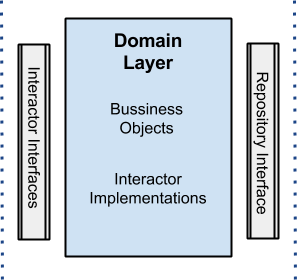
ドメイン層(ビジネス層)
すべてのロジックはこのレイヤーに実装されます。 プロジェクトを考慮すると、ここにインタラクターの実装が表示されます(ユースケース-使用方法)。
このレイヤーは、Androidに依存しない純粋なJavaモジュールです。 すべての外部コンポーネントは、インターフェイスを使用してビジネスオブジェクトと通信します。
データ層
アプリケーションに必要なすべてのデータは、UserRepositoryの実装を通じてこのレイヤーから配信されます(インターフェイスはドメインレイヤー-ビジネスロジックレイヤーにあります)。特定の条件に応じて、ファクトリーを通じてさまざまなデータソースを選択する戦略でリポジトリパターンを使用します 。
たとえば、特定のユーザーをIDで取得する場合、ユーザーが既にロードされている場合、データソースはディスクキャッシュを選択します。そうでない場合は、同じキャッシュ内のさらなるストレージのデータを受信するためにリクエストがクラウドに送信されます。
このすべての考えは、データの起源は気にしないクライアントにとって理解可能であり、データはメモリ、キャッシュ、またはクラウドから来ているということです。データが受信され利用可能になるのは彼にとってのみ重要です。

注:コードについては、コードがトレーニングの例であることを思い出して、共有の共有設定を使用して、非常にシンプルでプリミティブなキャッシュを実装しました。 覚えておいてください:問題をうまく解決するライブラリがある場合は、 自転車を投入しないでください。
エラー処理
これは常に議論すべき大きなトピックです(そして、ここで著者は自分の決定を共有することを提案しています)。 実装に関しては、 コールバックを使用しました 。たとえば、データウェアハウスで何かが発生した場合、 onResponse()およびonError()という 2つのメソッドがあります。 後者は、 「ErrorBundle」と呼ばれるラッパークラスに例外をカプセル化します。エラーが表示されるプレゼンテーション層に到達するまで、コールバックチェーンが1つずつあるため、このアプローチにはいくつかの困難が伴います。 このため、コードの可読性が少し損なわれる可能性があります。
一方、何かが間違っている場合にイベントをスローするイベントバスシステムを実装しましたが、そのようなソリューションはGOTOを使用するのに似ています。特にそれらのいくつかが同時に急ぐとき。
テスト中
テストに関しては、レイヤーに応じていくつかのソリューションを適用しました。
- プレゼンテーションレイヤー :統合および機能テスト用の既存のAndroidツールとエスプレッソ。
- ドメイン層 :ユニットテストにはJUnit + mockitoが使用されました。
- データ層 :Robolectric(この層にはAndroid依存関係があるため)+ junit +統合および単体テスト用。
コードを見せて
この場所では、コードを見ることに興味があると思います。 さて、 ここに私がやったことを見つけることができるgithubへのリンクがあります。 フォルダー構造について言及する価値があるのは、異なるレイヤーが異なるモジュールによって表されることです。
- presentation :これはプレゼンテーションレイヤー用のAndroidモジュールです。
- ドメイン :Android依存関係のないJavaモジュール。
- data :android-module、ここからすべてのデータが取得されます。
- data-test :データ層のテスト。 特定の制限のため、Robolectricを使用する場合、別のJavaモジュールを使用する必要がありました。
おわりに
ボブおじさんは「建築はフレームワークではなく意図である」と言っており、私は彼に完全に同意します。 もちろん、何かを実装するさまざまな方法があります。私と同じように、この分野では毎日あなたが困難に直面していると確信していますが、これらのテクニックを使用すると、アプリケーションは次のようになります。
- サポートが簡単。
- テストが簡単。
- 全体を作ります
- 分割されています。
結論として、これらの方法を試して結果を確認し 、これと他のアプローチの両方で経験を共有することを強くお勧めします 。あなたの観察によれば、より効果的です: 継続的な改善は常に有用で肯定的であると確信しています。