この投稿は、マイクロエレクトロニクスとコンピューターアーキテクチャを専門とするウィスコンシン大学マディソン校教授のジェームススミスによる講演に基づいています。
コンピュータサイエンス全体の歴史は、科学者が人間の脳がどのように機能するかを理解し、同様の能力を再現しようとしているという事実に帰着します。 科学者はそれをどのくらい正確に研究していますか? 21世紀に、地球に飛んでそのようなコンピューターの構造を探ろうとするのに慣れているコンピューターを見たことのないエイリアンがいると想像してください。 ほとんどの場合、彼らは導体の電圧を測定することから始め、データがバイナリ形式で送信されることを発見します。電圧の正確な値は重要ではなく、その有無のみが重要です。 そして、おそらく、彼らはすべての電子回路が入力と出力を持つ同じ「論理ゲート」で構成され、回路内の信号が常に一方向に送信されることを理解するでしょう。 エイリアンが十分に賢い場合、 組み合わせ回路がどのように機能するかを理解できます-彼らだけで比較的複雑なコンピューティングデバイスを構築するのに十分です。 たぶん、エイリアンは時計とフィードバックの役割を理解するでしょう。 しかし、最新のプロセッサを研究することで、共有メモリ、コマンドカウンタ、レジスタセットなどを備えたフォンノイマンアーキテクチャを認識できない可能性があります。 事実、プロセッサでのパフォーマンスの追求の40年の結果によると、「メモリ」の階層全体が、それらの間の巧妙な同期プロトコルとともに現れました。 遷移予測を備えたいくつかの並列パイプライン。したがって、「コマンドカウンター」の概念は実際にはその意味を失います。 各コマンドには独自のレジスタ内容などがあります。 マイクロプロセッサを実装するには、数千個のトランジスタで十分です。 そのパフォーマンスが通常のレベルに達するには、何億もかかります。 この例の意味は、「コンピューターはどのように機能するのか」という質問に答えることです。数億個のトランジスターの動作を理解する必要はありません。コンピューターのアーキテクチャーの基礎となる単純なアイデアをあいまいにするだけです。
ニューロンモデリング
人間の脳の皮質は約1,000億のニューロンで構成されています。 歴史的に、脳の働きを調査する科学者たちは、この巨大な構造を彼らの理論で具体化しようとしました。 脳の構造は階層的に記述されています。皮質は葉、 「ハイパーコラム」のローブ、 「ミニコラム」のローブで構成されています... ミニコラムは約100個の個々のニューロンで構成されています。
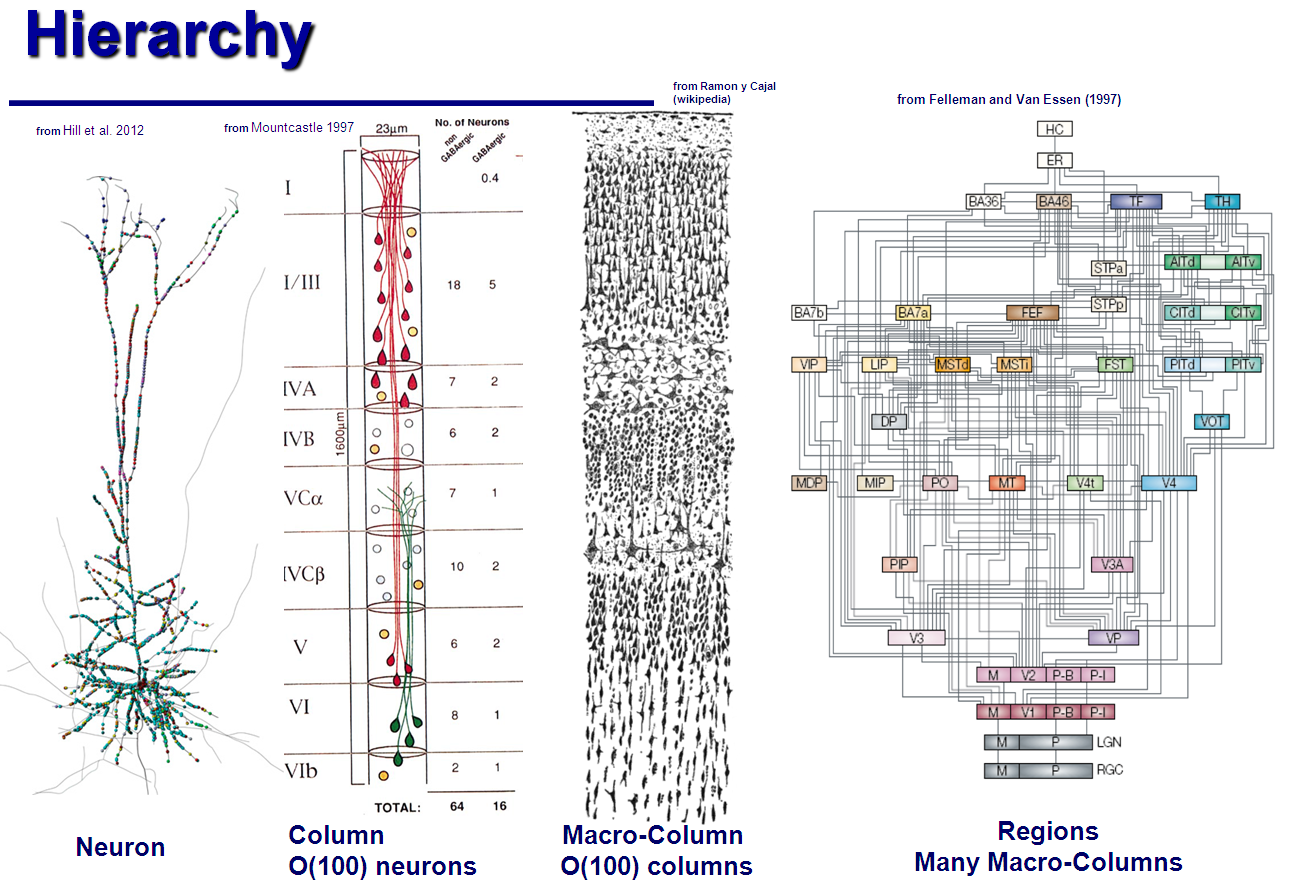
コンピューターデバイスとの類推により、これらのニューロンの大部分は、速度と効率、障害に対する耐性などのために必要です。 しかし、顕微鏡下でマイクロプロセッサを調べることでコマンドカウンターを検出することが不可能であるように、脳の配置の基本原理も顕微鏡で検出することは不可能です。 したがって、より実り多いアプローチは、個々のニューロンとその列のレベルで、最低レベルの脳の構造を理解しようとすることです。 そして、その特性に基づいて、脳全体がどのように機能するかを想像してみてください。 このような何か、エイリアンは、論理ゲートの動作を理解し、最終的にそれらを最も単純なプロセッサにし、はるかに複雑で強力であるにもかかわらず、その機能が実際のプロセッサと同等であることを確認できます。
上の図では、ニューロンの本体 (左)は下部にある小さな赤い斑点です。 他のすべて- 樹状突起 、ニューロンの「入力」、および1つの軸索 、「出力」。 樹状突起に沿った多色の点は、ニューロンが他のニューロンの軸索に接続されるシナプスです。 ニューロンの動作は非常に簡単に説明されています。しきい値レベルを超える軸索で「サージ」が発生すると(通常のバースト持続時間は1ms、レベル100mV)、シナプスは「ブレークスルー」し、電圧サージは樹状突起に切り替わります。 この場合、サージは「平滑化」されます。最初に、電圧は約5..20 msで約1 mVに上昇し、その後指数関数的に減衰します。 したがって、バースト期間は最大50msまで延長されます。
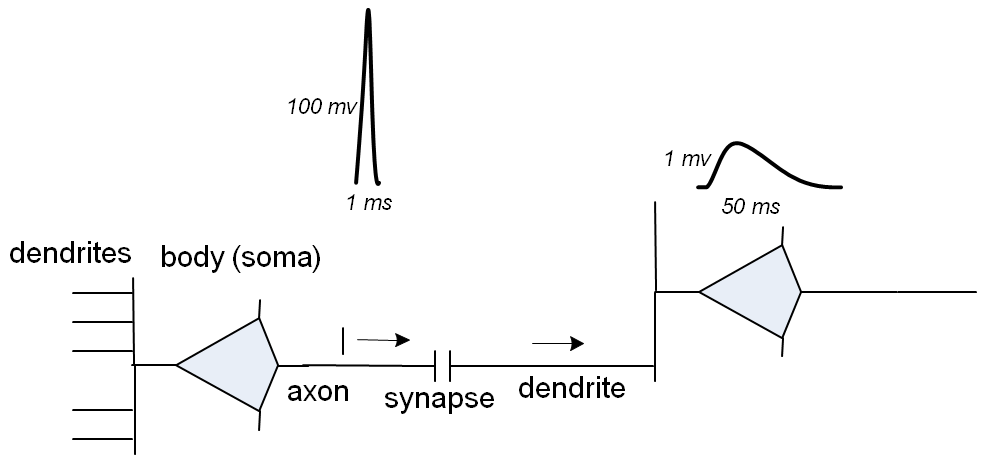
1つのニューロンの複数のシナプスが短い時間間隔でアクティブ化されると、それらの各ニューロンによって励起される「スムーズバースト」が合計されます。 最後に、かなりの数のシナプスが同時にアクティブになると、ニューロンの電圧がしきい値レベルを超えて上昇し、それ自体の軸索がそれに関連するニューロンのシナプスを「突破」します。
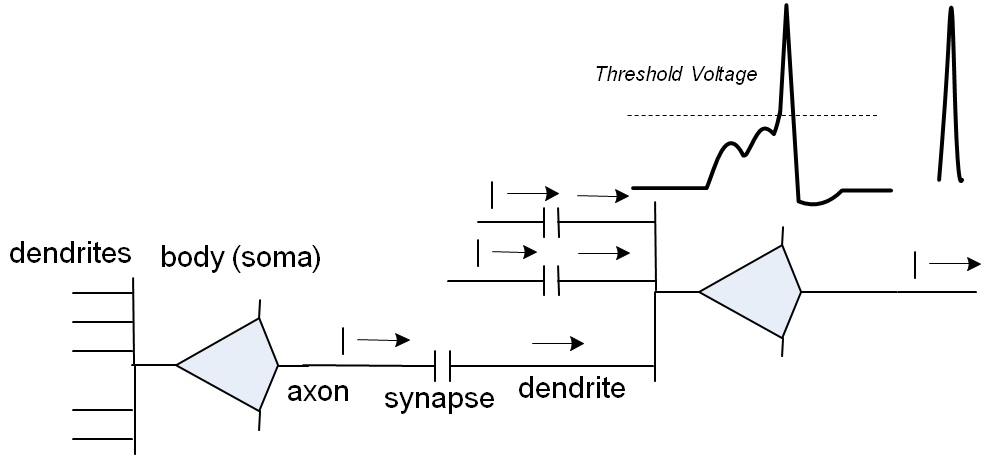
初期バーストが強力であればあるほど、平滑化されたバーストはより速く成長し、次のニューロンの活性化までの遅延は少なくなります。
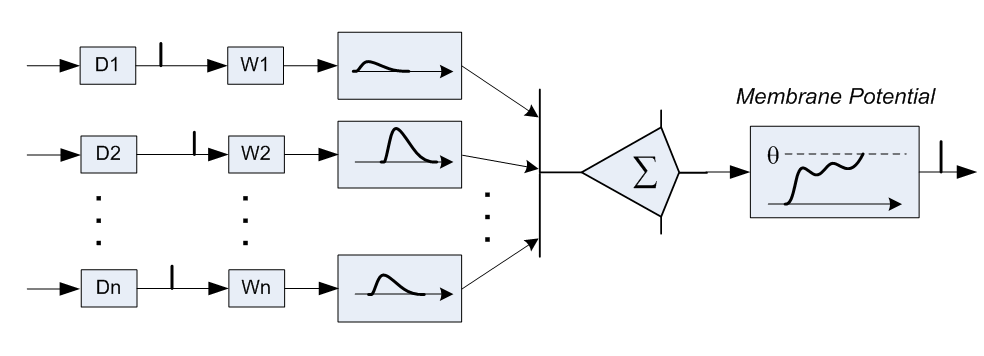
さらに、「抑制性ニューロン」があり、その活性化により、関連するニューロンの全体的な電圧が低下します。 そのような抑制性ニューロンは全体の15..25%です。
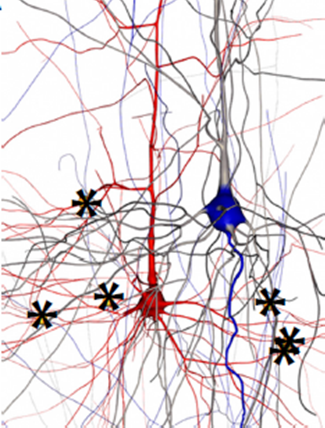 各ニューロンには数千のシナプスがあります。 ただし、常にアクティブなシナプスの10分の1以下です。 ニューロンの反応時間-単位ms; 樹状突起に沿った信号伝播の遅延と同じオーダー、すなわち これらの遅延は、ニューロンの機能に大きな影響を及ぼします。 最後に、原則として、隣接するニューロンのペアは、1つのシナプスではなく、10のオーダーで接続されます。各ニューロンは、両方のニューロンの本体までの距離があり、したがって遅延時間が異なります。 右の図では、赤と青で描かれた2つのニューロンが6つのシナプスで接続されています。
各ニューロンには数千のシナプスがあります。 ただし、常にアクティブなシナプスの10分の1以下です。 ニューロンの反応時間-単位ms; 樹状突起に沿った信号伝播の遅延と同じオーダー、すなわち これらの遅延は、ニューロンの機能に大きな影響を及ぼします。 最後に、原則として、隣接するニューロンのペアは、1つのシナプスではなく、10のオーダーで接続されます。各ニューロンは、両方のニューロンの本体までの距離があり、したがって遅延時間が異なります。 右の図では、赤と青で描かれた2つのニューロンが6つのシナプスで接続されています。
各シナプスには独自の「抵抗」があり、着信信号を低下させます(上記の例では、100mVから1mVに)。 この抵抗は動的に調整されます:軸索の活性化の直前にシナプスが活性化された場合、明らかに、このシナプスからの信号は一般的な結論とよく相関しているため、抵抗は減少し、信号はニューロンの電圧に大きく貢献します。 軸索の活性化の直後にシナプスが活性化された場合、明らかに、このシナプスからのシグナルは軸索の活性化に関係していなかったため、シナプス抵抗が増加します。 2つのニューロンが異なる遅延時間の複数のシナプスで接続されている場合、抵抗のこの調整により、最適な遅延または最適な遅延の組み合わせを選択できます。信号は、最も有用なタイミングで正確に到達し始めます。
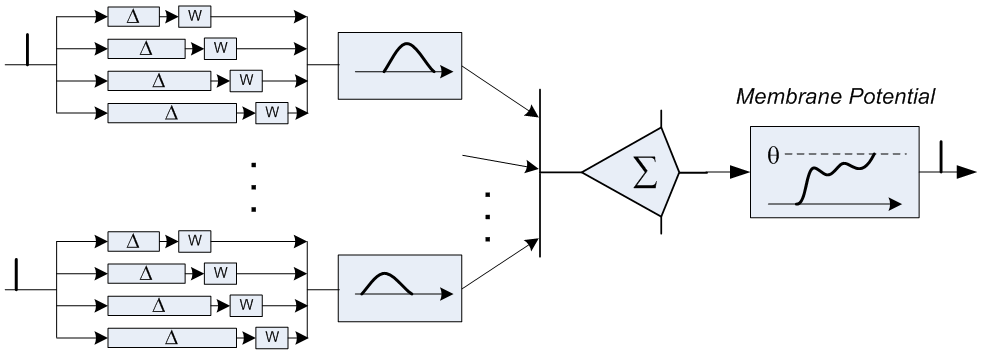
このように、ニューラルネットワークの研究者が採用したニューロンモデルは、一対のニューロン間の唯一の接続と、あるニューロンから別のニューロンへの信号の瞬間的な伝播によって、生物学的な状況からはかけ離れています。 さらに、従来のニューラルネットワークは、個々のバーストの時間ではなく、その周波数で動作します 。ニューロンの入力でのバーストが頻繁になるほど、出力でのバーストが頻繁に発生します。 従来のモデルでは破棄されていたニューロンデバイスの詳細は、脳の機能を説明するために不可欠ですか、それとも必須ではありませんか? 神経科学者は、ニューロンの構造と挙動に関する膨大な量の観察結果を蓄積していますが、これらの観察結果のうち、全体像を明らかにするものはどれですか?また、「実装の詳細」であり、プロセッサの遷移の予測子のように、パフォーマンス以外には影響しませんか? ジェームズは、問題の理解に近づくことができるのは、まさにニューロン間の相互作用の時間的特性だと考えています。 非同期性は脳の機能にとって重要であり、同期性はコンピューターの操作にとっても重要です。
もう1つの「実装の詳細」は、ニューロンの信頼性の低さです。樹状突起のストレスの合計がしきい値レベルに達していない場合でも、ある程度の確率で自発的に活性化できます。 このため、ニューロンコラムの「トレーニング」は、すべてのシナプスで十分に大きい抵抗から開始できます。最初は、シナプスの活性化の組み合わせは軸索の活性化につながりません。 その後、自発的なバーストはシナプスの抵抗の減少につながり、これらの自発的なバーストの直前にアクティブになりました。 したがって、ニューロンは入力バーストの特定の「パターン」を認識し始めます。 最も重要なことは、ニューロンが訓練されたものと同様のパターンも認識されますが、軸索のバーストはより弱くなります/または後で、ニューロンが結果の「確実な」ことは少なくなります。 ニューロンの列を学習することは、通常のニューラルネットワークをトレーニングするよりもはるかに効果的です。ニューロンの列は、トレーニング対象のサンプルの制御応答を必要としません。実際、入力パターンを認識しませんが、 分類します。 さらに、ニューロン列のトレーニングはローカライズされています -シナプス抵抗の変化は、それによって接続された2つのニューロンのみの動作に依存し、他のニューロンには依存しません。 この結果、トレーニングは信号経路に沿った抵抗の変化につながりますが、ニューラルネットワークをトレーニングする場合、重みは反対方向に変化します。出口に最も近いニューロンから入口に最も近いニューロンに変化します。
たとえば、バーストパターン(8,6,1,6,3,2,5)を認識するようにトレーニングされたニューロンの列があります-値は各入力でのバースト時間を示します。 トレーニングの結果、遅延は認識されたパターンと正確に一致するように調整されるため、正しいパターンによって引き起こされる軸索の電圧は可能な限り最大になります(7)。
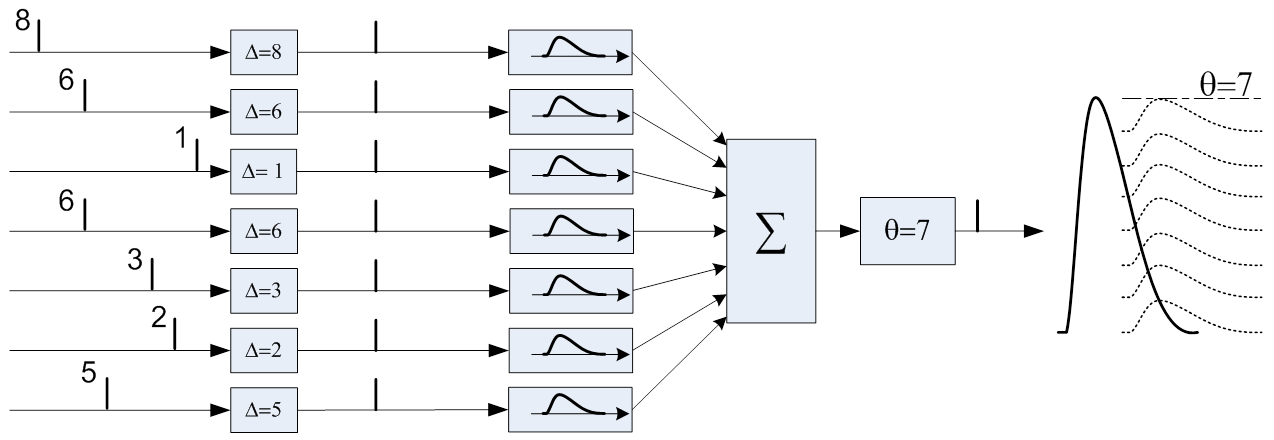
同じ列は、より小さなバースト(6)で同様の入力パターン(8,5,2,6,3,3,4)に応答し、電圧はずっと後にしきい値レベルに達します。
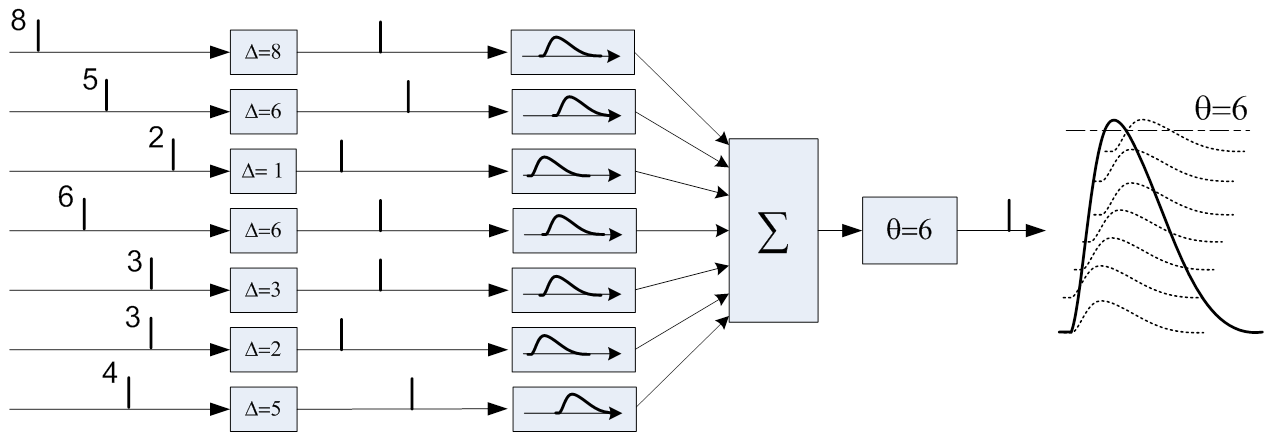
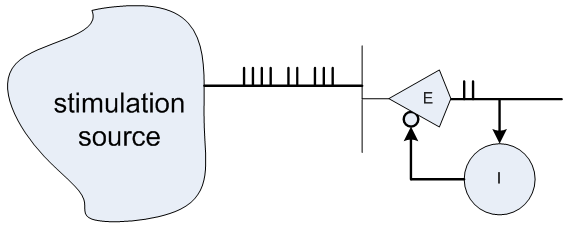 最後に、抑制性ニューロンを使用して「フィードバック」を実装できます。たとえば、右の図のように、-入力が長時間アクティブのままの場合、出力で繰り返されるバーストを抑制します。 または、分類器をより「カテゴリカル」にするために、入力信号と比較して遅すぎる場合、出力でのバーストを抑制します。 または、パターン認識のニューラル回路では、異なる分類子列を抑制ニューロンで接続して、1つの分類子をアクティブにすると他のすべての分類子を自動的に抑制することができます。
最後に、抑制性ニューロンを使用して「フィードバック」を実装できます。たとえば、右の図のように、-入力が長時間アクティブのままの場合、出力で繰り返されるバーストを抑制します。 または、分類器をより「カテゴリカル」にするために、入力信号と比較して遅すぎる場合、出力でのバーストを抑制します。 または、パターン認識のニューラル回路では、異なる分類子列を抑制ニューロンで接続して、1つの分類子をアクティブにすると他のすべての分類子を自動的に抑制することができます。
画像認識
MNISTデータベース (28 x 28ピクセルのグレーの陰影)から手書き数字を認識するために、上記の分類列のJamesは、5層の「畳み込みニューラルネットワーク」の類似物を組み立てました。 最初のレイヤーの64列のそれぞれは、元の画像から5x5ピクセルのフラグメントを処理します。 そのような断片は重なります。 2番目のレイヤーの列は、最初のレイヤーからの4つの出口をそれぞれ処理します。これは、元の画像の8x8ピクセルのフラグメントに対応します。 3番目のレイヤーには4列しかありません。各列は16x16ピクセルのフラグメントに対応しています。 4番目の層(最終分類子)は、すべての画像を16のクラスに分割します。クラスは、どのニューロンが最初にアクティブ化されるかに従って割り当てられます。 最後に、5番目の層は古典的なパーセプトロンであり、16のクラスと10の制御回答を関連付けます。
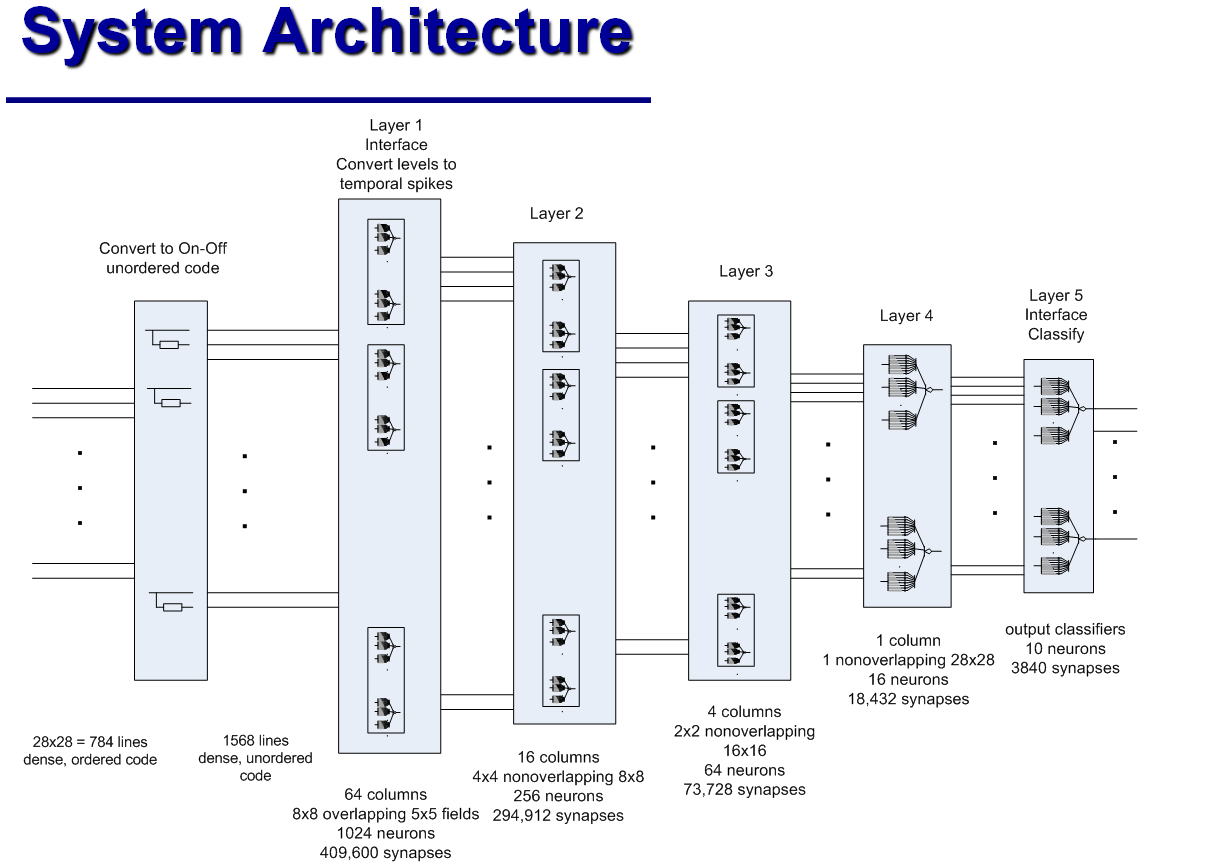
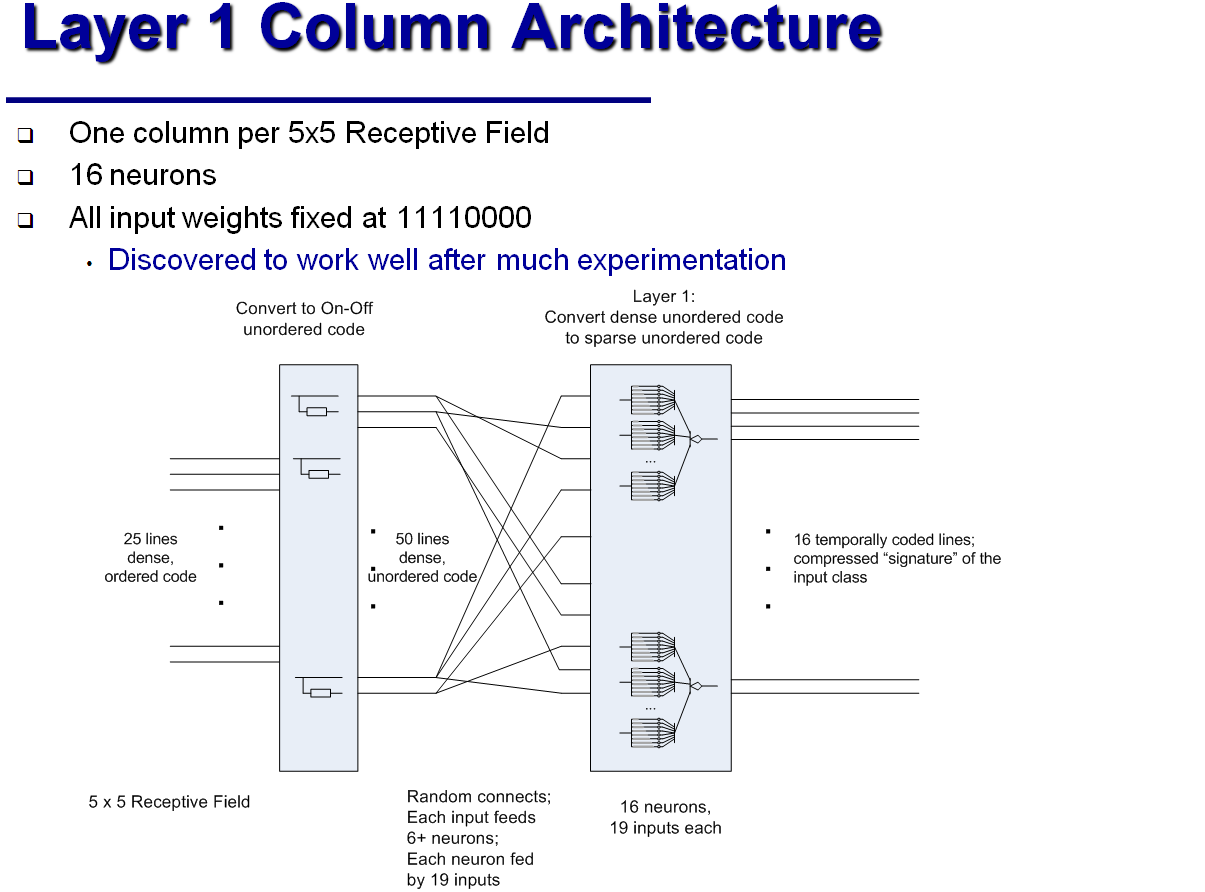
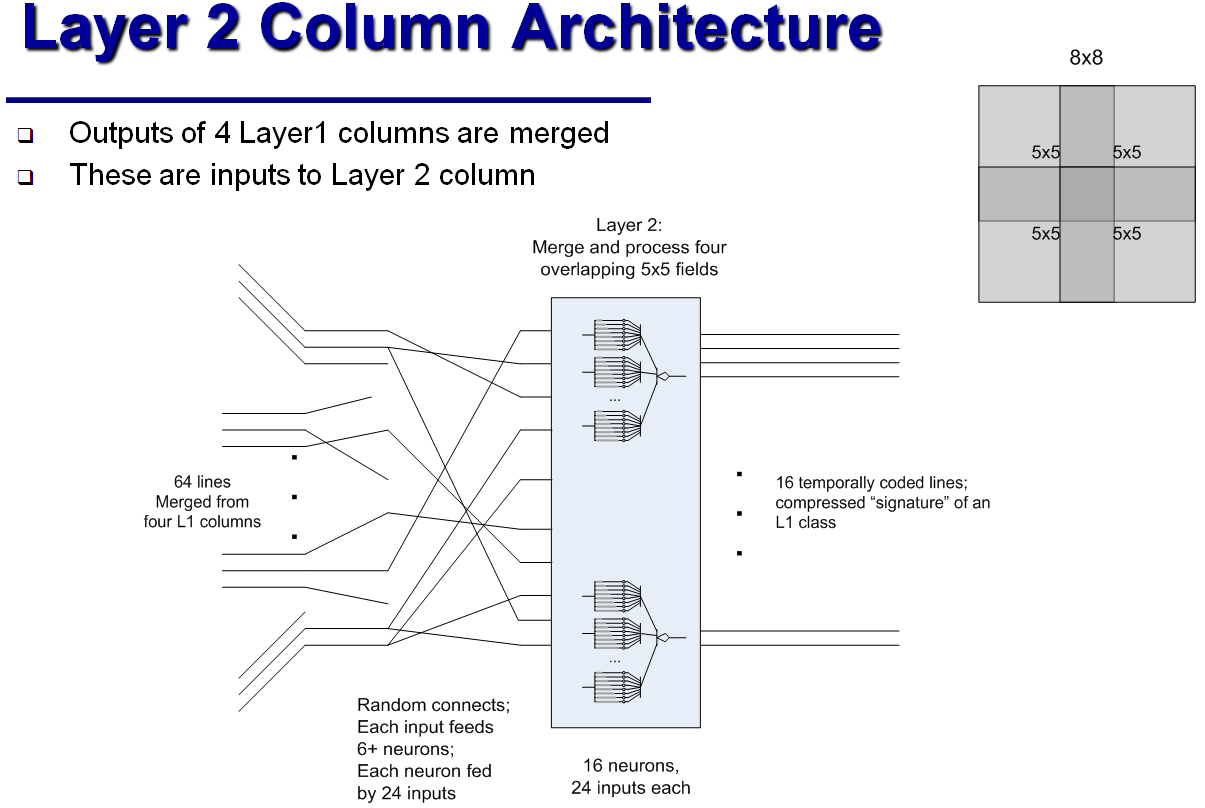
従来のニューラルネットワークは、MNISTに基づいて99.5%以上の精度を実現しています。 しかし、ジェームズによると、彼の「ハイパーコラム」は、変化が信号経路に沿って伝播し、したがってより少ない数のニューロンに影響を与えるという事実により、はるかに少ない反復回数で訓練されます。 古典的なニューラルネットワークに関しては、「ハイパーコラム」の開発者は、ニューロン間の接続の構成、およびハイパーコラムのすべての定量的特性のみを決定します。 遅延が異なるシナプスの抵抗-学習プロセスで自動的に取得されます。 さらに、ハイパーコラムの操作には、同様のニューラルネットワークの機能よりも1桁少ない数のニューロンが必要です。 一方、電子コンピューターでのそのような「アナログ神経回路」のシミュレーションは、離散信号と離散時間間隔で動作するデジタル回路とは異なり、電圧変動の連続性とニューロンの非同期性が神経回路の動作にとって重要であるという事実により、やや複雑です。 ジェームズは、レコグナイザが正しく機能するには0.1msのシミュレーションステップで十分であると主張しています。 しかし、彼は古典的なニューラルネットワークのトレーニングと作業にどれだけの「リアルタイム」がかかるか、シミュレータのトレーニングと作業にどれくらいかかるかを指定しませんでした。 彼自身は長い間引退しており、彼の自由時間をアナログ神経回路の改善に費やしています。
tyomitchからの要約 :生物学的前提条件に基づくモデルが提示され、非常に単純に配置され、同時に従来のデジタル回路やニューラルネットワークから根本的に区別する興味深い特性を備えています。 おそらく、このような「アナログニューロン」は、多くのタスク(パターン認識など)に対処できる将来のデバイスの基本要素になり、人間の脳ほど悪くはないでしょう。 まるでデジタル回路が人間の脳を数える能力をはるかに超えているように。