
Parallel Studio XE 2015の「イノベーション」に関する投稿で 、Intelの興味深いテクノロジーであるグラフィックステクノロジーについて書くことを約束しました。 実際、これは私が今やろうとしていることです。 インテルグラフィックステクノロジーの本質は、プロセッサの統合グラフィックスコアを使用して計算を実行することです。 これはスケジュールのオフロードであり、当然、パフォーマンスが向上します。 統合されたグラフィックスは非常に強力であるため、この成長は本当に大きくなりますか?
第4世代Intel Coreのプロセッサに統合された新しいグラフィックコアGT1、GT2、GT3 / GT3eのファミリーを見てみましょう。
はい、グラフィックスは第3世代のものでしたが、これらはすでに「過去の出来事」です。 GT1コアのパフォーマンスは最小で、GT3のパフォーマンスは最大です。
| HD(GT) | HD 4200
HD 4400 HD 4600(GT2) | HD 5000
アイリス5100(GT3)、 Iris Pro 5200(GT3e) | |
|---|---|---|---|
| API | DirectX 11.1、DirectX Shader Model 5.0、OpenGL 4.2、OpenCL 1.2 | ||
| 数
幹部 ブロック(実行ユニット) | 10 | 20 | 40 |
| FP操作の数
ビートごと | 160 | 320 | 640 |
| あたりのスレッド数
幹部 デバイス/合計 | 7/70 | 7/140 | 7/280 |
| L3キャッシュ
| 256 | 512 | 1024 |
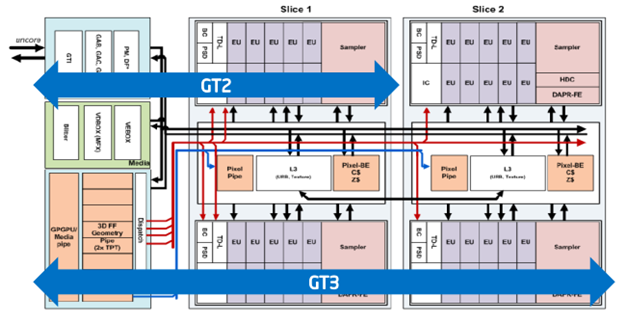
つまり、GT1の場合、すべてがほぼ同じであり、「レイヤー」のみを水平方向に半分にカットする必要があります。 最も高度な例として、ささいなことはせず、グラフィックスGT3eの可能性について説明します。 したがって、ブロックごとに7つのスレッドを持つ40の実行ユニットがあります。 合計で、最大280のスレッドがあります! システムの「モーター」の出力が大幅に増加しました。
同時に、各ストリームのレジスタファイル(GRF-汎用レジスタファイル)で4 KBを使用できます。これは、ローカルデータを保存するグラフィックスで使用可能な最速のメモリです。 合計ファイルサイズは1120 KBです。
一般に、メモリモデルは非常に興味深いものであり、次のように概略的に表すことができます。
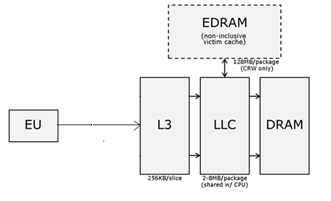
レジスタに加えて、グラフには独自のL3キャッシュ(各½「レイヤー」に対して256 KB)と、LLC(Last Level Cache)があります。LLCはL3プロセッサキャッシュであり、CPUとGPUに共通です。 GPUコンピューティングに関しては、L1およびL2キャッシュはありません。 最も強力なGT3e構成でのみ、別の128 MBのeDRAMキャッシュが利用可能です。 プロセッサコンポーネントと同じケースにありますが、Haswellチップの一部ではなく、統合グラフィックスのパフォーマンスを向上させる上で重要な役割を果たし、一部がビデオメモリとしても使用できるコンピューターランダムアクセスメモリ(DRAM)への依存をほぼ排除します。
すべてのプロセッサバージョンに同じ統合グラフィックスがあるわけではありません。 サーバーモデルは、グラフィックスではなく、はるかに多くのコンピューティングコアを持つことを好むため、グラフィックステクノロジーが可能なケースは大幅に絞り込まれています。 私はついにHaswellと統合されたIntel HD Graphics 4400グラフィックスを備えたラップトップを待っていました。つまり、64ビットLinuxシステムと32ビットおよび64ビットWindowsシステムでサポートされているIntel Graphics Technologyで遊ぶことができます。
実際、ハードウェアの需要に応じてすべてが明確になっています。それがなければ、グラフィックスコアでの計算について話すことは無意味です。 ドキュメント(はい、はい...すぐに機能しなかったため、私も読んでいた)は、すべてがこれらのモデルで機能するはずだと述べています。
- Intel HDグラフィックスP4700を搭載したIntel XeonプロセッサーE3-1285 v3およびE3-1285L v3(Intel C226チップセット)
- Intel Iris Pro Graphics、Intel Iris Graphics、またはIntel HD Graphics 4200+シリーズを搭載した第4世代Intel Coreプロセッサー
- Intel HD Graphics 4000/2500を搭載した第3世代Intel Coreプロセッサー
「鉄片が登場し、GTコンパイラがインストールされます。 すべてが飛ぶはずです!」と考え、グラフィックステクノロジ用のコンパイラに付属しているサンプルの収集に取りかかりました。
コードの観点から、私は特別なことに気付きませんでした。 はい、次のようにcilk_forループの前にいくつかのプラグマが現れました。
void vector_add(float *a, float *b, float *c){ #pragma offload target(gfx) pin(a, b, c:length(N)) cilk_for(int i = 0; i < N; i++) c[i] = a[i] + b[i]; return; }
これについては次の投稿で詳しく説明しますが、今のところは/ Qoffloadオプションを使用してサンプルの収集を試みます。 すべてがコンパイルされたように見えますが、リンカー(ld.exe)が見つからないというエラーにより、少し停止しました。 重要な点を1つ逃しましたが、すべてがそれほど些細なわけではありませんでした。 ドキュメントを詳しく調べる必要がありました。
統合グラフィックスへのオフロードでアプリケーションを実行するためのソフトウェアスタックは次のようになりました。

コンパイラーは、チャートですぐに実行できるコードを生成する方法を知りません。 彼は、VISA(仮想命令セットアーキテクチャ)アーキテクチャ用のIR(中間表現)コードを作成します。 そして、それは、インストールパッケージでIntel HD Graphicsのドライバーと共に提供されるJIT'terを使用して、チャート上で実行(実行時に変換)できます。
グラフィックテクノロジーのオフロードを使用してコードをコンパイルすると、グラフィックコアで実行される部分が「縫い付けられた」オブジェクトオブジェクトが生成されます。 この共通ファイルはfatと呼ばれます。 これらの「脂肪オブジェクト」をこのようにリンクすると、チャートで実行されるコードは、.gfxobj(Windows用)というホスト上のバイナリに組み込まれたセクションになります。
ここで、リンカーが見つからなかった理由が明らかになります。 Intelコンパイラーは、LinuxとWindowsの両方で、独自のリンカーを持たず、持っていませんでした。 そして、ここでは1つのファイルで、異なる形式のオブジェクトオブジェクトを「縫い合わせる」必要があります。 Microsoftの単純なリンカーはこれを行う方法を知らないため、 ここで入手可能な特別なバージョンのbinutils(2.24.51.20131210)をインストールし、同じld.exe(私の場合はC:\ Program Files(x86)\ Binutils for PATHのMinGW(64ビット)\ bin )。
必要なものをすべてインストールした後、最終的にWindowsでテストプロジェクトを作成し、次のものを入手しました。
dumpbin matmult.obj Microsoft (R) COFF/PE Dumper Version 12.00.30723.0 Copyright (C) Microsoft Corporation. All rights reserved. Dump of file matmult.obj File Type: COFF OBJECT Summary 48 .CRT$XCU 2C .bss 5D0 .data 111C .data1 148F4 .debug$S 68 .debug$T 32F .drectve 33CF8 .gfxobj 6B5 .itt_notify_tab 8D0 .pdata 5A8 .rdata AD10 .text D50 .xdata
チャートでの実行に必要なオブジェクトオブジェクトは、特別なツール(offload_extract)を使用してファットオブジェクトオブジェクトから抽出できます。 インテル®コンパイラーを起動する環境がコンソールで設定されている場合、これは非常に簡単です。
offload_extract matmult.obj
その結果、パパでは、GFXプレフィックスが最後に付いた別のオブジェクトを見つけることができます。私の場合はmatmultGFX.oです。 ちなみに、PE形式ではなく、ELF形式でした。
ところで、オフロードが不可能で、アプリケーションの起動中にグラフィックコアが利用できない場合、実行はホスト(CPU)上で行われます。 これは、コンパイラツールとオフロードランタイムを使用して実現されます。
私たちは、すべてがどのように機能するかを理解しました。 さらに、開発者が利用できるものと、チャートで最終的に機能するコードの記述方法について説明します。
情報が多すぎて、すべてを1つの投稿のフレームワークに収めることができなかったため、「続ける...」と言われています。