エレクトロニクスデザインセンターのプロムワッドのチームは、冬休みの後、ファームウェアの開発とシリアル生産用の新しいデバイスに関する新しい記事を送り、Habrに戻ります。 今日は、ネットワークテクノロジーのトピックでの経験を共有します。
平均的なホームネットワークは、小規模企業のネットワークと同様に、最初に出会った中国のスイッチを介して接続された2つまたは3つのコンピューターだけではありませんでした。 コンテンツ(データベース、ストリーミングオーディオ/ビデオなど)の量の増加と、デバイス(VoIPデバイス、サーバー、NAS、IPカメラ、およびホームネットワーク-テレビやその他の「モノのインターネット」)の数の増加)ネットワークインフラストラクチャを介して送信されるデータの量は増加しています。 データストリームは、トラフィックの優先順位付けを忘れずに、データストリーム間で分割する必要があります。たとえば、IPTVよりも優先度の高いVoIPトラフィックを開始し、トレントよりもIPTVを優先的に開始することが望ましいです。 したがって、時間の経過とともに、小さなローカルネットワークでさえ複雑になり、単一スイッチのポート容量が不十分になることは驚くことではありません...
大規模なネットワークノードのポート容量を増やし、ネットワーク全体の帯域幅を増やすために、いわゆるいわゆる スタック-送信データのストリームに応じて、スイッチを階層構造に結合します。
図に示すように、ネットワークを構築するための最も「古典的な」アーキテクチャはツリーです。

同時に、ノードAからノードDへのトラフィックはアップストリームスイッチのチェーンを通過するため、追加のパフォーマンス要件が課されます。次の(アップストリーム)ツリーノードのスループットは前のものよりも高くなければなりません。
ネットワークのメインノードをアンロードするために、ほとんどの場合、スイッチ間に追加の接続が導入されます。 たとえば、次の図に示すように、ネットワークの「コア」は多くの場合、スイッチのリングの形で編成されます。

古き良きイーサネットを使用する場合、ブロードキャストトラフィックでのリングのオーバーフローを回避するために、スパニングツリープロトコルを使用して、リングスイッチ間のリンクの1つを非アクティブ状態にします。 これにより、中央のリングがいつでも切れた場合に代替のトラフィックパスを提供できます。 「リング」用に特別に設計されたプロトコル(FDDIやトークンリングなど)が使用されている場合、リングは壊れず、リングに含まれるスイッチの負荷が最も均一になり、トラフィックがリングに沿って送信されます。
もちろん、必要に応じて、ノードがツリーの最上部である複数の交差リングを使用するまで、同じネットワーク内で異なるトポロジを組み合わせることを禁止しません。
ネットワークを構築する場合、パッシブスイッチノードを接続するだけでなく、異なるタイプのトラフィックの優先度と分離を考慮して、ノード間のデータ転送を保証する必要があります。 同時に、これらの優先順位を設定するために、一元的なネットワーク管理の一元化の可能性を維持することが望ましいです。 すべてのネットワーク機器を特定の論理エンティティに結合する必要があります。
Distributed Switch Architectureテクノロジーは、このような機会を提供します。これにより、広範なネットワークを単一のデバイスとして管理し、システム全体のトラフィックのパスを設定できます。 同時に、スイッチノードは、すべてのノードに共通の1つの制御プロセッサを備えたシンプルなシングルチップデバイスにすることができ、システムのコストとそのメンテナンスのコストにプラスの影響を与えます。
DSAテクノロジーの本質は、ネットワーク全体のノード内、および実際にはすべてのノードのポート容量全体内の追加レベルのアドレス指定の導入に簡単に還元できます。 この技術の例として、スイッチチップのメーカーの1つであるMarvellの分散スイッチアーキテクチャの実装を検討してください。 さまざまなベンダーからこのテクノロジーの実装が多数ありますが(メーカーによってこのテクノロジーの呼び方は異なります)、これらのソリューションの本質は似ています。
このテクノロジーを正常に動作させるために、各ノードスイッチには一意のデバイスIDが割り当てられ、個々のデバイスの各ポートにはポートIDが割り当てられます。 このノード内で処理できない(つまり、ローカルテーブルとルールに基づいて)ネットワークノードの外部ポートに入る各パケットは、4バイトで補完されます:DSAタグ。 通常のトラフィックの場合、MarvellデバイスはForward DSAタグを使用します。 デバイスIDとポートIDがこのタグに配置され、パケットがネットワーク内のどこに正確に入ったかを一意に決定します。 タグ自体は、MACヘッダーの送信元アドレスの直後に配置されます。

MarvellのDSA実装は802.1Qをサポートしています-パケットにVLANヘッダーがある場合、VIDと優先度はDSAヘッダーに転送されますが、VLANヘッダーはパケットから削除されます。つまり、パケットサイズは変更されません。 新しいヘッダーの特別なフラグは、ソースパケットにタグが付けられたことを示します。これにより、必要に応じて外部ポートからの出力でVLANヘッダーを復元できます。 パケットの優先度を転送する場合、特別な置換テーブルを使用できます。したがって、パケットの分配を順番に設定できます。
ノードのアドレス指定が存在する場合、それぞれに個別にアクセスできるため、スイッチのネットワーク全体で1つの共通制御CPUを使用できます。これは、ノードの1つのみに物理的に接続されます。 CPUはスイッチポートの1つに接続し、交換のために、追加のアドレス指定を考慮して、上記のDSAヘッダーまたは4バイト拡張ヘッダーオプションのいずれかが使用されます-Ethertype DSA、これにはethertype値も含まれます。 このイーサタイプは、管理者によって選択され、スイッチの構成、および制御CPUのカーネルモジュールで指定されます。 Ethertype DSAを使用すると、DSAタグ付きのトラフィックと通常のネットワークトラフィックの両方をポート経由で同時に送信できます。
集中管理は、複雑なデータネットワークを構築するための最も重要な条件の1つです。 MarvellのDSA実装は、From_CPUとTo_CPUの2種類のDSAタグで使用される管理フレームで、この問題を解決します。 名前が示すように、最初のタイプはCPUから管理対象ノードにパケットを転送するために使用され、2番目のタイプはノードから制御CPUに使用されます。 主な違いは、From_DSAタグがデバイスのターゲットデバイスIDとターゲットポートIDを示し、To_DSAタグがソースデバイスIDとソースポートIDを示すことです。 事実、ネットワーク内の各スイッチは、制御CPUが(直接または他のノードを介して)どのポートに接続されているかを知っているため、管理対象デバイスのみをアドレス指定するだけで十分です。
MarvellのDSAの実装の追加機能の中で、マルチチップトラフィックモニタリングにも注目できます。ネットワークノードのポートからのトラフィックは、制御CPUのポートを含む他のポートに複製できます。 同時に、任意の数のポートを監視でき、To_SnifferタイプのDSAタグを使用してソースを示します。ソースには、受信パケットのソースデバイスID、ソースポートID、VLAN番号が書き込まれます。
バージョン2.6.28以降、メインラインLinuxカーネルは、ネットワークインターフェイスでの分散スイッチアーキテクチャの使用をサポートしています。 当初、Marvellのスイッチの一部のモデルのみがサポートされていましたが、その後Broadcomチップのサポートも追加されました。 Micrelからのスイッチをサポートするパッチもあります。 サポートは、ネットワークスタック内の追加レイヤーで構成され、パッケージに追加またはパッケージからDSAヘッダーを削除し、ヘッダーデータに応じて仮想ネットワークインターフェイスにデータを送信します。 したがって、オペレーティングシステムの観点からは、すべてのDSAネットワークスイッチの各外部ポート(スイッチを相互に接続するDSAポートを除く)は、個別のネットワークインターフェイスとして「表示」されます。 機器側からのサポートがある場合、そのようなインターフェイスには独自のMACアドレスとIPアドレスを割り当てることができます。つまり、DSAを使用すると、大きなポート容量を持つルーターを構築できます。
異なるベンダーのDSA実装は相互に互換性がなく、機能も異なることに注意してください。 したがって、たとえば、Micrel KSZ8993Mは、制御CPUに直接接続されている1つのデバイスのポート番号のみを追加でアドレス指定できます。 したがって、説明されているテクノロジーを使用してネットワークを使用する場合、いずれかのチップメーカーを選択する必要があります。
カーネル3.10以降のデバイスツリー構成でのDSA記述の例を考えてみましょう。
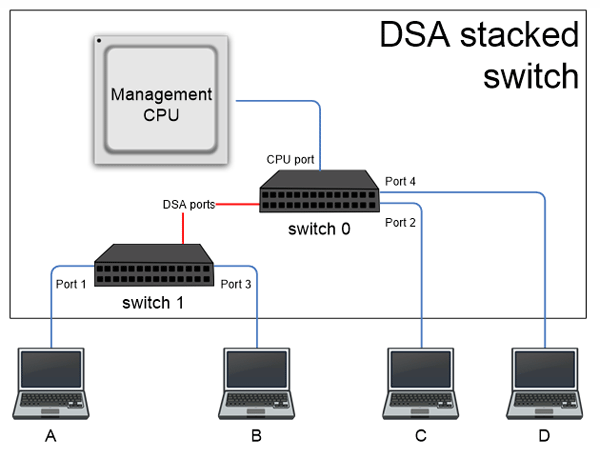
dsa@0 { compatible = "marvell,dsa"; #address-cells = <2>; #size-cells = <0>; interrupts = <10>; dsa,ethernet = <ðernet0>; dsa,mii-bus = <&mii_bus0>; switch@0 { #address-cells = <1>; #size-cells = <0>; reg = <16 0>; /* MDIO address 16, switch 0 in tree */ port@2 { reg = <2>; label = "lan2"; }; port@4 { reg = <4>; label = "lan4"; }; port@5 { reg = <5>; label = "cpu"; }; switch0uplink: port@6 { reg = <6>; label = "dsa"; link = <&switch1uplink>; }; }; switch@1 { #address-cells = <1>; #size-cells = <0>; reg = <17 1>; /* MDIO address 17, switch 1 in tree */ port@1 { reg = <1>; label = "lan1"; }; port@3 { reg = <3>; label = "lan3"; }; switch1uplink: port@5 { reg = <5>; label = "dsa"; link = <&switch0uplink>; }; };
この場合、次のように表すことができる2つのスイッチのアーキテクチャが説明されています。
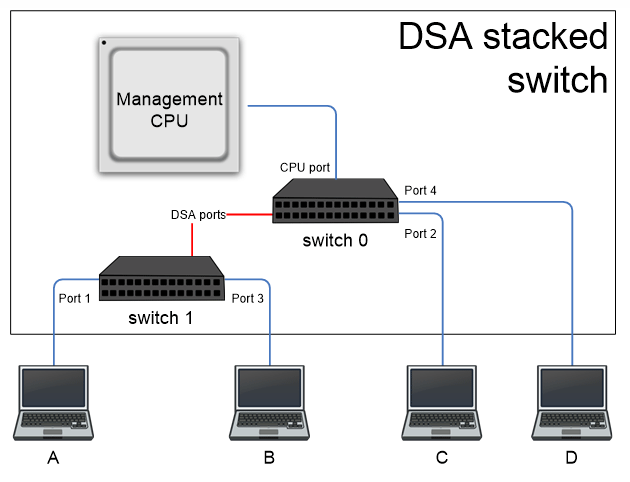
この構成では2つのスイッチに2つの外部ポートが定義されているため、オペレーティングシステムは4つの仮想ネットワークインターフェイスを追加で作成します。仮想ネットワークインターフェイスは、コンピューターA、B、C、Dを含むポートであり、それぞれ個別に使用できます。 この場合、デフォルトでは、各スイッチのポートごとに、個別の独立したMACテーブルが割り当てられます。
この場合、個々のスイッチの構成は、MDIOバスを介してローカルで実行できます(たとえば、すべての機器が1つのユニット内にある場合、またはチップが同じプリント基板上にある場合)。また、イーサネットネットワーク経由で特別な構成パケットを使用することもできます。 これにより、大きなポート容量を備えたスイッチと、集中管理された複雑なスイッチネットワークの両方を構築できます。
カーネルでのDSAの現在の実装は、MDIOバスを介してのみスイッチの構成をサポートしているため、テクノロジの使用範囲がいくぶん狭くなることに注意してください。 ただし、必要に応じてリモートコントロールを追加するのは簡単です。
これについては、Distributed Switch Architectureの説明の理論的な部分は完全であると見なすことができます。次回は、この技術を実際に使用する方法を考えます。 ネットワーキングテクノロジーと電子機器の開発があなたのテーマである場合、Habréのサブスクライバーに参加してください 。