 おそらく、主要なクラウドプロバイダーであるAmazon Web Servicesは、主にEC2(仮想インスタンス)とELB(バランサー)に関連付けられています。 Webサービスの典型的なデプロイメントスキームは、バランサー(Elastic Load Balancer)の背後にあるEC2インスタンスです。このアプローチには多くの利点があります。特に、ノードの状態、監視(リクエスト、ログの数)スケーリングなど しかし、常にそうではありませんが、ELBは負荷分散に最適な選択肢であり、場合によってはまったく適切なツールではありません。
おそらく、主要なクラウドプロバイダーであるAmazon Web Servicesは、主にEC2(仮想インスタンス)とELB(バランサー)に関連付けられています。 Webサービスの典型的なデプロイメントスキームは、バランサー(Elastic Load Balancer)の背後にあるEC2インスタンスです。このアプローチには多くの利点があります。特に、ノードの状態、監視(リクエスト、ログの数)スケーリングなど しかし、常にそうではありませんが、ELBは負荷分散に最適な選択肢であり、場合によってはまったく適切なツールではありません。
カットの下で、Elastic Load Balancerの代わりにRoute 53を使用する2つの例を示します。1つ目はLogglyの経験から、2つ目は私の個人的な経験からです。
Loggly
Loggly-ログの集中収集と分析のためのサービス。 AWSクラウドにデプロイされたインフラストラクチャ。 ログの収集に関する主な作業は、いわゆるコレクター(TCP、UDP、HTTP、HTTPSを介してクライアントから情報を受け取るC ++で記述されたアプリケーション)によって実行されます。 コレクターの要件は非常に深刻です。できるだけ早く作業し、単一のパッケージを失うことはありません! つまり、アプリケーションは、着信トラフィックの強度にかかわらず、すべてのログを収集する必要があります。 当然、コレクタは水平方向にスケーリングされ、コレクタ間のトラフィックは均等に分散される必要があります。
最初のパンケーキはゴツゴツしている
Logglyのメンバーは、最初にバランシングにELBを使用することに決めました。
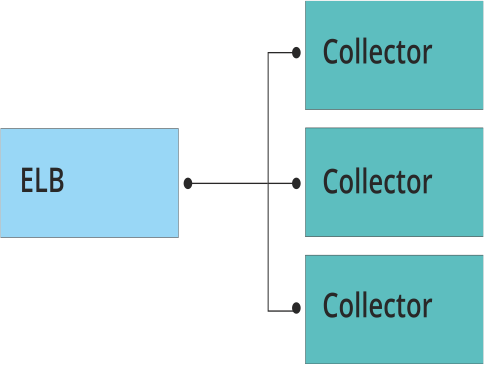
彼らが最初に遭遇した問題はパフォーマンスでした。 1秒間に数万のイベントが発生したため、バランサーの遅延が増加し始めましたが、これはコレクターの目的に匹敵しませんでした。 熟したリンゴのようにさらに雨が降る問題:ポート514にトラフィックを転送することは不可能です。UDPはサポートされていません。よく知られている「コールドバランサー」のよく知られている問題
Route53での交換
それから彼らは代わりのELBを探し始めました。 単純なDNSラウンドロビンが完全に満たされ、Route53がトラフィック分散の問題を解決し、ELBの問題を解消することが判明しました。 バランサーの形式の中間リンクがない場合、トラフィックがクライアントからコレクターを持つインスタンスに直接移動し始めたため、遅延は減少しました。 メッセージの量が急激に増加しても、追加の「ウォームアップ」は必要ありません。 Route53は、コレクターの「正常性」もチェックし、システム全体の可用性を高め、情報損失をゼロに抑えます。
おわりに
さまざまなプロトコルとポートを使用するリクエスト数が急激に変動する負荷の高いサービスの場合、ELBを使用しないでください。遅かれ早かれ、制限と問題が発生します。
ペルコナクラスター
インフラストラクチャでは、メインデータウェアハウスはPercona Clusterです。 多くのアプリケーションで使用されています。 主な要件は、フォールトトレランス、パフォーマンス、およびそれをサポートするための最小限の労力でした。 私は一度それをやりたいと思っていました。
アプリケーション側では、各環境(dev、test、live)に一定のDNS名を使用してクラスターと通信することにしました。 これにより、アプリケーションの構成とアセンブリにおいて、開発者と彼ら自身の生活が楽になりました。
ELBは適合しませんでした
Logglyの場合とほぼ同じ理由で、バランサーは私たちに適合しませんでした。 特に、Perconaはまさにそのようなソリューションを使用することをお勧めしているため、HA Proxyをロードバランサーとして考えました。 しかし、HAプロキシサーバーの形でもう1つの障害ポイントを受け取りたくありませんでした。 さらに、メンテナンスと管理の追加コストを必要とする人はいません。
Route53 +パーコナ
ロードバランサーとしてこのサービスに注意を払い、クラスターサーバーの状態を確認すると、数回クリックするだけで目的の結果が得られるように見えました。 しかし、ドキュメントの詳細な調査の後、彼らは環境とその中のクラスターのアーキテクチャ全体を削減する根本的な制限を発見しました。 実際、Percona Clusterは、他のほとんどのサーバーと同様に、プライベートサブネットにあり、Route 53はパブリックアドレスのみをチェックできます!
失望は長続きしませんでした-新しいアイデアが浮上しました:自分で状態をチェックし、Route 53 APIを使用してDNSレコードを更新することです。
最終決定
プロジェクトでは、システムサービスを監視するためにあらゆる場所でMonitが使用されています。 次の自動アクション用に構成されました。
- MySQLポートチェック
- 応答がない場合にDNSレコードを変更する
- 通知送信
- サービスを再起動しようとしました
クラスターノードの1つがクラッシュすると、この動作が発生します。サポートサービスが通知を受信し、影響を受けるノードが要求を受信しないようにDNSレコードが変更され、monitdがサービスの再起動を試みます。 問題を知らなくても、アプリケーションは何も起こらなかったように動作し続けます。
おわりに
記事で説明されている2つのケースは、ルート53がELBよりも負荷分散とフォールトトレランスに適している場合があることを示しています。 同時に、クラウドプロバイダーAPIを使用すると、サービスの多くの制限を回避できます。