
恐怖を払拭し、非識字を排除し、鉄生まれの象に関する神話を破壊します。 ネコの下で、Hadoopエコシステムの概要、開発動向、および個人的な意見を少し。
サプライヤー:Apache、Cloudera、Hortonworks、MapR
HadoopはApache Software Foundationのトップレベルプロジェクトであるため、Apache Hadoopはすべての開発の主要なディストリビューションおよび中央リポジトリと見なされます。 ただし、この同じ分布は、このツールに精通している大部分の火傷した神経細胞の主な理由です:デフォルトでは、象をクラスターにインストールするためには、マシンの予備設定、パッケージの手動インストール、多くの設定ファイルの編集、およびその他の体の動きが必要です。 ただし、多くの場合、ドキュメントは不完全であるか、単に古くなっています。 したがって、実際には、次の3つの会社のいずれかのディストリビューションが最もよく使用されます。
Cloudera 。 主要製品-CDH(Apache Hadoopを含むClouderaディストリビューション)-Cloudera Managerを実行しているHadoopインフラストラクチャの最も人気のあるツールの束。 マネージャーは、クラスターの展開、すべてのコンポーネントのインストール、およびそれらのさらなる監視を担当します。 CDHに加えて、同社はImpalaなどの他の製品も開発しています(詳細は以下を参照)。 Clouderaの特徴は、安定性を犠牲にしても、市場で新機能を最初に提供することです。 確かに、Hadoopの作成者であるDoug CuttingはClouderaで働いています。
Hortonworks 。 Clouderaと同様に、HDP(Hortonworks Data Platform)の形式で単一のソリューションを提供します。 彼らの際立った特徴は、独自の製品を開発する代わりに、Apache製品の開発により多く投資することです。 たとえば、Cloudera Managerの代わりに、Apache Ambariを使用し、Impalaの代わりに、Apache Hiveをさらに開発します。 このディストリビューションでの個人的な経験は、仮想マシンでの2、3のテストに帰着しますが、HDPはCDHよりも安定しているように感じます。
MapR 明らかに、コンサルティングおよびアフィリエイトプログラムが主な収益源である2つの以前の企業とは異なり、MapRは開発の販売に直接関与しています。 プロから:多くの最適化、Amazonとのアフィリエイトプログラム。 マイナスのうち、無料版(M3)には機能が切り捨てられています。 さらに、MapRは、Apache Drillの主要なイデオロギー家であり、チーフ開発者でもあります。
基盤:HDFS
Hadoopについて話すとき、主にそのファイルシステム-HDFS(Hadoop分散ファイルシステム)を意味します。 HDFSについて考える最も簡単な方法は、通常のファイルシステムを想像することです。 一般的なファイルシステムは、概して、ファイル記述子テーブルとデータ領域で構成されています。 HDFSでは、テーブルの代わりに特別なサーバー-ネームサーバー(NameNode)が使用され、データはデータサーバー(DataNode)に散在しています。
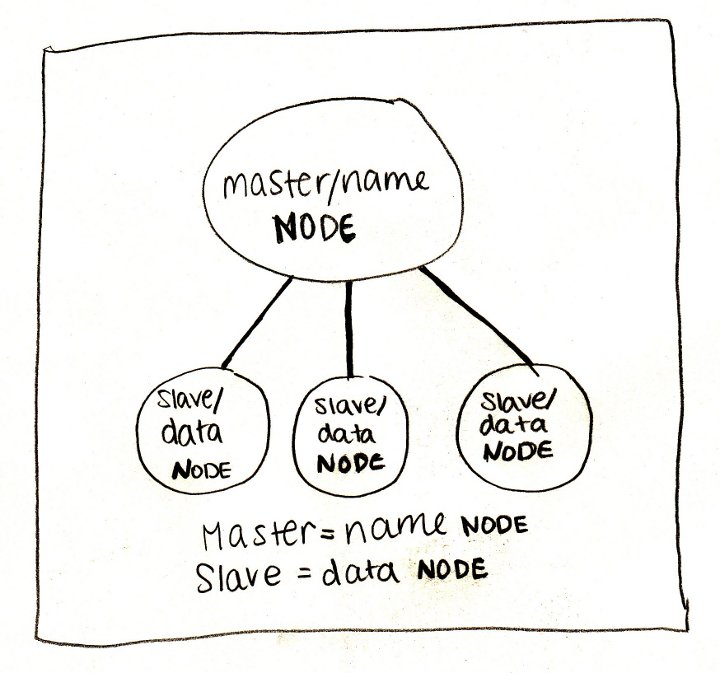
それ以外の場合、違いはそれほど多くありません。データはブロック(通常64 MBまたは128 MB)に分割され、ファイルごとにネームサーバーがパス、ブロックのリスト、およびレプリカを保存します。 HDFSは、ディレクトリ、トリプルの権限を持つユーザー、さらには同様のコンソールコマンドセットの、古典的なUNIXツリー構造を持っています。
# : HDFS ls / hadoop fs -ls / # du -sh mydata hadoop fs -du -s -h mydata # cat mydata/* hadoop fs -cat mydata/*
HDFSがとてもクールなのはなぜですか? まず、信頼性が高いためです。何らかの理由で、IT機器が再配置されたときに、IT部門が誤ってサーバーの50%を破壊しましたが、データの3%のみが完全に失われました。 第二に、さらに重要なことは、ネームサーバーがすべてのユーザーのマシン上のデータブロックの場所を明らかにすることです。 これが重要な理由は、次のセクションを参照してください。
エンジン:MapReduce、Spark、Tez
アプリケーションの正しいアーキテクチャを使用すると、データブロックが配置されているマシンに関する情報を使用して、それらで計算プロセス(「ワーカー」と呼びます)を実行し、ほとんどの計算をローカルで実行できます。 ネットワークを介したデータ伝送なし。 MapReduceパラダイムとHadoopでの具体的な実装の根底にあるのは、この考えです。
従来のHadoopクラスター構成は、1つのネームサーバー、1つのMapReduceウィザード(いわゆるJobTracker)、および一連の作業マシンで構成され、それぞれがデータサーバー(DataNode)とワーカー(TaskTracker)を同時に実行します。 MapReduceの各作業は、2つのフェーズで構成されています。
- map-各データブロックでローカルに(可能であれば)並行して実行します。 テラバイトのデータをプログラムに配信する代わりに、小さなユーザー定義プログラムがデータとともにサーバーにコピーされ、データのシャッフルと移動(シャッフル)を必要としないすべての処理が行われます。
- reduce-集約操作でマップを補足します
実際、これらのフェーズの間には、 reduceと同じですが、ローカルデータブロックの上にある結合フェーズもあります。 たとえば、エラーメッセージを解析および抽出するために必要な5テラバイトのメールサーバーログがあるとします。 ラインは互いに独立しているため、それらの分析はマップタスクにシフトできます。 次に、 結合を使用して、単一サーバーレベルでエラーメッセージを含む行をフィルター処理し、 reduceを使用してすべてのデータのレベルで同じ処理を実行できます。 並列化できるすべてのものを並列化し、さらに、サーバー間のデータ転送を最小限に抑えました。 何らかの理由で何らかのタスクがクラッシュした場合でも、Hadoopは自動的に再起動し、ディスクから中間結果を取得します。 かっこいい!
問題は、ほとんどの実際のタスクが単一のMapReduceジョブよりもはるかに複雑であることです。 ほとんどの場合、並列操作を行い、順次、次に並列を実行し、複数のデータソースを組み合わせて、再度並列操作と順次操作を行います。 標準のMapReduceは、最終結果と中間結果の両方の結果がすべてディスクに書き込まれるように設計されています。 その結果、問題の解決に行われた回数を掛けたディスクへの読み取りと書き込みの時間は、多くの場合数回です(はい、数回、最大100回です!)計算自体の時間を超えています。
そして、ここにスパークが来ます。 バークレー大学のスタッフによって設計されたSparkは、データの局所性の概念を使用しますが、ほとんどの計算をディスクではなくメモリに格納します。 Sparkの重要な概念はRDD(復元性のある分散データセット)-遅延分散データコレクションへのポインターです。 RDDでのほとんどの操作は計算につながりませんが、次のラッパーを作成するだけで、必要な場合にのみ操作を実行することを約束します。 ただし、これは伝えるよりも表示する方が簡単です。 以下は、ログの問題を解決するためのPythonスクリプト(Spark、Scala、Java、Pythonのインターフェイスをサポートするスパーク)です。
sc = ... # (SparkContext) rdd = sc.textFile("/path/to/server_logs") # rdd.map(parse_line) \ # .filter(contains_error) \ # .saveAsTextFile("/path/to/result") #
この例では、実際の計算は最後の行でのみ開始されます。Sparkは結果を具体化する必要があることを認識し、そのためにデータに操作を適用し始めます。 同時に、中間段階はありません。各行がメモリに持ち込まれ、逆アセンブルされ、メッセージのエラーの兆候がチェックされます。そのような兆候がある場合は、すぐにディスクに書き込まれます。
このようなモデルは非常に効果的で便利であることが判明したため、Hadoopエコシステムのプロジェクトは1つずつ計算をSparkに転送し始め、現在では廃止されたMapReduceよりも多くの人がエンジン自体に取り組んでいます。
しかし、Sparkのものではありません。 Hortonworksは、代替エンジンであるTezに焦点を合わせることにしました。 Tezは、タスクをハンドラーコンポーネントの有向非循環グラフ(DAG)として提示します。 スケジューラはグラフの計算を開始し、必要に応じて動的に再構成し、データを最適化します。 これは、Tezが最大100倍の加速を実現したHiveのSQLのようなスクリプトなど、複雑なデータクエリを実行するための非常に自然なモデルです。 ただし、Hive以外に、このエンジンはまだ広く使用されていないため、より単純で一般的なタスクに適していると言うのは非常に困難です。
SQL:Hive、Impala、Shark、Spark SQL、Drill
Hadoopはあらゆるアプリケーションを開発するための完全なプラットフォームであるという事実にもかかわらず、ほとんどの場合、データストレージ、特にSQLソリューションのコンテキストで使用されます。 実際、これは驚くべきことではありません。大量のデータはほとんどの場合分析を意味し、表形式のデータの分析ははるかに簡単です。 さらに、SQLデータベースの場合、NoSQLソリューションの場合よりもツールと人の両方を見つける方がはるかに簡単です。 Hadoopインフラストラクチャには、SQL指向のツールがいくつかあります。
Hiveは、このプラットフォームで最も人気のあるDBMSの1つ目であり、今でもまだ1つです。 HiveQLをクエリ言語として使用します。クエリ言語はSQLの短縮された方言ですが、HDFSに格納されたデータに対してかなり複雑なクエリを実行できます。 ここでは、Hive <= 0.12のバージョンと現在のバージョン0.13の間に明確な線を引く必要があります:先ほど述べたように、最新バージョンでは、Hiveは古典的なMapReduceから新しいTezエンジンに切り替え、何度も加速し、インタラクティブな分析に適したものにします。 つまり 1つの小さなパーティションのレコード数を計算するのに2分待つ必要も、1週間の日ごとにデータをグループ化するのに40分待つ必要もありません(さようなら長い休憩!)。 さらに、HortonworksとClouderaの両方がODBCドライバーを提供しているため、Tableau、Micro Strategy、さらには(神は禁じられている)Microsoft ExcelなどのツールをHiveに接続できます。
ImpalaはCloudera製品であり、Hiveの主要なライバルです。 後者とは異なり、Impalaは従来のMapReduceを使用したことはありませんが、最初は独自のエンジンでクエリを実行しました(Hadoop C ++の非標準で作成されました)。 さらに、最近Impalaは頻繁に使用されるデータブロックと列ストレージ形式のキャッシュを積極的に使用しており、これは分析クエリのパフォーマンスに非常に良い影響を与えます。 Hiveと同様に、Clouderaはその子孫に非常に効果的なODBCドライバーを提供します。
サメ 。 Sparkが革新的なアイデアでHadoopエコシステムに参入したとき、自然な欲求は、それに基づいたSQLエンジンを取得することでした。 これにより、愛好家によって作成されたSharkというプロジェクトが作成されました。 ただし、Spark 1.0では、Sparkチームが独自のSQLエンジンの最初のバージョンであるSpark SQLをリリースしました。 これ以降、Sharkは停止したと見なされます。
Spark SQLは、Sparkに基づいたSQL開発の新しいブランチです。 正直なところ、これを以前のツールと比較することは完全に正しいわけではありません。SparkSQLには独立したコンソールと独自のメタデータリポジトリがなく、SQLパーサーは依然としてかなり弱く、パーティションは明らかにまったくサポートされていません。 どうやら、現時点では、彼の主な目標は、複雑な形式(Parquetなど、以下を参照)からデータを読み取り、プログラムコードではなくデータモデルの形でロジックを表現できるようにすることです。 正直なところ、これはそれほど多くありません! 多くの場合、処理パイプラインは、SQLクエリとプログラムコードを交互に組み合わせて構成されています。 Spark SQLを使用すると、黒魔術に頼らずにこれらの段階をシームレスに関連付けることができます。
Hive on Spark-そのようなことはありますが、明らかに、バージョン0.14より前には動作しません。
ドリル 図を完成させるには、Apache Drillに言及する必要があります。 このプロジェクトは依然としてASFインキュベーター内にあり、広くは普及していませんが、明らかに、主な重点は半構造化された埋め込みデータに置かれます。 HiveおよびImpalaでは、JSON文字列を使用することもできますが、クエリのパフォーマンスは大幅に低下します(多くの場合、最大10〜20倍)。 Hadoopに基づく別のDBMSの作成が何をもたらすかを言うのは難しいですが、待って見てみましょう。
個人的な経験
特別な要件がない場合は、このリストの2つの製品(HiveとImpala)のみを真剣に検討できます。 どちらも十分に高速で(最新バージョンでは)、機能が豊富で、積極的に開発中です。 ただし、Hiveにはより多くの注意と注意が必要です。スクリプトを正しく実行するには、多くの場合、多数の環境変数を設定する必要があります。HiveServer2の形式のJDBCインターフェイスは率直に動作が悪く、スローされるエラーは問題の実際の原因とはほとんど関係ありません。 Impalaも不完全ですが、全体的にははるかに優れており、予測可能です。
NoSQL:HBase
Hadoopに基づくSQL分析ソリューションの人気にもかかわらず、NoSQLデータベースがより適している他の問題に対処する必要がある場合があります。 さらに、HiveとImpalaは両方とも大きなデータパケットでより適切に動作し、個々の行の読み取りと書き込みはほとんどの場合、オーバーヘッドが大きくなります(データブロックサイズは64 MBであることを思い出してください)。
そして、ここでHBaseが助けになります。 HBaseは、ランダムな読み取りと書き込みを効果的にサポートする、分散バージョンの非リレーショナルDBMSです。 ここでは、HBaseのテーブルが3次元(文字列キー、タイムスタンプ、修飾列名)であり、キーが辞書式順序でソートされて保存されていることなどがわかりますが、主なことは、HBaseを使用すると個々のレコードをリアルタイムで操作できることです。 これは、Hadoopインフラストラクチャへの重要な追加です。 たとえば、ユーザーに関する情報(プロファイルとすべてのアクションのログ)を保存する必要があるとします。 アクションログは分析データの典型的な例です:アクション、つまり 実際、イベントは一度記録され、再び変更されることはありません。 アクションは、たとえば1日に1回など、いくつかの間隔でバッチで分析されます。 ただし、プロファイルはまったく別の問題です。 プロファイルは、常にリアルタイムで更新する必要があります。 そのため、イベントログにはHive / Impalaを使用し、プロファイルにはHBaseを使用します。
これらすべてにより、HBaseはHDFSに基づいているため、信頼性の高いストレージを提供します。 停止しますが、データブロックサイズが大きいため、このファイルシステムではランダムアクセス操作が効率的でないと言っただけではありませんか? そうです、これがHBaseの大きなトリックです。 実際、メモリ内のソートされた構造に新しいレコードが最初に追加され、この構造が特定のサイズに達すると、ディスクにフラッシュされます。 一貫性は、ディスクに直接書き込まれる先書きログ(WAL)を犠牲にして維持されますが、もちろん、ソートされたキーのサポートは必要ありません。 詳細については、 Clouderaブログをご覧ください。
そうそう、HiveとImpalaから直接HBaseテーブルをクエリできます。
データのインポート:Kafka

通常、Hadoopへのデータのインポートは、いくつかの進化段階を経ます。 最初に、チームは通常のテキストファイルで十分であると判断しました。 誰もがCSVファイルを読み書きする方法を知っているので、問題はないはずです! 次に、どこかから印刷不能で非標準の文字が表示されます(やつが挿入したもの!)、文字列などのエスケープの問題など、バイナリ形式または少なくとも余剰のJSONに切り替える必要があります。 その後、20個のクライアント(外部または内部)が表示されますが、誰もがファイルをHDFSに送信するのは便利ではありません。 この時点で、RabbitMQが表示されます。 しかし、うさぎがすべてを記憶に残そうとしていることを誰もが突然思い出し、大量のデータがあり、それらをすぐに収集することが常に可能であるとは限らないため、彼は長続きしません。
そして、誰かが高帯域幅の分散メッセージングシステムであるApache Kafkaに出くわします。 HDFSインターフェースとは異なり、Kafkaはシンプルで使い慣れたメッセージングインターフェースを提供します。 RabbitMQとは異なり、メッセージを即座にディスクに書き込み、設定された期間(2週間など)をそこに保存します。この期間中にデータを収集できます。 Kafkaは簡単にスケーリングでき、理論的にはあらゆる量のデータを表現できます。
この美しい画像はすべて、実際にシステムを使用し始めると崩壊します。 カフカを扱うときに覚えておくべき最初のことは、誰もが嘘をついているということです。 特にドキュメント。 特に公式。 著者が「Xをサポートしています」と書いている場合、これは「Xをサポートしたい」または「Xをサポートする予定の将来のバージョン」を意味することがよくあります。 「サーバーがYを保証する」と表示されている場合、「サーバーがYを保証しているが、クライアントZのみを保証している」ことを意味します。 1つはドキュメントに記述され、もう1つは関数の解説に記述され、3つ目はコード自体に記述されている場合がありました。
Kafkaはマイナーバージョンでもメインインターフェイスを変更し、長い間0.8.xから0.9に移行できません。 ソースコード自体は、構造的にもスタイルレベルでも、このモンスターに名前を付けた有名な作家の影響下で明確に記述されています。
そして、これらすべての問題にもかかわらず、Kafkaは、大量のデータをインポートする問題を解決するアーキテクチャレベルでの唯一のプロジェクトのままです。 したがって、まだこのシステムに連絡することにした場合は、いくつかのことを覚えておいてください。
- Kafkaは信頼性について嘘をつきません。メッセージがサーバーに届くと、指定された時間だけそこに残ります。 データがない場合は、コードを確認してください。
- コンシューマーグループは機能しません。構成に関係なく、パーティションからのすべてのメッセージは接続されているすべてのコンシューマーに送信されます。
- サーバーはユーザーのオフセットを保存しません。 サーバーは一般に、実際には接続されたコンシューマーを識別できません。
徐々にやってきた簡単なレシピは、パーティションラインごとに1つのコンシューマーを開始し(トピック、Kafkaの用語で)、シフトを手動で制御することです。
ストリーム処理:Spark Streaming
この段落まで読んでいただければ、おそらく興味があるでしょう。 興味があれば、おそらくラムダアーキテクチャについて聞いたことがあるかもしれませんが、 念のため 、繰り返します。 Lambdaアーキテクチャには、バッチおよびストリーミングデータ処理の計算パイプラインの複製が含まれます。 バッチ処理は過去の期間(たとえば昨日)に定期的に開始され、最も完全で正確なデータを使用します。 対照的に、ストリーム処理はリアルタイムの計算を生成しますが、正確性を保証するものではありません。 これは、たとえば、プロモーションを開始し、その有効性を1時間ごとに追跡する場合に役立ちます。 ここでは1日の遅延は許容されませんが、イベントの数パーセントの損失は重大ではありません。
Spark Streamingは、Hadoopエコシステムでのデータのストリーム処理を担当します。 ボックスからのストリーミングは、Kafka、ZeroMQ、ソケット、Twitterなどからデータを取得できます。開発者には、DStreamの形式で便利なインターフェイスが提供されます。実際、一定期間(たとえば、30秒または5分) ) 通常のRDDのパンはすべて保存されます。
機械学習

上の写真は、多くの企業の状態を完全に表しています。誰もがビッグデータが良いことを知っていますが、それをどうするかを本当に理解している人はほとんどいません。 そして、まず最初に2つのことを行う必要があります-知識に変換し(方法を読む:意思決定時に使用する)、アルゴリズムを改善します。 分析ツールは最初のツールで既に役立ち、2番目のツールは機械学習になります。 このためのHadoopには2つの主要なプロジェクトがあります。
Mahoutは、MapReduceを使用して多くの一般的なアルゴリズムを実装した最初の大きなライブラリです。 クラスタリング、協調フィルタリング、ランダムツリーのアルゴリズム、および行列の因数分解のためのいくつかのプリミティブが含まれます。 今年の初めに、主催者はすべてをApache Sparkコンピューティングコアに転送することを決定しました。これは、反復アルゴリズムをよりよくサポートします(標準のMapReduceを使用して、ディスク全体で30回の勾配降下を試行します)
MLlib アルゴリズムを新しいカーネルに移植しようとしているMahoutとは異なり、MLlibは当初はSparkサブプロジェクトです。 基本統計、線形およびロジスティック回帰、SVM、k-means、SVDおよびPCA、SGDやL-BFGSなどの最適化プリミティブが含まれます。 Scalaインターフェイスは線形代数にBreezeを使用し、PythonインターフェイスはNumPyです。 このプロジェクトは積極的に開発されており、リリースごとに機能が大幅に追加されています。
データ形式:Parquet、ORC、Thrift、Avro
Hadoopを最大限に使用することに決めた場合は、データストレージとデータ転送の主要なフォーマットに慣れることは問題ありません。
寄木細工は、複雑な構造と効率的な圧縮を保存するために最適化された円柱形式です。 当初はTwitterで開発されましたが、現在はHadoopインフラストラクチャの主要な形式の1つです(特に、SparkとImpalaで積極的にサポートされています)。
ORCは、Hive用の新しい最適化されたストレージ形式です。 ここでも、Cloudera c ImpalaとParquet、HortonworksとHiveとORCの対立が見られます。 最も興味深い読み物は、ソリューションのパフォーマンスの比較です。Clouderaブログでは、Impalaが常に大きなマージンで勝ち、Hortonworksブログでは、ご想像のとおり、Hiveが勝ち残ります。
Thriftは効果的ですが、あまり便利ではないバイナリデータ転送形式です。 この形式を使用するには、データスキームを定義し、必要な言語で適切なクライアントコードを生成する必要がありますが、これは常に可能とは限りません。最近、彼らはそれを拒否し始めましたが、多くのサービスはまだそれを使用しています。
Avro-基本的にThriftの代替として位置付けられています。コード生成を必要とせず、スキームをデータとともに転送したり、動的に型指定されたオブジェクトを操作したりすることもできます。
その他:ZooKeeper、Hue、Flume、Sqoop、Oozie、Azkaban
最後に、他の便利で役に立たないプロジェクトについて簡単に説明します。
ZooKeeperは、Hadoopインフラストラクチャのすべての要素の主要な調整ツールです。ほとんどの場合、構成サービスとして使用されますが、その機能ははるかに広くなっています。シンプル、便利、信頼できる。
Hueは、Cloudera Managerの一部であるHadoopサービスへのWebベースのインターフェースです。エラーとムードがあり、うまく機能しません。技術者以外の専門家への表示に適していますが、本格的な作業にはコンソールアナログを使用することをお勧めします。
水路-データフローを整理するためのサービス。たとえば、syslogからメッセージを受信し、HDFS上のディレクトリに集約して自動的にドロップするように設定できます。残念ながら、多くのスレッドの手動構成と、独自のJavaクラスの継続的な拡張が必要です。
Sqoopは、HadoopとRDBMSの間でデータをすばやくコピーするためのユーティリティです。理論的には速い。実際には、Sqoop 1は本質的にシングルスレッドで低速であることが判明し、Sqoop 2は最後のテストの時点で動作しませんでした。
ウージー-タスクフロースケジューラ。元々、個々のMapReduceジョブを単一のパイプラインに結合し、スケジュールに従って実行するように設計されていました。さらに、Hive、Java、およびコンソールアクションを実行できますが、Spark、Impalaなどのコンテキストでは、このリストはかなり役に立たないように見えます。非常に壊れやすく、紛らわしく、デバッグがほとんど不可能です。
AzkabanはOozieの代わりになります。LinkedInのHadoopインフラストラクチャの一部です。主なものはコンソールコマンド(および他に必要なもの)、スケジュールされた起動、アプリケーションログ、削除された作業の通知など、いくつかのタイプのアクションをサポートします。 UIを使用して作成し、テキストファイルを含むzipアーカイブとしてアップロードします)。
それだけです みんなありがとう、みんな無料です。