この記事には含まれません:クラスタリングアルゴリズム、品質分析、ライブラリの比較については説明しません。 この記事で行われること:特定のタスクの例で、クラスター化(写真付き)とは何か、本当に大量のデータがある場合(実際には非常に多い場合)にそれを行う方法、および結果として何が起こるかを示します。

だから挑戦。 OK.RUソーシャルネットワークのユーザーは、他の多くのネットワークと同様に、お互いにかわいいプレゼントを贈る機会があります。 そのような贈り物は一定の利益をもたらすので、私はそれを最大限に活用したいと思います。 最大化する1つの明白な方法は、優れた推奨システムを構築することです。
OK.RUのギフトの意味でこれはどういう意味ですか? N人の異なるギフトが毎日M人の異なるユーザーから与えられ、休日にはギフトの数が10倍に増えます。 ご想像のとおり、NとMは非常に大きいため、Hadoopを使用してこのデータを保存および処理します。
明らかに、ギフトのギフト数の分布は、多くの同様の分布のように、Zipfの法則を満たしているため、ギフトのマトリックスは非常にまばらです。 この点で、推奨事項のために各ギフトを個別に検討することは事実上不可能であり、これはクラスタリングのアイデアを示唆しています。 クラスタリングが最良である、または特に唯一の正しい方法であると言うつもりはありませんが、記事の終わりまでに、なぜ私がそれが好きなのか理解できることを願っています。
ギフトをクラスター化するのはなぜですか?また、ギフトの類似性をどのように理解していますか? 最初の質問に対する答えはほぼ次のとおりです。ギフトのクラスターが個別のギフトの代わりになる場合、各オブジェクトのギフトの数を増やし、そのようなオブジェクトの数を減らします。 これは、より多くの統計とより少ない次元を意味します。 2番目の質問には100万の回答がありますが、特定の質問が1つ大好きです。ユーザーが2つのギフトを贈った場合、それらはいくらか似ています。

この定式化の単純さの背後には、色の好み、個人的な興味、個人的な資質、および同様のユーザー特性について考えることができるすべてのものがあります。 もちろん、1人の特定のユーザーと2人の贈り物を受け取った場合、彼は猫を愛しているので1人、そしてもう1人はおなじみの金属バイカーの誕生日に頭蓋骨の形で贈ったことがわかります。 しかし、何百万人ものユーザーがいる場合、このような組み合わせの可能性は2匹の猫と比較して大幅に減少します。 実際、ユーザーとギフトの関係は2部グラフを形成し、その1つを「共有」してクラスター化します。
これに適切な尺度を構築する方法は? そして、すべてはいつも通りです-すべては長い間私たちのために発明されました、この場合、それは特定のポール・ジャカード(英語のポール・ジャカード)によって行われました。 A-最初のギフトを提示した多くのユーザーとB-2番目のギフトを提示したとします。 その場合、類似度係数は次の式になります。
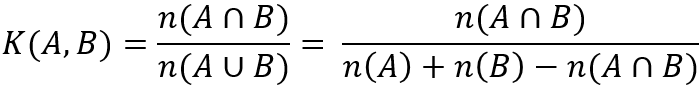
一般に、共通の類似度係数はそれほど多くありませんが、これには非常に満足しています。 「類似性」があるとすぐに、クラスタリングアルゴリズムを選択する必要があります。 多くのクラスタリングアルゴリズムでは、オブジェクトの空間的解釈が必要です。 したがって、たとえば、単純なk-meansは重心を計算できるはずです。 ただし、アルゴリズムがあり、それらの多くはペアワイズ距離が十分であり、逆にオブジェクト間の「類似性」があります。 このようなアルゴリズムには、たとえば、k-means-k-medoidsの一般化が含まれます。 もちろんインターネット上には、クラスタリングのトピックに関する記事がたくさんあり、適切なアルゴリズムを見つけることは難しくありません。
私たちの場合、要件の1つは、「おもちゃ」のデータセットだけでなく作業を可能にする既製のライブラリの可用性でした。 さらに、OK.RUユーザーの「関心」の数が事前にわからないため、クラスターの数を明示的に示したくありませんでした。 その結果、選択はMCLに委ねられました。詳細については、 こちらを参照してください 。 簡単に説明すると、MCLはファイルを入力として受け取り、その各行には2つのギフト識別子と類似性が含まれ、識別子のリストの形式で1行ずつクラスターを出力ファイルに書き込みます。
ライブラリのWebサイトでは、他の入力形式が利用可能であることや、クラスタリングオプションのリストを読むことができます。 さらに、クラスタリングアルゴリズム自体の説明と、重要なことに、RでのMCLの使用方法の説明があります。
全体として、ソリューションは次のようになります。
- ユーザーUがギフトPを贈ったという形のイベントをたくさん取ります
- ギフトのペアごとに、両方のギフトを贈ったユーザーの数を考慮します(すごい仕事だと思いますか?)。 また、各ギフトのギフトの量。
- ギフトのペアごとに、ジャカード係数を計算します。
- 受信したデータをMCLにフィードします
- ...
- 利益!!! (抵抗できなかった、ゴミ)
そして今、実際に、写真! つまり、実際のデータで取得されたクラスターの例です。 1つの画像-1つのクラスター:
花は違います 

靴と卵 

明けましておめでとうございます-ナフィグへ 
女性と子供 

丸まった署名のギフトも! 
私の意見では、この1つのクラスタリングの単純な話は、「機械学習」という言葉の背後にある力の表面的な考えを与えます。 結局のところ、本質的に、入り口には何がありますか? 1つの簡単な事実は、同じユーザーから2つのギフトが与えられたことです。 出口には何がありますか? すべてのモデレーターが選出できるわけではないセマンティクスを持つギフトクラスター。 このデータの範囲は明らかです-それはユーザーへの平凡な推奨事項であり、自動タグ付けであり、Habrに関する記事の資料です。 明らかに、ギフトは、ドメイン、検索フレーズ、店舗での購入、または観光旅行の国に置き換えることができます。 データがある場合、主なことは実験を恐れないことです。
