
郵便業者にとって、郵便局のインターフェースは完全に透過的です。 システムにドメインまたはメールを登録するだけで十分です。 このサービスは、送信者の名前とドメイン、時間、スパムの兆候/スパムではない、読み取り/未読み取りのさまざまなパラメーターのデータを収集して分析します。 list-idフィールドによる集計も実装されます-ニュースレターを識別するための特別なヘッダー。 いくつかのデータソースがあります。
まず、メタベースにレターを配信するシステム。 レターがシステムに入ったイベントを生成します。 第二に、ユーザーがメッセージの状態を変更するWebベースのメールインターフェース:読み取り、スパムとしてマーク、または削除。 これらのアクションはすべてリポジトリに移動する必要があります。
情報を保存および変更する場合、厳密な時間要件はありません。 レコードはかなりの期間追加または変更できます。 この時点で、統計はシステムの以前の状態を反映します。 大量のデータの場合、これはユーザーには見えません。 まだデータベースに入れられていない彼のアクションのうちの1つまたは2つは、統計を大きな価値に変更することはできません。
Webインターフェースでは、応答速度が非常に重要です-ブレーキングはいように見えます。 さらに、ブラウザウィンドウを更新するときに値の「ジャンプ」を防ぐことが重要です。 この状況は、一方のヘッドからデータが抽出され、もう一方のヘッドからデータが抽出されるときに発生します。
プラットフォームの選択についていくつか言いたいことがあります。 すぐに、すべてのソリューションがデータストリームに対応できるわけではないことに気付きました。 最初は、 MongoDB 、 Postgres 、独自のLucene + Zookeeperの 3つの候補がありました。 パフォーマンスが不十分だったため、最初の2つを放棄しました。 特に大きな問題は、大量のデータを貼り付けるときでした。 その結果、同僚の経験を使用することにし、Lucene + Zookeeperバンチを使用することにしました。同じバンチはYandex.Mail検索を使用します。
システム内のコンポーネント間の通信の標準はJSONです。 JavaとJavascriptには、それを操作するための便利なツールがあります。 C ++では、yajlとboost :: property_treeを使用します。 すべてのコンポーネントはREST APIを実装しています。
システム上のデータはApache Luceneに保存されます。 ご存知のように、Luceneは全文検索のためにApache Foundationによって開発されたライブラリです。 事前にインデックス付けされたデータを保存および取得できます。 私たちはそれをサーバーに変えました。データを保存し、インデックスに追加し、圧縮するように教えられました。 httpリクエストを使用して、検索、追加、変更を行うことができます。 さまざまなタイプの集約があります。
クラスターのすべての「ヘッド」で各状態変更レコードを処理するために、別のApache Fondation製品であるZookeeperが使用されます。 最終決定し、キューとして使用する機能を追加しました。
Luceneからデータを抽出および分析するための特別なデーモンが作成されています。 作業のすべてのロジックに焦点を当てています。 Webインターフェースの呼び出しは、Lucene http要求に変わります。 Webインターフェースでデータを表示するために必要なデータ集約、ソート、およびその他の処理のロジックをすぐに実装しました。
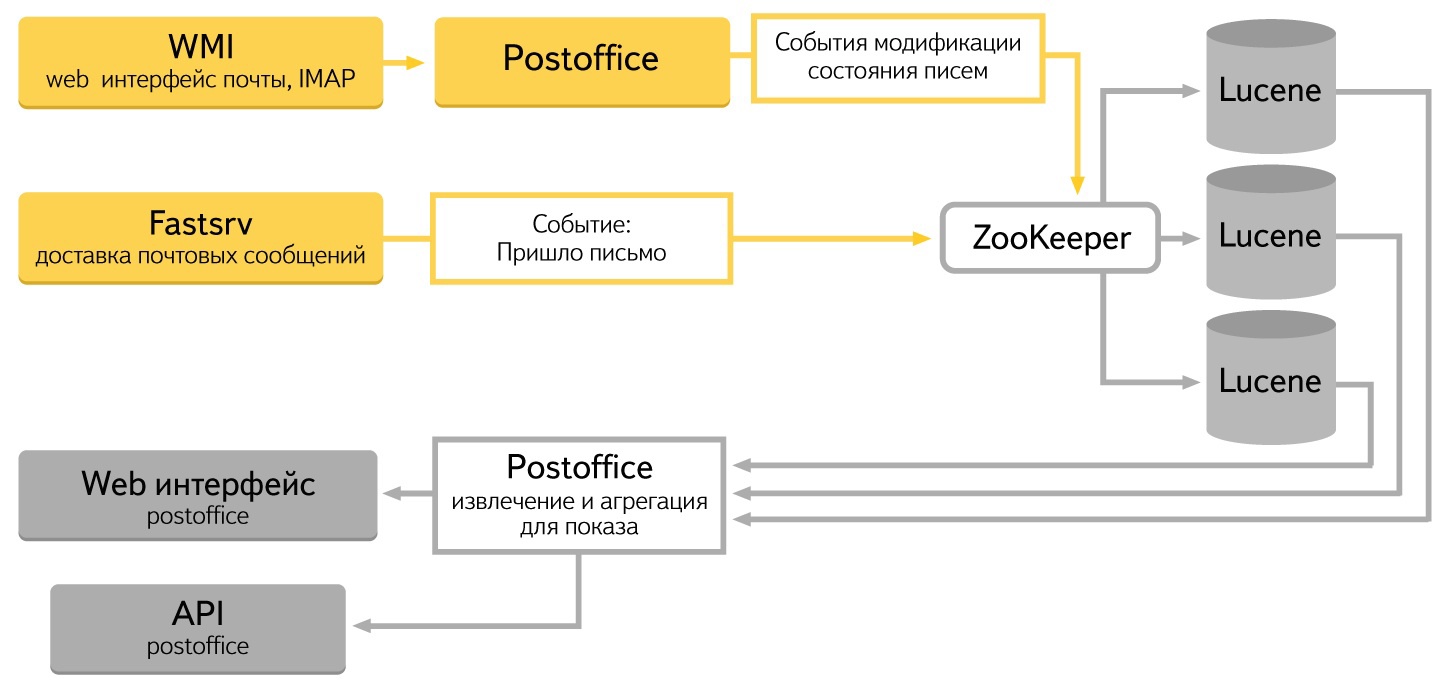
ユーザーがWebインターフェースでアクションを実行すると、これらのアクションに関する情報はLuceneのZookeeperを介して保存されます。 各アクション(たとえば、「スパム」ボタンを押す)はシステムの状態を変更するため、影響を受けるすべてのデータを慎重に変更する必要があります。 これはシステムの最も難しい部分です。書き換えとデバッグを最も長く行いました。
問題を解決する最初の試みは、彼らが言うように、「額」でした。 私たちは、Luceneでの手紙のステータスについて、その場でメモを取りたかったのです。 集計データは、抽出中にリアルタイムであると想定されていました。 このソリューションは、少数のレコードでうまく機能しました。 数百のレコードを合計するのにマイクロ秒かかりました。 すべてが素晴らしかった。 問題は、多数のエントリで始まりました。 たとえば、数千はすでに数秒処理されています。 数万-数十秒。 これはユーザーと私たちを悩ます。 データ出力を高速化する方法を探す必要がありました。
同時に、1日に数十、数百、数千の文字で一般ユーザーを集約することは問題ではありませんでした。 問題は、非常に短い時間で数十万の手紙を送った単一のメーリングリストでした。 それらのデータをリアルタイムで計算することは不可能でした。
ソリューションは、Webインターフェースからのリクエストを分析した後に見つかりました。 クエリの種類はほとんどなく、それらはすべてデータの集計またはデータ系列の平均値の検索に要約されました。 データベースに集計レコードを追加し、レターのステータスに関するレコードを追加または変更するときにそれらを変更し始めました。 たとえば、手紙が届いた-彼らは合計カウンターに1を追加しました。 ユーザーは手紙を削除しました-彼らは合計カウンターからユニットを取り、削除されたカウンターにユニットを追加しました。 ユーザーはメッセージをスパムとしてマークしました-スパムレターのカウンターにユニットを追加しました。 クエリを完了するために処理する必要があるレコードの数が少なくなり、これにより集約が大幅に加速されました。 Zookeeperを使用すると、データの整合性を簡単に確保できます。 集計レコードを変更するには時間がかかりますが、わずかなデータラグを許容できます。
結果は何ですか? 現在、Luceneのシステムには4台、Zookeeperの3台の車があります。 入力データは10台のマシンから取得され、6台のフロントエンドマシンで発行されます。 システムは、毎秒4,500件の変更要求と1,100件の読み取り要求を処理します。 現在のストレージ容量は3.2テラバイトです。
Lucene + Zookeeperのストレージシステムは非常に安定していることが証明されています。 Luceneでノードをその場で無効にしたり、ノードを追加したりできます。 Zookeeperは履歴を保存し、必要な数のイベントを新しいマシンにロールします。 しばらくしてから、関連情報を頭に入れます。 クラスタ内の1台のマシンがデータバックアップストレージに割り当てられます。
厳しい開発期間にもかかわらず、システムは信頼性が高く高速であることが判明しました。 このアーキテクチャにより、垂直および水平の両方で簡単にスケーリングし、新しいデータ分析機能を追加できます。 すぐに追加します。