Zabbix 2.2の記事を読んで、対応するブログに掲載されたので、Gentooがバージョン2.2のマスクを解除するのを待つことができませんでした。 このバージョンには、「日常生活」に興味がなく有用ではないような革新はほとんどありませんでした。 これらは、VMwareの監視、システムアクセラレーション、LLDPの改善、つまり、ほぼすべての項目です。
数ヶ月が経過し、バージョン2.2は偽装版でもありませんでした。
時々私は物事を脇に置き、緊急かつ重要なタスクと仕事に関して「並行」することをします。 今回、Zabbixをバージョン2.2にアップグレードしたいという思いを思い出しました。
偽装された*をチェックインしました。最後に、2.2.5があります。
さて、先に進みましょう。リリースから1年が経過しました。安定版は存在しないため、何が起きても決定します。
マスクを解除し、必要な場所(主なものはもちろんサーバーとプロキシ)を収集し、再起動します。 WebインターフェイスIIIの再インストール...
そして何も、データベースが更新されています。
事は速くありません、私のベースは小さくありません、そして、プロセスは一般にフリーズします。
まあ、彼らが言うように、それは始まったと思いますが、開始する時間がありませんでしたが、すべてがすでに悪いです。
mysqlログにはエラー番号28があり、「デバイスにスペースが残っていません」という意味で、どこにも十分なスペースがありました。 「Googleがあれば、神様」(c)ということわざにもあるように、すぐにではなく、このデバイスがibdata1とibdata2であることがわかりました。サイズはinnodb_data_file_pathパラメーターで規制されています。 最大を256Mから512Mに変更した後、データベースの更新が成功し、サーバーが起動しました。
プロキシにも問題があり、データベースが原因でした。 sqliteだけが更新されないため、プロキシを停止し、古いデータベースを削除してプロキシを開始します。 彼らが言うように、アップグレードノートを注意深く読んでください
もちろん、更新中に期限切れのデータが大量に蓄積されるため、インターフェイスにすべてが表示されていることを確認できることを確認し、すべてが確定して更新されるまで待機します。
数時間後、スケジュールを確認します。

その日はだるさを感じ始めていました。
それは私たちの番です。 どこ?..プロキシの1つからの主な期限切れデータ。 そして、どのようなデータ。 そして、SNMPv3で受信したデータ。
素晴らしい。 以前にこの機能に質問がありましたが、すべての手が届かず、アップデートがこれらの問題を解決するという希望がありました。 そして、システムは実際には動作しなくなります。 かつて、1台のサーバーまたはプロキシを使用している人々が何百ものネットワークデバイスを監視する方法について読んでいたときに、何が問題なのか理解できませんでしたか? 私は数十のデバイスを持っていますが、すべてが限界まで機能します。 ああ、データベースは完全に最適化されており、サーバーは高速データストアに配置され、大量のメモリが割り当てられています。
私はロールバックしたくなかったので、問題を処理しようとすることは何としても決定されました。
私はプロキシの1つを選択し、その背後で最も多くのSNMPデバイスを選択し、理解し始めました。
プロキシのログにあるものは次のとおりです**:
4447:20141218:124053.605 SNMP agent item "ifAdminStatus.["10130"]" on host "co-xx02" failed: first network error, wait for 15 seconds 4468:20141218:124108.270 resuming SNMP agent checks on host "co-xx02": connection restored
したがって、異なるアイテムを使用して、すべてのSNMPホストでランダムに実行します。
ネットワークの問題は絶対にありませんが、忠実のために、スイッチの接続性、速度、ログをすばやく確認しました。 snmpwalkを使用してSNMP自体をチェックし、ツリー全体をプルします。 問題ありません。
Google。 ポーラーが詰まっている、タイムアウトが間違っている、バージョン2.2.3でこれに関連するバグが修正されています。 誰かにネットワークの問題があり、UDPが失われています。 しかし、これは私たちの場合ではありません。
それでは?..
興味深い事実、プロキシをリロードすると
/etc/init.d/zabbix-proxy restart
線がどのように縮小し始めるかを見ることができますが、それから突然、再び何かが起こり、すぐに成長します***。
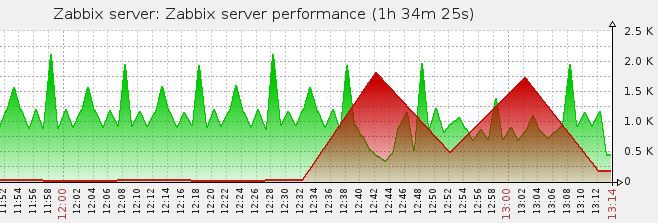
何が起こっているのですか?..
高度なzabbix-proxyロギングをオンにします
DebugLevel = 4
zabbix-proxyを再起動し、エラーが表示されるのを待ちます
ネットワークエラーの代わりに、より完全な情報が表示されるようになりました
こんな感じ
5414:20141218:125955.481 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94 5414:20141218:125955.481 End of zbx_snmp_get_values():NETWORK_ERROR 5414:20141218:125955.481 End of zbx_snmp_process_standard():NETWORK_ERROR 5414:20141218:125955.481 In zbx_snmp_close_session() 5414:20141218:125955.481 End of zbx_snmp_close_session() 5414:20141218:125955.481 getting SNMP values failed: Cannot connect to "192.168.xx:161": Too long. 5414:20141218:125955.481 End of get_values_snmp() 5414:20141218:125955.481 In deactivate_host() hostid:10207 itemid:43739 type:6 5414:20141218:125955.481 query [txnlev:1] [begin;] 5414:20141218:125955.481 query [txnlev:1] [update hosts set snmp_errors_from=1418896795,snmp_disable_until=1418896810,snmp_error='Cannot connect to "192.168.xx:161": Too long.' where hostid=10207] 5414:20141218:125955.481 query [txnlev:1] [commit;] 5414:20141218:125955.481 SNMP agent item "ifOperStatus.["10143"]" on host "co-xx04" failed: first network error, wait for 15 seconds 5414:20141218:125955.481 deactivate_host() errors_from:1418896795 available:1 5414:20141218:125955.482 End of deactivate_host()
ステータス1、エラーステータス-1、要素数94
これがNETWORK_ERRORであるという結論です
そして、少し低い復号化あまりにも長いとホストの非アクティブ化。 ホストが非アクティブ化されると、ホストからデータを受信できず、データがキューに入れられることは明らかです。これがキューの説明です。
すぐにerrstatパラメーターに興味がある
catを/var/log/zabbix/zabbix_proxy.logに作成| grep errstat
5412:20141218:130351.410 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:11 5433:20141218:130351.470 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94 5430:20141218:130351.476 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94 5417:20141218:130353.442 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:5 5420:20141218:130353.534 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
ええ、もっと深く掘ります
もっと深くする必要があるというイメージがあるはずですが、そうではありません。 彼女は皆を得たと思う。
cat /var/log/zabbix/zabbxi_proxy.logを実行する| grep errstat:-1
5416:20141218:130353.540 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94 5412:20141218:130355.571 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94 5417:20141218:130355.591 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94 ... 5420:20141218:130453.187 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94 5412:20141218:130455.206 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94 5413:20141218:130455.207 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
1つのプロキシを除くすべてのデバイスの監視をオフにするときが来ました。 そうしないと、ログを理解するのが難しすぎます。 とにかく、現在のシステムは監視に適していません。
オフにして
cat /var/log/zabbix/zabbxi_proxy.log | grep mapping_num
プロキシをリロードします
最初は間違いがなく、mapping_numは1から徐々に成長しています(原則を示すために個々の線がカットされています)
mapping_numがどのように成長するかをいつでも見ることができます
7876:20141218:131251.660 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:4 7872:20141218:131251.681 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:6 7872:20141218:131251.919 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:8 7876:20141218:131251.919 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:9 7868:20141218:131351.965 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:13 10502:20141218:135237.884 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:31 10507:20141218:135238.244 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:62 12429:20141218:141637.942 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:31 12429:20141218:141637.966 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:31 12433:20141218:141651.142 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-1 mapping_num:94
次にoppa 94、-1で長すぎます。 つまり 開始直後に、プロキシはデバイスをテストし、SNMP要求を送信して、1つの要求のアイテム数を増やします。 ラインは急速に縮小し始めます。 次に、(つまり、プロキシ)マジック番号94に到達すると、障害が発生し、デバイスがzabbixによって15秒間オフになり、キューが急激に増加し始めます。
ご覧のとおり、ここにネットワークエラーはありません。長すぎます。
さて、zabbix snmpで何かを見つけようとして長すぎます。
タイムアウト、ポーラーのオーバーロード...興味深い投稿の1つに、アイテムのOIDが誤って生成されたときにこのようなエラーが発生したという情報があったため、snmpgetを含むすべてのOIDを再確認しました
つまり その結果、Googleは私を助けることができませんでした。
自分で整理します。これは便利です。
では、何がありますか?
アイテムの数が94(つまり十分な大きさ)になるとすぐに、何かが起こり、システムが迷子になります。
ここでも、そうではない写真;)
コードに取り掛かる時です。 gentooに何かをダウンロードする必要はありません。すべてがすでにあるので、作業ディレクトリにすべてを解凍しました。
最初に、エラーが表示される場所を見つけます。 errstatで検索
驚いたことに、ファイルには、checkings_snmp.cという名前の2つの場所しかありません。
次の2つの場所:
745行目から
/* communicate with agent */ status = snmp_synch_response(ss, pdu, &response); zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld max_vars:%d", __function_name, status, NULL == response ? (long)-1 : response->errstat, max_vars);
行938から
status = snmp_synch_response(ss, pdu, &response); zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld mapping_num:%d", __function_name, status, NULL == response ? (long)-1 : response->errstat, mapping_num);
2番目の部分に興味がある一方で(mapping_numはその中にあるという事実に基づいて)
プログラマーでさえ、応答がNULLであることを認識していませんが、なぜですか?..
errstat:-1を使用することを思い出してください。 つまり snmp_synch_response関数は1を返しますが、これはどういう意味ですか?..
そして、それはSTAT_ERROR(1)を意味します(彼女はSTAT_TIMEOUT(2)およびSTAT_SUCCESS(0)の方法も知っています)
彼らが言うように、それは明確ではありませんが、素晴らしい...
一方、このファイルのどこかにNETWORK_ERRORを返す必要があります。どこで、なぜその原因を見つけてください。
zbx_get_snmp_response_error関数への最初のエントリ(つまり、ヒント)
zbx_get_snmp_response_errorコードを表示
static int zbx_get_snmp_response_error(const struct snmp_session *ss, const DC_INTERFACE *interface, int status, const struct snmp_pdu *response, char *error, int max_error_len) { int ret; if (STAT_SUCCESS == status) { zbx_snprintf(error, max_error_len, "SNMP error: %s", snmp_errstring(response->errstat)); ret = NOTSUPPORTED; } else if (STAT_ERROR == status) { zbx_snprintf(error, max_error_len, "Cannot connect to \"%s:%hu\": %s.", interface->addr, interface->port, snmp_api_errstring(ss->s_snmp_errno)); switch (ss->s_snmp_errno) { case SNMPERR_UNKNOWN_USER_NAME: case SNMPERR_UNSUPPORTED_SEC_LEVEL: case SNMPERR_AUTHENTICATION_FAILURE: ret = NOTSUPPORTED; break; default: ret = NETWORK_ERROR; } } else if (STAT_TIMEOUT == status) { zbx_snprintf(error, max_error_len, "Timeout while connecting to \"%s:%hu\".", interface->addr, interface->port); ret = NETWORK_ERROR; } else { zbx_snprintf(error, max_error_len, "SNMP error: [%d]", status); ret = NOTSUPPORTED; } return ret; }
うん。 つまり 上記の条件のいずれにも該当しないSTAT_ERROR入力スイッチがあるため、デフォルトでNETWORK_ERRORが発生します。
このデフォルトは私たちを混乱させることをすでに認識しており、実際にどのようなエラーであるかを知る必要があります。 エラーコードはss-> s_snmp_errnoに保存され、変数の出力をログに追加します。
私からのプログラマーはまあまあなので、クローバーと誰かの母親の助けを借りて、私はこのようにパッチを当てました:
diff -urN zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c --- zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c 2014-07-17 17:49:45.000000000 +0400 +++ zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c 2014-10-10 16:38:31.000000000 +0400 @@ -938,7 +938,7 @@ status = snmp_synch_response(ss, pdu, &response); zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld mapping_num:%d", - __function_name, status, NULL == response ? (long)-1 : response->errstat, mapping_num); + __function_name, status, NULL == response ? (STAT_ERROR == status ? (long) ss->s_snmp_errno : (long)-1) : response->errstat, mapping_num); if (STAT_SUCCESS == status && SNMP_ERR_NOERROR == response->errstat) {
ステータスがSTAT_ERRORの場合、ss-> s_snmp_errnoを出力します
zabbixのソースをローカルリポジトリに投入し、ebuildをすばやく修正して実行しました。
コンパイル、再起動、待機。
そして、ここで彼女は私たちの本当の間違いです。
11211:20141218:155253.362 zbx_snmp_get_values() snmp_synch_response() status:0 errstat:0 mapping_num:18 11210:20141218:155253.393 zbx_snmp_get_values() snmp_synch_response() status:1 errstat:-5 mapping_num:94
エラー-5
Net-SNMP snmp_api.hを参照してください
#define SNMPERR_TOO_LONG (-5)
同様のことがログに表示されていましたが、長すぎるフレーズでは何も見つかりませんでした。エラーの種類と発生時期を見てみましょう。
snmp_api.cで確認できます
もう少しコード
/* * Make sure we don't send something that is bigger than the msgMaxSize * specified in the received PDU. */ if (pdu->version == SNMP_VERSION_3 && session->sndMsgMaxSize != 0 && length > session->sndMsgMaxSize) { DEBUGMSGTL(("sess_async_send", "length of packet (%lu) exceeds session maximum (%lu)\n", (unsigned long)length, (unsigned long)session->sndMsgMaxSize)); session->s_snmp_errno = SNMPERR_TOO_LONG; SNMP_FREE(pktbuf); return 0; } /* * Check that the underlying transport is capable of sending a packet as * large as length. */ if (transport->msgMaxSize != 0 && length > transport->msgMaxSize) { DEBUGMSGTL(("sess_async_send", "length of packet (%lu) exceeds transport maximum (%lu)\n", (unsigned long)length, (unsigned long)transport->msgMaxSize)); session->s_snmp_errno = SNMPERR_TOO_LONG; SNMP_FREE(pktbuf); return 0; }
次の2つのオプションのみがあります。
1.送信するデータの長さが、受信したPDUで指定されたmsgMaxSizeパラメーターよりも長い
2.基礎となるトランスポートは、この長さのパケットを送信できません
問題は、このエラーを修正する方法です。 上記から、msgMaxSizeを取得するかどうか、正しく処理するかどうかなどを探す必要があります。 など しかし、zabbixのソースコードは初めて、Cは2回目(3回目は大丈夫)に表示されます。
要するに、それは熱意を引き起こしません...はい、そしておそらく何かが壊れる可能性があります。
叙情的な余談:
この問題の進行中に、SNMP大量処理に関する情報に出くわしたことを言わなければなりません。 つまり zabbixは、単一のリクエストで複数のSNMPデータアイテムをリクエストできます。
SNMP一括処理の詳細
要するに、zabbixは1回のリクエストで最大128個の値をクエリできますが、すべてのデバイスがこれらの128個の値を一度に処理できるわけではありません。 また、zabbihは、特定の各デバイスの最大値に対して検索戦略を使用します。 ところで、ログでこれを見ました。 mapping_numの漸進的な増加。 zabbixはSNMPERR_TOO_BIGデバイスからエラーを受信するとすぐに、特定のアルゴリズムを使用してエラーのない結果を返す最大値を検索します。
なぜ私はこれをしていますか。
zabbixにはオーバーフローエラーを処理するメカニズムがあります(これを呼び出しましょう)、あと1つだけ拡張する必要があります。
アルゴリズム自体は、エラーの結論の下でペイントされています。
再びこのコード
else if (1 < mapping_num && ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status)) { /* Since we are trying to obtain multiple values from the SNMP agent, the response that it has to */ /* generate might be too big. It seems to be required by the SNMP standard that in such cases the */ /* error status should be set to "tooBig(1)". However, some devices simply do not respond to such */ /* queries and we get a timeout. Moreover, some devices exhibit both behaviors - they either send */ /* "tooBig(1)" or do not respond at all. So what we do is halve the number of variables to query - */ /* it should work in the vast majority of cases, because, since we are now querying "num" values, */ /* we know that querying "num/2" values succeeded previously. The case where it can still fail due */ /* to exceeded maximum response size is if we are now querying values that are unusually large. So */ /* if querying with half the number of the last values does not work either, we resort to querying */ /* values one by one, and the next time configuration cache gives us items to query, it will give */ /* us less. */ if (*min_fail > mapping_num) *min_fail = mapping_num; if (0 == level) { /* halve the number of items */ int base; ret = zbx_snmp_get_values(ss, items, oids, results, errcodes, query_and_ignore_type, num / 2, level + 1, error, max_error_len, max_succeed, min_fail); if (SUCCEED != ret) goto exit; base = num / 2; ret = zbx_snmp_get_values(ss, items + base, oids + base, results + base, errcodes + base, NULL == query_and_ignore_type ? NULL : query_and_ignore_type + base, num - base, level + 1, error, max_error_len, max_succeed, min_fail); } else if (1 == level) { /* resort to querying items one by one */ for (i = 0; i < num; i++) { if (SUCCEED != errcodes[i]) continue; ret = zbx_snmp_get_values(ss, items + i, oids + i, results + i, errcodes + i, NULL == query_and_ignore_type ? NULL : query_and_ignore_type + i, 1, level + 1, error, max_error_len, max_succeed, min_fail); if (SUCCEED != ret) goto exit; } } }
つまり、すべてが単純であり、既存の条件を中断することなく、独自の条件を追加する必要があります。 これには、すべてのデータがあります。
- ステータスはSTAT_ERRORでなければなりません
- ss-> s_snmp_errnoはSNMPERR_TOO_LONGでなければなりません
また、このような場所が2つ(ログファイルへの出力も2つ)あることを考慮し、結果のパッチは次のようになります。
ついに
diff -urN zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c --- zabbix-2.2.5/src/zabbix_server/poller/checks_snmp.c 2014-07-17 17:49:45.000000000 +0400 +++ zabbix-2.2.5.new/src/zabbix_server/poller/checks_snmp.c 2014-10-10 16:38:31.000000000 +0400 @@ -746,10 +746,10 @@ status = snmp_synch_response(ss, pdu, &response); zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld max_vars:%d", - __function_name, status, NULL == response ? (long)-1 : response->errstat, max_vars); + __function_name, status, NULL == response ? (STAT_ERROR == status ? (long)ss->s_snmp_errno : (long)-1) : response->errstat, max_vars); if (1 < max_vars && - ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status)) + ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status || (STAT_ERROR == status && SNMPERR_TOO_LONG == ss->s_snmp_errno))) { /* The logic of iteratively reducing request size here is the same as in function */ /* zbx_snmp_get_values(). Please refer to the description there for explanation. */ @@ -938,7 +938,7 @@ status = snmp_synch_response(ss, pdu, &response); zabbix_log(LOG_LEVEL_DEBUG, "%s() snmp_synch_response() status:%d errstat:%ld mapping_num:%d", - __function_name, status, NULL == response ? (long)-1 : response->errstat, mapping_num); + __function_name, status, NULL == response ? (STAT_ERROR == status ? (long) ss->s_snmp_errno : (long)-1) : response->errstat, mapping_num); if (STAT_SUCCESS == status && SNMP_ERR_NOERROR == response->errstat) { @@ -1001,7 +1001,7 @@ } } else if (1 < mapping_num && - ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status)) + ((STAT_SUCCESS == status && SNMP_ERR_TOOBIG == response->errstat) || STAT_TIMEOUT == status || (STAT_ERROR == status && SNMPERR_TOO_LONG == ss->s_snmp_errno))) { /* Since we are trying to obtain multiple values from the SNMP agent, the response that it has to */ /* generate might be too big. It seems to be required by the SNMP standard that in such cases the */
コンパイル、再起動...
結果は次のとおりです。
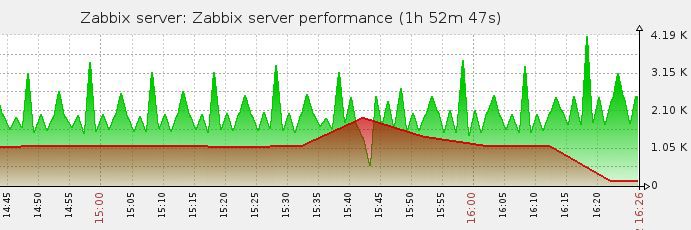
エラーネットワークエラーがログから消えました。
やった!
あとがき
もちろん、実際には、エラーと解決策を見つけるのに時間がかかりました。 ソースコードを選択し、最終的にzabbixとnet-snmpを選択して、コードの2か所で停止する必要がありました。
しかし、「不活性物質」に対する勝利の感覚は貴重です。
*願望は10月7日に転がり、その後2.2.5はまだマスクされていました。 偶然にも、彼女は10月10日にマスクされました。
**彼は後で状況をまねた記事を書くために、時間を見ないでください。 ショーダウンの間、ログからデータを取り出す時間は絶対にありませんでした。
***はい、はい、私も写真をモデル化しました。 最初は緑色で、すべてが赤色であると想像してください;)そして、再起動中に飲みました。
2014.12.31 UPD:記事の議論に基づいて、チケットが開かれました( alexvlに感謝 ):
「長すぎる」SNMPv3要求の送信に失敗すると、SNMPバルクによって適切に処理されません。
バージョン2.2.9rc1、2.4.4rc1、2.5.0以降、正常に閉じられました(Aleksandrs Saveljevsに感謝)