
データベース分離のメカニズムに関するドキュメントを見つけることは非常に困難です。 基本的なサイトに小さな記事がありますが、ほとんどメリットはありません。 古き良きGoogleがありますが、複雑さを理解するためには、適切な情報を何時間も探すのに何時間も費やす必要があります。 他に選択の余地はありませんでしたが、この記事があります。 私たちはそれが役に立つことを願っています。
やめて!
1Cを使用する場合は、構成、KLADR、銀行リスト(ライセンスを失います)、為替レート(ああ、これらの経済的に不安定なユーロとドル)、ユーザーリスト、処理、プラットフォームのバージョンなど、多くを更新する必要があります。 優れたハードウェアでは、1ベースのすべてのリージョンでKLADRを更新するのに約30分かかります。 構成の更新には、10分から数時間かかります(バンドルのローリング時)。
ベースが1、2、10の場合、これはすべて日常業務の形で行うことができます。 数十ダース-それは多くの時間がかかりますが、あなたは対処することができます。 数百の拠点があり、
女王下は個々のデータベースに住んでいることを忘れないでくださいデータベースと1バイトの違いがない構成。 構成には変更のアップロード、処理の挿入、標準機能の拡張も必要であるという事実にもかかわらず、場所に住んで食べます。
そのため、同じ構成でも異ならない複数のベース(組織を除く)がある場合、分離メカニズムにより(tarなしではなく、後ほど)作業がはるかに簡単になります。 そうでなければ、すぐにあなたは管理者の軍隊を雇わなければなりません:)
基本的な分離
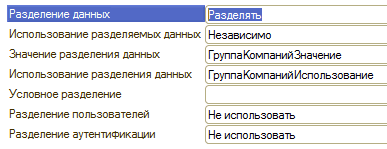
まず、ベースを共有するためのサインを決定する必要があります。 セパレータには任意のタイプのデータを含めることができます。10文字の文字列を使用します:組織のITN。 主なことは、セパレーター(一般属性)の名前が既存の構成オブジェクトと一致してはならないことです。つまり、既にそのようなディレクトリーがあるため、たとえば「Organization」と呼ぶことはできません。 セパレータを「Group of Companies」と呼びました。
その後、空のデータベースを使用して一般的な構成を行い、コンフィギュレーターに移動して「一般的な詳細」セクションを開きます。 一般的な要件を追加し、値「データ共有」を「共有」に変更します。
コンフィギュレーターはセッションパラメーターの作成を提案します-私たちは静かに同意して先に進みます。 分離プロパティをオンにして「一般的な必要条件」を作成すると、データベースは複数階建ての建物のようになります。 この家には、エレベーター、階段の飛行、通信など、誰もがすべてのフロアからアクセスできる要素がありますが、アパート、廊下、窓など、フロア内でしか利用できないユニークな
特定の組織(またはデータベースの領域)を入力するには、データベースへの接続文字列の区切り文字を通知するか、v8iファイル( 前回説明した )で区切り文字を指定する必要があります。
[ 7710967300 ] Connect=Srvr="%servername%";Ref="%base_name%"; AdditionalParameters=/Z "-0,-0,+7710967300";
/ Zの後に、一般的な詳細を順番に示します。 標準の簿記にはすでに2つの一般的なシステムの詳細があるため、使用しないように値-0を指定し、3番目(作成した)としてTINを転送します。
1000および1チェックボックス
ここで、データのどの部分がすべての領域に共通するかを決定する必要があります。 これらはすべてコンフィギュレーターを介して構成されます。 作成したばかりの一般属性のプロパティには、800個のパラメーターの小さなリストを開く「Composition」という項目があります。

パラメータの選択は、あなたの裁量、裁量、環境に任されています。 これが私たちのバージョンです (より正確には、20,000ピクセルあります)。
また、セパレータを使用すると、データベースごとに個別のユーザーリストを設定できます。これは、数百人のユーザーがいる場合に便利です。特定のデータベースを入力するとき、このリストを血まみれのトウモロコシにスクロールする必要はありません。 透過的な認証を設定しているため、これは使用しません。
現在のデータベースからデータをアンロードします
現在のデータベースからデータをアンロードするには、ユニバーサル
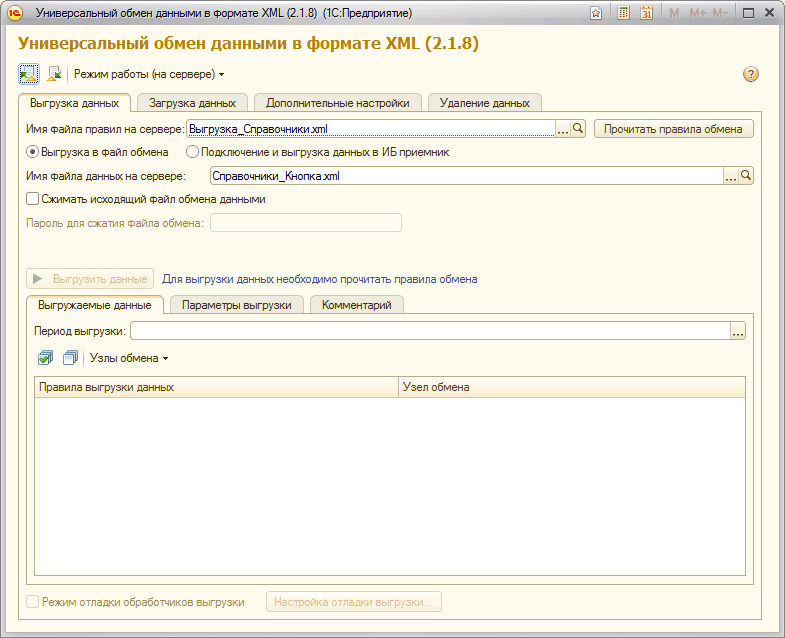
ホステスへの注意:ディレクトリとドキュメントは個別にアンロードするのに適しています-これにより、ロード時に不要なエラーを回避できます。
分割されたデータベースへのデータのロード
/ Zパラメーター「-0、-0、+%your separator%」で1Cを開始します。これは、データをロードする組織の区切り記号を示します。 ユニバーサルエクスチェンジを起動し、アンロード中に受信したファイル(最初にディレクトリ、次にドキュメント)をフィードします。 各
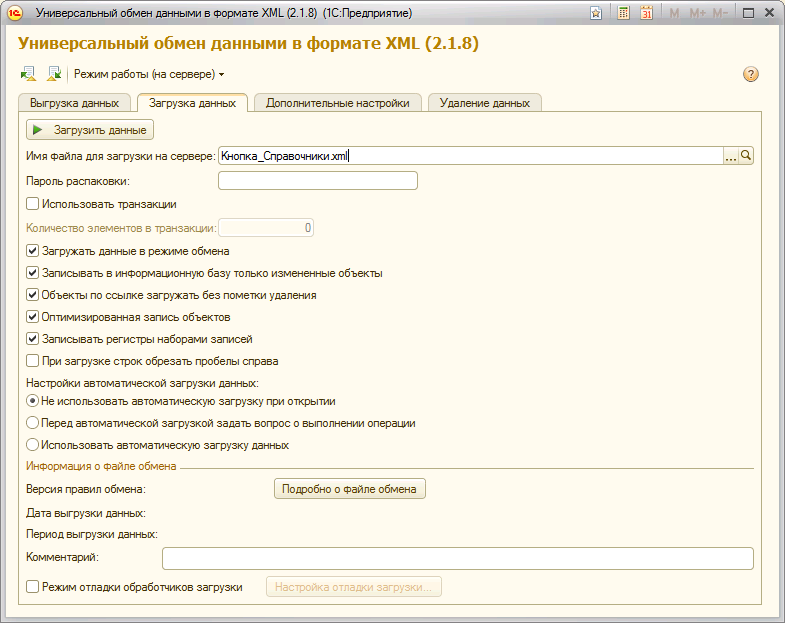
タスクを簡素化するために、コマンドライン(/ Execute c:unload.epf)を使用して、少し修正された標準処理を事前起動するバルクアンロードを実行します。 次に、受信したファイルを手動で分割データベースにロードします。
より多くの時間をより少ない時間で過ごす方法
分離プロセスは簡単ではありません。 現在、500を超える組織がありますが、数週間で70しか分割できなかったことを思い出してください。しかし、6か月以内に過去の作業に感謝し、多くの時間と労力が節約されたことを確信しています。
ボタン会計士は、通常のデータベースから分割されたデータベースへの組織の移行に気付きません;彼らにとって、プロセスは簡単です。 司祭は管理者だけで燃えます:)
副作用:スペースを1から20節約し、速度を間接的に向上させることは非常に貴重です。 絶対数では:50の組織がSQLで2 GBのスペースを占有しますが、1つの独立したデータベースは800 MBを占有します。
約束されたハエは軟膏で、4つも飛びました:
- ユーザーの
1人 が1つの組織でデータを台無しにした場合、分割されたデータベース全体をロールバックする必要があります。1つのデータ領域だけを取得してロールバックすることはできません - 特にディレクトリを追加または変更する更新をより徹底的にテストする必要があります
- データベースをクライアントに転送する(または税をマージする)必要がある場合は、逆の手順を実行する必要があります:ユニバーサルエクスチェンジを使用して分割されたデータベースから組織をアンロードし、空の通常のデータベースにロードして保存します。
dtファイル - 分割されたデータベースでは、スケジュールされたタスクを管理できません(たとえば、為替レートを自動的に更新できません)
最初の3つのスプーンはそれほど苦くありません。 しかし、4番目の処理については、まだわかりませんが、熱心に調査しています。