まえがき
私が仕事をする幸運な分野は、心臓の計算電気生理学と呼ばれています 。 心臓活動の生理学は、個々の心筋細胞のレベルで発生する電気的プロセスによって決定されます。 これらの電気プロセスは、測定が容易な電界を作り出します。 さらに、静電気の数学的モデルの枠組みで非常によく説明されています。 ここで、心臓の働きを厳密に数学的に記述するユニークな機会が生じます。これは、多くの心臓病の治療方法を改善することを意味します。
この分野での仕事中に、さまざまなコンピューティングテクノロジーを使用した経験を積んできました。 この出版物の一部としてだけでなく、私にとって興味深いかもしれないいくつかの質問に答えようとします。
Scientific Pythonについて簡単に
大学の最初のコースから始めて、数値アルゴリズムの迅速な開発のための理想的なツールを見つけようとしました。 いくつかの率直に言って限界的な技術を捨てた場合、C ++とMATLABの間を走りました。 これは、Scientific Python [1]を発見するまで続きました。
Scientific Pythonは、科学計算と科学視覚化のためのPythonライブラリのコレクションです。 私の仕事では、私のニーズの約90%をカバーする以下のパッケージを使用します。
| 役職 | 説明 |
|---|---|
| ナンピー | 基本的なライブラリの1つを使用すると、MATLABスタイルの単一オブジェクトとして多次元配列を操作できます。
線形代数、フーリエ変換、乱数の処理などの基本手順の実装が含まれます。 |
| シピー | NumPy拡張には、最適化メソッドの実装、放電されたマトリックスの処理、統計などが含まれます。 |
| パンダ | 多次元データと統計の分析用の個別のパッケージ。 |
| シンピー | シンボリック数学のパッケージ。 |
| マトプロプリブ | 二次元グラフィックス。 |
| マヤビ2 | VTKに基づく3次元グラフィックス。 |
| スパイダー | 数学アルゴリズムのインタラクティブな開発に便利なIDE。 |
Pythonでの並列計算の問題。
この記事の並列コンピューティングによって、SMP-共有メモリを使用した対称型マルチプロセッシングについて理解できます。 CUDAと共有メモリを備えたシステムの使用は扱いません(MPI標準が最もよく使用されます)。
問題はGILです。 GIL(Global Interpreter Lock)は、複数のスレッドが同じバイトコードを実行するのを防ぐミューテックスです。 残念ながら、CPythonのメモリ管理システムはスレッドセーフではないため、このロックが必要です。 はい、GILはPythonの問題ではなく、CPythonインタープリターの実装の問題です。 しかし、残念ながら、Pythonの残りの実装は、高速な数値アルゴリズムの作成にはあまり適していません。
幸いなことに、現在GILの問題を解決する方法はいくつかあります。 それらを考慮してください。
テストタスク
Nベクトルの2つのセットが与えられます:3次元ユークリッド空間のP = {p 1 、p 2 、...、p N }およびQ = {q 1 、q 2 、...、q N } 。 次元N x Nの行列Rを作成する必要があります。各要素r i、jは次の式で計算されます。

大まかに言えば、すべてのベクトル間のペアワイズ距離を使用して行列を計算する必要があります。 この行列は、実際の計算でよく使用されます。たとえば、RBF補間や積分方程式の方法による緊急状態での差分の解決などです。
テスト実験では、ベクトルの数はN = 5000です。計算には、4コアのプロセッサが使用されました。 結果は、10の開始の平均時間によって取得されます。
テストタスクの完全な実装は、GitHubで見ることができます[2]。
「@chersaya」からのコメントの正しい発言。 ここでは、このテストケースを例として使用します。 ペアワイズ距離を本当に計算する必要がある場合は、scipy.spatial.distance.cdist関数を使用することをお勧めします。
C ++並列実装
Pythonでの並列計算の効率を比較するために、このタスクをC ++で実装しました。 主な機能コードは次のとおりです。
ユニプロセッサの実装:
//! Single thread matrix R calculation void spGetR(vector<Vector3D> & p, vector<Vector3D> & q, MatrixMN & R) { for (int i = 0; i < p.size(); i++) { Vector3D & a = p[i]; for (int j = 0; j < q.size(); j++) { Vector3D & b = q[j]; Vector3D r = b - a; R(i, j) = 1 / (1 + sqrt(r * r)); } } }
マルチプロセッサの実装:
//! OpenMP matrix R calculations void mpGetR(vector<Vector3D> & p, vector<Vector3D> & q, MatrixMN & R) { #pragma omp parallel for for (int i = 0; i < p.size(); i++) { Vector3D & a = p[i]; for (int j = 0; j < q.size(); j++) { Vector3D & b = q[j]; Vector3D r = b - a; R(i, j) = 1 / (1 + sqrt(r * r)); } } }
ここで面白いのは何ですか? まず、最初に、別のVector3Dクラスを使用して、3次元空間でベクトルを表しました。 このクラスのオーバーロード演算子「*」には、スカラー積の意味があります。 ベクトルのセットを表すために、std :: vectorを使用しました。 並列コンピューティングでは、OpenMPテクノロジーが使用されました。 アルゴリズムを並列化するには、「#pragma omp parallel for」ディレクティブを使用します。
結果:
| ユニプロセッサC ++ | 224ミリ秒 |
| マルチプロセッサC ++ | 65ミリ秒 |
Pythonでの並列実装
1.純粋なPythonでの単純な実装
このテストでは、特別なパッケージを使用せずに、純粋なPythonでタスクがどれだけ解決されるかを確認したかったのです。
ソリューションコード:
def sppyGetR(p, q): R = np.empty((p.shape[0], q.shape[1])) nP = p.shape[0] nQ = q.shape[1] for i in xrange(nP): for j in xrange(nQ): rx = p[i, 0] - q[0, j] ry = p[i, 1] - q[1, j] rz = p[i, 2] - q[2, j] R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz)) return R
ここで、 p 、 qは、次元(N、3)および(3、N)の配列のNumPy形式の入力データです。 そして、行列Rの要素を計算する正直なPythonループが登場します。
結果:
| ユニプロセッサPython | 57 386ミリ秒 |
2ユニプロセッサNumPy
一般に、NumPyを使用してPythonでコンピューティングする場合、並列処理についてまったく考える必要がない場合があります。 したがって、たとえば、2つの行列にNumPyを乗算する手順は、C ++(MKLまたはATLAS)の低レベルの高性能線形代数ライブラリを使用して最終的に実行されます。 しかし、残念ながら、これは最も一般的な操作にのみ当てはまり、一般的なケースでは機能しません。 残念ながら、テストタスクは順次実行されます。
ソリューションコードは次のとおりです。
def spnpGetR(p, q): Rx = p[:, 0:1] - q[0:1] Ry = p[:, 1:2] - q[1:2] Rz = p[:, 2:3] - q[2:3] R = 1 / (1 + np.sqrt(Rx * Rx + Ry * Ry + Rz * Rz)) return R
わずか4行でサイクルなし! だから私はNumPyが大好きです。
結果:
| ユニプロセッサNumPy | 973ミリ秒 |
3マルチプロセッサNumPy
GILの問題の解決策として、従来、複数の実行スレッドの代わりに複数の独立した実行プロセスを使用することが提案されています。 すべて問題ありませんが、問題があります。 各プロセスには独立したメモリがあり、結果のマトリックスを各プロセスに転送する必要があります。 この問題を解決するために、PythonマルチプロセッシングはRawArrayクラスを導入し、プロセス間で単一のデータ配列を分割する機能を提供します。 RawArrayの基礎は正確にはわかりません。 これらはメモリにマップされたファイルのようです。
ソリューションコードは次のとおりです。
def mpnpGetR_worker(job): start, stop = job p = np.reshape(np.frombuffer(mp_share.p), (-1, 3)) q = np.reshape(np.frombuffer(mp_share.q), (3, -1)) R = np.reshape(np.frombuffer(mp_share.R), (p.shape[0], q.shape[1])) Rx = p[start:stop, 0:1] - q[0:1] Ry = p[start:stop, 1:2] - q[1:2] Rz = p[start:stop, 2:3] - q[2:3] R[start:stop, :] = 1 / (1 + np.sqrt(Rx * Rx + Ry * Ry + Rz * Rz)) def mpnpGetR(p, q): nP, nQ = p.shape[0], q.shape[1] sh_p = mp.RawArray(ctypes.c_double, p.ravel()) sh_q = mp.RawArray(ctypes.c_double, q.ravel()) sh_R = mp.RawArray(ctypes.c_double, nP * nQ) nCPU = 4 jobs = utils.generateJobs(nP, nCPU) pool = mp.Pool(processes=nCPU, initializer=mp_init, initargs=(sh_p, sh_q, sh_R)) pool.map(mpnpGetR_worker, jobs, chunksize=1) R = np.reshape(np.frombuffer(sh_R), (nP, nQ)) return R
入力データと出力マトリックス用に分割された配列を作成し、コアの数に応じてプロセスのプールを作成し、タスクをサブタスクに分割し、並行して解決します。
結果:
| マルチプロセッサnumpy | 795ミリ秒 |
これで、Pythonだけを使用して私に知られている並列プログラミングのソリューションは終了しました。 さらに、GILを取り除くには、C ++レベルまで下げる必要があります。 しかし、これは見た目ほど怖くない。
4シトン
Cython [3]は、PythonコードにC命令を埋め込むことができるPython拡張です。 したがって、Pythonコードを取得し、いくつかの命令を追加して、パフォーマンスのボトルネックを大幅にスピードアップできます。 CythonモジュールはCコードに変換され、Pythonモジュールにコンパイルされます。 Cythonで問題を解決するためのコードは次のとおりです。
ユニプロセッサCython:
@cython.boundscheck(False) @cython.wraparound(False) def spcyGetR(pp, pq): pR = np.empty((pp.shape[0], pq.shape[1])) cdef int i, j, k cdef int nP = pp.shape[0] cdef int nQ = pq.shape[1] cdef double[:, :] p = pp cdef double[:, :] q = pq cdef double[:, :] R = pR cdef double rx, ry, rz with nogil: for i in xrange(nP): for j in xrange(nQ): rx = p[i, 0] - q[0, j] ry = p[i, 1] - q[1, j] rz = p[i, 2] - q[2, j] R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz)) return R
マルチプロセッサCython:
@cython.boundscheck(False) @cython.wraparound(False) def mpcyGetR(pp, pq): pR = np.empty((pp.shape[0], pq.shape[1])) cdef int i, j, k cdef int nP = pp.shape[0] cdef int nQ = pq.shape[1] cdef double[:, :] p = pp cdef double[:, :] q = pq cdef double[:, :] R = pR cdef double rx, ry, rz with nogil, parallel(): for i in prange(nP, schedule='guided'): for j in xrange(nQ): rx = p[i, 0] - q[0, j] ry = p[i, 1] - q[1, j] rz = p[i, 2] - q[2, j] R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz)) return R
このコードを純粋なPython実装と比較する場合、使用する変数の型を指定するだけで済みました。 GILは1行でリリースされます。 並列ループは、xrangeの代わりにprangeステートメントによって編成されます。 私の意見では、それは非常にシンプルで美しいです!
結果:
| ユニプロセッサCython | 255ミリ秒 |
| マルチプロセッサCython | 75ミリ秒 |
5 numba
Numba [4]はかなり新しいライブラリで、活発に開発されています。 ここでのアイデアは、Cythonとほぼ同じです。PythonコードでC ++レベルに到達する試みです。 しかし、アイデアははるかにエレガントに実装されています。
Numbaは、プログラムの実行中に直接コンパイル(JITコンパイル)できるLLVMコンパイラに基づいています。 たとえば、Pythonでプロシージャをコンパイルするには、jitアノテーションを追加するだけです。 さらに、注釈を使用すると、入力/出力データのタイプを指定できるため、JITコンパイルの効率が大幅に向上します。
タスクを実装するためのコードは次のとおりです。
ユニプロセッサヌンバ:
@jit(double[:, :](double[:, :], double[:, :])) def spnbGetR(p, q): nP = p.shape[0] nQ = q.shape[1] R = np.empty((nP, nQ)) for i in xrange(nP): for j in xrange(nQ): rx = p[i, 0] - q[0, j] ry = p[i, 1] - q[1, j] rz = p[i, 2] - q[2, j] R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz)) return R
マルチプロセッサNumba:
def makeWorker(): savethread = pythonapi.PyEval_SaveThread savethread.argtypes = [] savethread.restype = c_void_p restorethread = pythonapi.PyEval_RestoreThread restorethread.argtypes = [c_void_p] restorethread.restype = None def worker(p, q, R, job): threadstate = savethread() nQ = q.shape[1] for i in xrange(job[0], job[1]): for j in xrange(nQ): rx = p[i, 0] - q[0, j] ry = p[i, 1] - q[1, j] rz = p[i, 2] - q[2, j] R[i, j] = 1 / (1 + sqrt(rx * rx + ry * ry + rz * rz)) restorethread(threadstate) signature = void(double[:, :], double[:, :], double[:, :], int64[:]) worker_ext = jit(signature, nopython=True)(worker) return worker_ext def mpnbGetR(p, q): nP, nQ = p.shape[0], q.shape[1] R = np.empty((nP, nQ)) nCPU = utils.getCPUCount() jobs = utils.generateJobs(nP, nCPU) worker_ext = makeWorker() threads = [threading.Thread(target=worker_ext, args=(p, q, R, job)) for job in jobs] for thread in threads: thread.start() for thread in threads: thread.join() return R
純粋なPythonと比較して、Numbaのシングルプロセッサソリューションに追加される注釈は1つだけです! 残念ながら、マルチプロセッサバージョンはそれほど美しくありません。 スレッドのプールを整理し、GILを手動で提供する必要があります。 Numbaの以前のリリースでは、単一の命令で並列ループを実装しようとしましたが、後続のリリースの安定性の問題により、この機能は削除されました。 時間が経つにつれて、この機会は修復されると確信しています。
実行結果:
| ユニプロセッサヌンバ | 359ミリ秒 |
| マルチプロセッサnumba | 180ミリ秒 |
結論
結果を次の図で説明します。
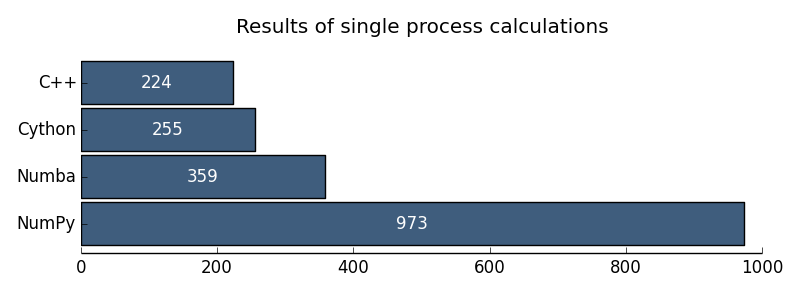
図 1.ユニプロセッサコンピューティングの結果
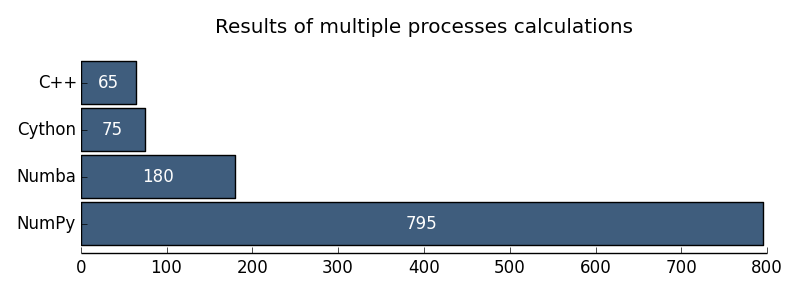
図 2.マルチプロセッサコンピューティングの結果
Pythonの数値計算に関するGILの問題は実際に克服されているように思えます。 これまでのところ、並列コンピューティングテクノロジーとしてCythonをお勧めします。 しかし、私は本当にNumbaをよく見ます。
参照資料
[1]科学Python: scipy.org
[2]テストの完全なソースコード: github.com/alec-kalinin/open-nuance
[3] Cython: cython.org
[4] Numba: numba.pydata.org
PSコメント「@chersaya」は、並列コンピューティングの別の方法を正しく指摘しました。 これは、numexprライブラリの使用です。 Numexprは、Cで記述された独自の仮想マシンと独自のJITコンパイラを使用します。 これにより、彼は単純な数式を文字列として取得し、コンパイルしてすばやく計算することができます。
使用例:
import numpy as np import numexpr as ne a = np.arange(1e6) b = np.arange(1e6) result = ne.evaluate("sin(a) + arcsinh(a/b)")