決定木を使用してバンクオブアメリカの株式を取引する方法。

さまざまな技術指標を使用し、市場で特定の高確率の機会を探す戦略を作成するとします。 RSI値が85を超えていると同時に、MACDラインが20を下回っている場合は、ショートポジションをオープンする良い機会を意味しますか? インジケーターのすべての組み合わせを手動で計算しようとして数日/数週間/数か月を費やすか、強力で簡単に解釈できるアルゴリズムであるディシジョンツリーを使用できます。
まず、デシジョンツリーがどのように機能するかを見てから、それらの使用をバンクオブアメリカ株式取引戦略の構築の例として考えてみましょう。
決定木の仕組み
デシジョンツリーは、最も一般的な機械学習アルゴリズムの1つです。強力なノイズのあるデータをシミュレートし、非線形の傾向を簡単に識別し、インジケーター間の関係をキャッチできるためです。 さらに、それらは容易に解釈可能です。 決定木は、データ分析にトップダウンの「分割統治」アプローチを使用します。 彼らは、データを2つの反対のグループに最適に分割するインジケーターとインジケーター値を探しています。 次に、アルゴリズムは各グループでこのプロセスを繰り返し、各データポイントを分類するか停止基準に達するまで続行します。 この場合、データは「Up」または「Down」の2つのグループのいずれかに属します。 ノードと呼ばれる各分割は、結果のブランチの純度を最大化しようとします。 この場合の純度は、データがグループの1つに属する確率であり、各ノードの複雑さパラメーターによって特徴付けられます。
ディシジョンツリーは、テストデータを簡単に再トレーニングし、新しいデータにひどい結果を与えることができます。 この問題を解決するには、次の3つの方法があります。
•複雑度パラメーターのしきい値または各ブランチのデータポイントの最小数を指定してサブセットを修正することにより、ツリーの成長を制御できます。 これにより、より広いモデルを包含しようとするツリーが作成され、データセットに固有の小さなサブセットに焦点が当てられません。
•構築後にツリーを剪定することもできます。 これは通常、相互検証エラーを最小限に抑えるツリーサイズを選択することによって行われます。 相互検証は、データを複数のグループに分割し、1つを除くすべてのグループを使用してモデルを構築し、残りのデータグループを使用してモデルをテストするプロセスです。 その後、このプロセスが繰り返され、各グループがテストに使用されます。 次に、平均エラーが最小のツリーが選択されます。 この方法は、データ量が限られている場合の再トレーニングを防ぐのにも適しています。
•最も難しい方法は、多くの異なるツリーを構築し、意思決定のためにそれらを共有することです。 複数の決定木を構築するための3つの一般的な方法があります。「バッグ」、「高架」木、およびランダムフォレストです。 おそらく以下の記事では、これらの方法をさらに詳しく検討します。
決定木の基本的な理解ができたので、戦略を構築しましょう!
戦略構築
4つの技術指標に基づいて戦略を構築し、BoA株の動きを判断する方法を見てみましょう。
始めるために、必要なライブラリがすべて揃っていることを確認しましょう。
install.packages("quantmod") library("quantmod") # install.packages("rpart") library("rpart") # , . install.packages("rpart.plot") library("rpart.plot") #
次に、データを取得してインジケーターを計算しましょう。
startDate = as.Date("2012-01-01") # endDate = as.Date("2014-01-01") # getSymbols("BAC", src = "yahoo", from = startDate, to = endDate) # Bank of America RSI3<-RSI(Op(BAC), n= 3) # 3- (RSI) EMA5<-EMA(Op(BAC),n=5) # 5- (EMA) EMAcross<- Op(BAC)-EMA5 # 5- EMA MACD<-MACD(Op(BAC),fast = 12, slow = 26, signal = 9) # MACD(/ ) MACDsignal<-MACD[,2] # SMI<-SMI(Op(BAC),n=13,slow=25,fast=2,signal=9) # SMI<-SMI[,1] #
次に、予測する変数を計算し、データセットを形成します。
PriceChange<- Cl(BAC) - Op(BAC) # Class<-ifelse(PriceChange>0,"UP","DOWN") # . DataSet<-data.frame(RSI3,EMAcross,MACDsignal,SMI,Class) # data set colnames(DataSet)<-c("RSI3","EMAcross","MACDsignal","Stochastic","Class") # DataSet<-DataSet[-c(1:33),] # , TrainingSet<-DataSet[1:312,] # 2/3 TestSet<-DataSet[313:469,] # 1/3
必要なものはすべて揃ったので、すでにこのツリーを構築しましょう!
DecisionTree<-rpart(Class~RSI3+EMAcross+MACDsignal+Stochastic,data=TrainingSet, cp=.001) # , , (), .
いいね! 最初の決定木があります。何を構築したか見てみましょう。
prp(DecisionTree,type=2,extra=8) # , .
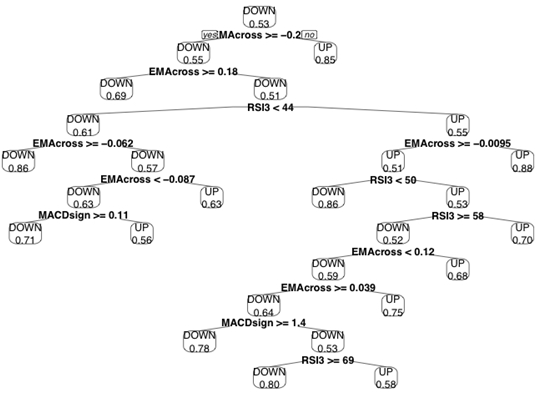
視覚化を自分でプレイしたい場合、 ここに素晴らしいリソースがあります
このツリーの解釈に関する小さなメモ:ノードは分割を表し、左のブランチは答え「はい」を反映し、右のブランチは「いいえ」と答えます。 最終シートの数字は、このノードによって正しく分類されたケースの割合です。
決定木を使用して、インジケータを選択および評価することもできます。 ツリーのルート(上部)に近いインジケーターは、ツリーの下部にあるものよりも多くの区分を提供し、より多くの情報を含みます。 私たちの場合、確率的発振器は木にさえ当たりませんでした!
これで、従うことができる一連のルールが作成されましたが、モデルを再トレーニングしていないことを確認する必要があるため、ツリーをトリムしましょう。 これを行う最も簡単な方法は、複雑さのパラメーターを調べることです。これは、「コスト」またはパフォーマンスの低下です。 これを行うには、別のパーティションを追加し、クロス検証エラーを最小化するツリーサイズを選択します。
printcp(DecisionTree) # cp( ) , plotcp(DecisionTree,upper="splits") #
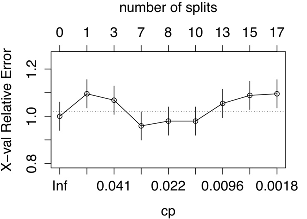
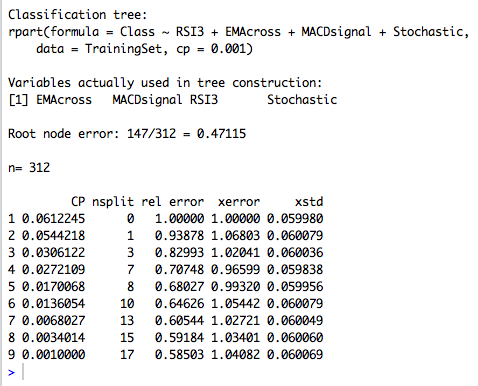
7つのパーティションのツリーで最小のエラーが達成されていることがわかります。 モデルをテストするためのデータをランダムに選択する相互検証モードのおかげで、結果はスクリーンショットに表示されているものと異なる場合があります。 決定木の欠点の1つは、安定していない可能性があることです。 小さなデータの変更は、ツリーの大きな変更につながる可能性があります。 したがって、ツリーを「プルーニング」するプロセスと、再トレーニングを防止する他の方法は非常に重要です。
このツリーをトリムして、戦略がどのようになるかを見てみましょう。
PrunedDecisionTree<-prune(DecisionTree,cp=0.0272109) # (cp), (xerror)
これで、ツリーは次のようになります。
prp(PrunedDecisionTree, type=2, extra=8)

はるかに良い! ここで、MACD信号ラインが使用されなくなっていることがわかります。 4つのインディケーターから始めましたが、そのうち3日間のRSI、価格の差、および5日間のEMAのみが価格変動の予測に役立ちます。
テストデータを使用してモデルをテストします。
table(predict(PrunedDecisionTree,TestSet,type="class"),TestSet[,5],dnn=list('predicted','actual'))
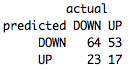
一般的に、悪くない、52%の精度。 さらに重要なのは、明確に定義された数学的パラメーターを使用した戦略の基礎があることです。 25チームのみを使用して、どの指標が有用か、トランザクションを完了するためにどのような特別な条件が必要かを判断できました。 これで、これらの指標を自分の取引に使用したり、ツリーを改善したりできます。
次の記事では、別の強力な機械学習アルゴリズムであるサポートベクトル法を検討し、その結果をさらに堅牢な戦略に使用する方法について説明します。