Mars rover2ボード用の次のゲーム(トレーニング)FPGAプロジェクトに取り組んでいると、クリスタルに十分なスペースがないことが明らかになりました。 プロジェクトはそれほど複雑ではないようですが、私の実装では多くのロジックが必要です。 原則として、これはナンセンスであり、日常的なものです。 本当に必要な場合は、大容量のFPGAを選択できます。 実際、私のプロジェクトはゲーム「Life」ですが、Verilog HDL言語でFPGAに実装されています 。
ゲームのロジックについては、 すでに十分に記述されているので 、それについては説明しません。
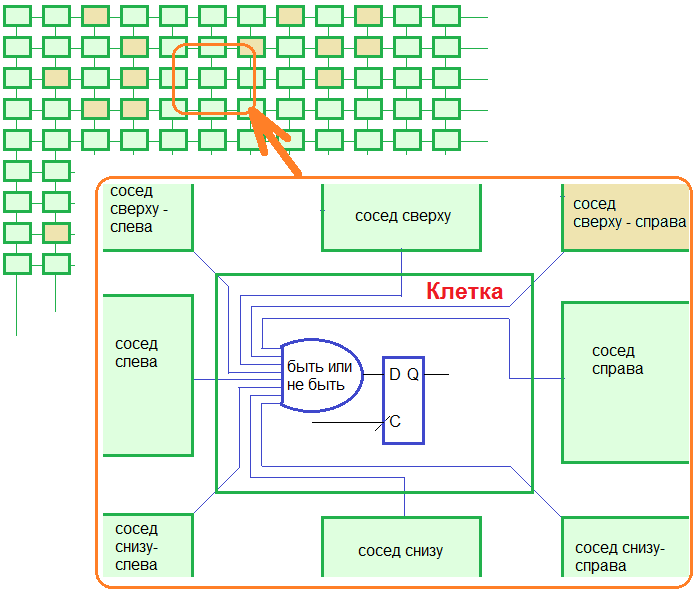
プロジェクトのアイデアは次のとおりです。競技場の各セルは独立した計算機です。 各計算機には独自の論理機能と独自のレジスタがあり、セルの現在の状態(ライブ/非ライブ)を保存します。 セルの存続期間全体が電卓の2次元配列であり、電卓はネットワーク全体を形成します。 単一のクロック周波数がすべてのレジスタに適用されるため、すべての計算機は同期して動作します。 上の図は、プロジェクトの設計を明確にする必要があります。
だからここに。 AlterのCyclone III EP3C10E144C8 FPGAがボード上にあります。 1万個の論理要素。 最初は、128x64 = 8192個のセルの2次元配列を作成できると考えました。 収まりません。 64x64 = 4096-同じものは水晶に適合しません。 どうして。 FPGAには32x16 = 512セルしか収まりませんでした。 ピカルカ...
振り返ってみると、将来、FPGAテクノロジはプログラマブルロジック以上のものに発展する可能性があるという考えに至りました。 ここで、このビジョンについてお話したいと思います。 私はすぐに洗練された読者に、さらに書かれたものは想像力の単なる想像であり、ナンセンスでさえあるかもしれないと伝えます。
しかし..
現在、FPGAテクノロジーは、かなり狭い専門家グループによって使用されています。 FPGAは主に、マイクロ回路のプロトタイピングや、ASICのマイクロ回路の製造が経済的に不可能な小規模製品に使用されます。 FPGAの専門家はそれほど多くないと思います。 この技術は非常に複雑であり、多くの特定の知識が必要です。 一方、FPGAは、おそらく高速で並列のコンピューティングを編成するのに最も適したテクノロジーです。
たとえば、 アルテラはOpenCLテクノロジを提供および促進していることを知っています
簡単に言えば、これは、FPGAアクセラレータでの並列計算を記述するためのCのような言語です。 ところで、Nvidiaとそのビデオカードは、OpenCLを使用した並列コンピューティングもサポートしています。
したがって、アルテラがFPGAの「通常の」Cのような並列コンピューティングを人々に伝える方法について明確に考えていることは明らかです。 FPGAを使用した並列コンピューティング用のボードの価格はどうですか? ボードTerasic DE5-Net。
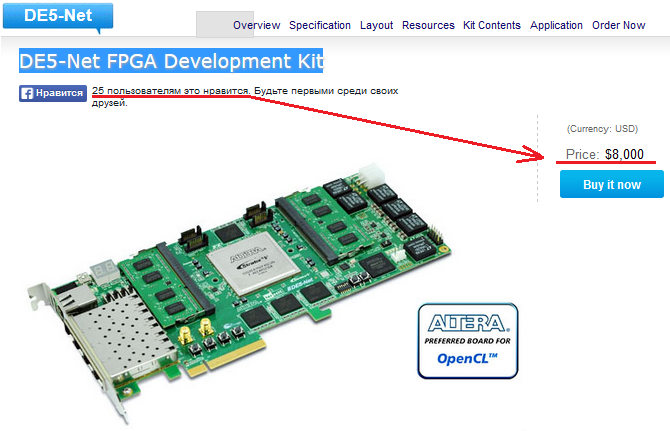
8,000ドルの価格が好きな25人のユーザー(冗談です)。
FPGAを人々に提供する他の試みがあります。アルテラは、AtomプロセッサとArria II FPGAが単一のパッケージで接続されたIntel E6x5Cシリーズチップと共にリリースされました。 良い試みですが、技術は大量消費者を見つけることができないようです。
どうやら、既存のFPGAクリスタルは最新のプログラミングパラダイムにうまく適合しないようです。
そして、「通常の」プログラミングの現在のパラダイムは何ですか?
私にはこのようなもののようです:
- 複数のコンピューティングプロセスとスレッドが常にコンピューターで同時に実行されている
- プロセスとスレッドの状態はメモリに保存され、プロセスは必要に応じてOSからメモリを要求できます。 物理メモリよりも多くを要求することもできます-プロセスは実際にこの仮想メモリを取得できます。
- 計算はプロセッサによって行われますが、多くのコアを備えている場合もあります。 通常、プロセスまたはスレッドは、タスクが現在実行しているプロセッサコアを認識しません(または知りたくない)。
- 優先度の高いタスクが優先度の低いタスクに取って代わることがあります。 強制終了とは、動作の遅いプロセスのメモリページの状態をディスクに保存し、優先度の高いプロセスに切り替えることを意味します。 より大きなタイムスライスを割り当てます。
メモリとプロセッサコアが多いほど、システム内のすべてのプロセスが高速に動作することは明らかです。
メモリとプロセッサコアは、オペレーティングシステムがプロセス間で分散するコンピューターであるコンピューターのリソースです。
ここで、将来、メモリやプロセッサコアとともに、like-like-plisのロジックブロックがさらに増えるコンピューターを手に入れることを想像してください。 この「as-is-a-plis」リソースは、そのプロパティにより、プロセッサとメモリの間のどこかにあります。 一方で、「いいね」とは、コンピューター、つまりプロセッサーに近いことですが、一方で、メモリーでもあります。これは、多くの情報がplisレジスターに格納されるためです。 タスクコンテキストを切り替えるときに、「as-as-plis」計算機の状態をtask_struct構造体に保存することは、すでに非常に困難です。 しかし、おそらく、論理ブロックの状態を仮想メモリのようなスワップファイルに強制しようとすることができます。 そして一時的に、OSはアクティブなスレッドのためにロジックの他のブロックをロードできます...
ところで、アルテラとザイリンクスの両方には、個々のセクション、ロジックブロック( パーシャルリコンフィギュレーション )を部分的にリロードする機能を備えたFPGAが長い間ありました。
プログラマは、必要に応じてできるだけ多くのプロセスをプロセスに割り当てることができます。 文字通り、関数lalloc(論理alloc)はmalloc(メモリalloc)に似ています。 次に、ファイルから「FPGAファームウェア」を読み取ると、動作します。 概してプログラマは、システムにこのメモリ/ロジックが「似たような」ものであるかどうかを考えるべきではありません。 そして、これは私たちのビジネスではありません。 はい、リソースが限られているために非常に遅くなる場合がありますが、弱いビデオカードでビデオゲームを「遅らせる」方法がわかりませんか。 ユーザーは強力なハードウェアにお金を払わなければならないことを知っていますが、プログラムで使用するための論理「like-or-plis」論理ブロックがすでに最小システムにさえあればいいのですが。
実際、もちろん、私はそのような技術がすぐに登場する可能性は低いと思います。これはすべて複雑すぎて実行不可能です。 JTAGなどの低速のシリアルインターフェイスを使用してFPGAを構成する場合にのみ、少なくとも既存のFPGAはこれらの目的にはほとんど使用されません。 しかし、いつか私たちのうちの誰かがこれをするでしょうか?
PS:ちなみに、FPGAでの私のゲームライフは非常に小さく、32x16です...まあ、遊び場をより広く、より高くするための仮想の「like-to-plis」メモリはありません...
PS2:ゲームLifeのプロジェクトのすべてのソースと詳細な説明は、 ここで入手できます 。