
Webサービスや他の多くのシステムの作業では、さまざまなバックグラウンドタスクを実行する必要がしばしばあります。 これを行うために、彼らは利用可能なタスクのリストを取得し、それらを実行し始めるスクリプト-vorkers-をいくつかの速度で、いくつかのシーケンスで書きます。
明確なビジネス、それはすべてのタスクが迅速かつ遅滞なく実行される場合に適しています。
タスクの実装を高速化するには、次の2つの問題を解決することが望ましいです。
- タスクの個々の段階の完了を待たないことを労働者に教えるために(非同期)
- ワーカーに複数のタスクを同時に実行することを教えるために(マルチスレッド)(免責事項:実際には、「マルチスレッド」という用語は「マルチプロセッシング」を意味するためにここで使用されます)
この記事では、非同期およびマルチスレッドの両方であるワーカーの実装オプションを検討します。
AnyEventモジュール
Pearlの非同期モードでのプログラミングには、優れたAnyEventモジュールがあります。
念のため、実際にはAnyEventは他の低レベルの非同期モジュールのラッパーであると言っておくべきです。 DBIがさまざまなデータベースのラッパーおよびユニバーサルインターフェイスであるように、AnyEventは非同期エンジンのさまざまな実装に対するラッパーおよびユニバーサルインターフェイスです。
AnyEventには、マルチスレッドアプリケーションを作成するための拡張機能を含む、 AnyEvent :: Fork :: Poolモジュールなど、膨大な数のさまざまな拡張機能があります。
AnyEvent :: Fork :: Poolモジュールは、非同期マルチスレッドモードでタスクを処理するワーカーのプールを簡単に作成する方法を提供します。
スクリプト
anyevent_pool.plスクリプトを検討してください。
#!/usr/bin/perl use strict; use warnings; use AnyEvent::Fork::Pool; # my $mod = 'Worker'; # my $sub = 'work'; # my $cpus = AnyEvent::Fork::Pool::ncpu 1; # my $pool = AnyEvent::Fork ->new ->require ($mod) ->AnyEvent::Fork::Pool::run( "${mod}::$sub", # :: - init => "${mod}::init", # ::init - max => $cpus, # idle => 0, # load => 1, # ); # for my $str (qw{q2 rtr4 ui3 asdg5}) { $pool->($str, sub { print "result: @_\n"; }); }; AnyEvent->condvar->recv;
ボリュームが小さいにもかかわらず、このスクリプトは本格的な非同期マルチスレッドアプリケーションです。
それを分解してみましょう。
変数
# my $mod = 'Worker'; # my $sub = 'work';
これらの変数は、プールと特定のバックグラウンドタスクを実行するコード間の接続を定義します。 プールは1つですが、タスクは異なる場合があります。 これらの変数は、特定のタスクを実行するために実行するコード(モジュールの機能)をプールに示します。
たとえば、テキストを処理するためのテキストモジュールがあり、そのモジュールには長さおよびトリミング機能があります。 また、サイズ変更機能やトリミング機能を持つことができるImageモジュールもあります。 Pooleは、関数が何をするか、どのように配置されるかを気にしません。 プールにどのモジュールが存在し、何が呼び出されているかをプールに伝えるだけで、プールはそれらを実行します。
重要! ワーカーモジュールは、「ワーカーを使用」を介してスクリプトに接続する必要はありません。 プール自体がワーカーモジュールを自動的にロードします。変数にモジュールの名前を正しく指定するだけです。
コアの数
# my $cpus = AnyEvent::Fork::Pool::ncpu 1;
マルチスレッドタスクの場合、システム内のコアの数を知ることが望ましいです。 開始するスレッドの数はコアの数と等しいことをお勧めします。 スレッドの数が少ないと、一部のコアが無駄になり、スレッドの数が増えると、一部のスレッドがキューに入れられ、高速化する代わりにスケジューリングの損失が発生します。
何らかの理由でコアの数を決定できなかった場合、手動で指定された値が使用されます。 この場合、1です。
プール
# my $pool = AnyEvent::Fork ->new ->require ($mod) ->AnyEvent::Fork::Pool::run( "${mod}::$sub", # :: - init => "${mod}::init", # ::init - max => $cpus, # idle => 0, # load => 1, # );
パラメーターの説明:
- ワーカーの仕事関数は、常に最初のパラメーターで示される必要があります。 これはモジュール自体の機能そのものであり、最初の2つの「調整」変数$ modおよび$ subで示しました。 これが唯一の必須パラメーターです。
- init-ワーカーに初期化が必要な場合、このパラメーターで初期化関数の名前を指定できます。 この場合、関数の名前は「init」として示されます。これは、このような関数の通常の名前であるためですが、原則として、他の名前を指定できます。
- max-このパラメーターは、プールが開始するスレッドの数を設定します。 ここで、システム内の以前に決定したコアの数を指定する必要があります(ただし、必要に応じて、何をしているのかわかっている場合は任意の数を指定できます)。
- アイドル-「低スタート」で待機するワーカーの数がここに示されます。 この数値が大きいほど(ただし、maxパラメーター以下)-プールは新しい着信タスクに高速に応答しますが、無駄な待機(およびリソース消費)プロセスが多くなります。
- load-前のタスクの実行を待たずに各ワーカーに与えられるタスクの数。 値は状況に大きく依存します-場合によっては、少ないほど良い、ある場合により良いです。 他のすべての条件が等しい場合、重要性が高まるとプールの効率が向上します(卸売-安い)。
ここでは考慮しない他のパラメーターもあります。 それらは非常に具体的で、ほとんど必要ありません。 パラメータの完全なリストは、モジュールのドキュメントに記載されています。
プーリングタスク
# for my $str (qw{q2 rtr4 ui3 asdg5}) { $pool->($str, sub { print "result: @_\n"; }); };
プールには任意の数のパラメーターを渡すことができますが、最後のパラメーターはコールバックにする必要があります。 コールバックは、ワーカーがタスクを完了した後に呼び出される匿名関数です。 ワーカーの結果はこの関数に転送されます。
つまり、この関数は、$ sub関数の結果のレシーバーです。 $ sub関数が返すものはすべて、コールバック関数に引数として渡されます。 条件付きで、この関係は次のように書くことができます-「コールバック($ sub)」。
私たちの場合、コールバック関数は受け取ったものをすべて単に出力します。
$ str変数は、実際には、ワーカーが実行する必要のあるまさにタスクです。 私たちの場合、これは1行だけです(より正確には、4行がループで起動されます)。 ここの線には深い意味はありません。キーボードの上を歩くために猫を呼び出しました。
状況に応じて、文字列の代わりに、ファイル名、データベース内のレコードの識別子、数式、複雑なデータ構造へのリンクなど、何でも構いません。 プールは、それが何であろうと関係なく、この値を処理しません。 プールは単純にこの値をワーカーに渡しますが、彼はそれをどうするかをすでに知っている必要があります。
エンジンの打ち上げ
AnyEvent->condvar->recv;
この行は、イベントエンジンを起動し、無限に動作し続ける必要があることをAnyEventモジュールに伝えます。
この時点で、スクリプトはループします。 上記の例には、処理タスクの無限のサイクルを停止して終了する方法がありません。 AnyEventサイクルからの条件付き出口の問題はより一般的であり、ここではプールを使用する特別なケースのみを検討します。 サイクルの条件付き終了については、 こちらをご覧ください 。
労働者自身
ここで疑問が生じます-実際、労働者自身はどこにいるのでしょうか? 作業を直接実行するコードはどこにありますか?
このコードは、$ mod変数で指定した別のモジュールに配置されます。
Workerモジュールのコードは次のとおりです。
package Worker; use strict; use warnings; my $file; sub init { open $file, '>>', 'file.txt'; my $q = select($file); $|=1; select($q); return; } sub work { my ($str) = @_; for (1..length($str)) { print $file "$$ $str\n"; sleep 1; }; return $str, length($str); } 1;
ご覧のとおり、モジュールにはinitとworkの2つの関数があります。
init関数はワーカーを初期化します。 この場合、関数はログファイルを開き、そこに作業関数workの結果が表示されます。 前述のように、init関数はオプションです。この例では、わかりやすくするために作成しました。
仕事関数はメイン関数です。 これは、$ sub変数で設定されたものと同じ作業関数です。 この関数では、特定のタスクの実装に関連するすべての作業が実行されます。
私たちの場合、関数は最も単純な仕事をします-文字列の長さを計算します。 ワーカーの作業をより視覚的に示すために、関数に2番目の遅延を伴うループを追加しました。これにより、ログの行が文字の行と同じ回数だけ表示されます。
注意してください-関数は、文字列自体とその長さの2つの値を返します。 これらの2つの値は、タスクをプールに設定する段階で指定されたコールバックに転送されます(前述のコールバックでは、これらの値は単に出力されます)。
実際、ここにコード全体があります。
プールを開始します
プールを実行して、何が起こるか見てみましょう:

ここで、プールの結果を確認します。 出力の順序が、スクリプトのループで指定された行の順序と異なることに気付くかもしれません。 理由は明らかです-ラインの長さが異なるため、ワーカーはラインを異なる速度で処理します。 タスクが単純であるほど、完了は速くなります。
では、結果だけでなく、労働者の作業プロセスも見てみましょう。 これを行うには、2番目のウィンドウで、ログファイルに対してtailを実行します。
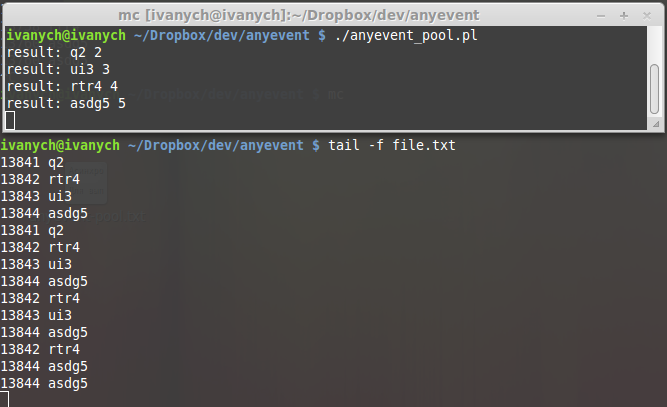
注意してください-タスクは同時に実行されるため、結果はまちまちです。 プロセス識別子は左側に表示されます-4つのプロセスが関係していることがわかります。 システムには4つのコアがあるため、4つのタスクはすべて同時に実行されます。
最後に、プロセステーブルを見てください。

これが、プールのプロセスツリーの外観です。
リストの最初にスクリプトがあり、次にプールマネージャー(はい、複数のプールが存在する可能性があります)、プールマネージャー、最後にワーカーです。
怠tooすぎず、プロセス識別子を比較すると、ワーカーの識別子がログファイルの識別子と一致していることがわかります。