翻訳者のメモ2.コードは小さく、R言語で記述されていますが、これまでに見たことがない場合でも絶望しないでください。 この記事の前に、私は彼についても何も知りませんでしたので、記事で見つけられるものすべてを含め、言語で「拍車」を具体的に書きました。 自分で理解したい場合は、 CodeSchoolの小さなコースから始めることをお勧めします 。 habrには興味深い情報と役立つリンクもあります 。 そして最後に、大きなチートシートがあります。
翻訳者注3.記事は2つのパートで構成されていますが、最も興味深いパートは2番目のパートでのみ開始されるため、それらを1つの記事にまとめることができました。

パート1
この一連の記事では、簡単な機械学習ベースの資産管理戦略を段階的に構築してテストします。 最初の部分では、機械学習の基本概念と金融市場への応用について説明します。
機械学習は、金融数学の最も有望な分野の1つであり、近年、洗練された複雑なツールとしての評判が高まっています。 現実には、すべてがそれほど複雑ではありません。
機械学習の目標は、履歴データに基づいて正確なモデルを構築し、このモデルを将来の予測に使用することです。 金融数学では、機械学習を使用して、次のタスクが解決されます。
- 回帰。 数量の方向と価値を予測するために使用されます。 たとえば、1日あたりのGoogleシェアの価値が7.00ドル増加します。
- 分類。 たとえば、1日あたりのGoogle株式の価値の方向など、カテゴリを予測するために使用されます。
簡単な例を考えてみましょう。 Google株の価値の動きを1日前に予測してみましょう。 次のパートでは、いくつかのインジケーターを使用しますが、ここでは基本を学習するために、インジケーターを1つだけ使用します:曜日です。 それでは、曜日に基づいて価格の動きを予測してみましょう。
以下は、Google株のグラフと、Yahoo Financeからエクスポートされたデータの写真です。


曜日列と終値列から始値を引いた列を追加しました。 また、終値と始値の差が0より大きい場合は「UP」、小さい場合は「DOWN」と書く価格方向列を追加しました。
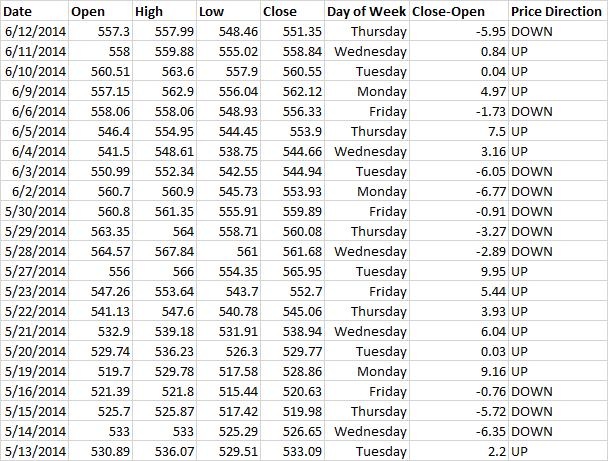
機械学習では、アルゴリズムがそれらから学習するため、このデータセットはトレーニングと呼ばれます。 つまり、アルゴリズムはデータセット全体をスキャンし、曜日と株価の変化の方向との関係を確立します。 セットが小さいことに注意してください-23行しかない。 次のパートでは、数百行を使用してモデルを構築します。 実際、データが多ければ多いほど良いです。
それでは、アルゴリズムを選択しましょう。 隠れマルコフモデル、人工ニューラルネットワーク、単純ベイズ分類器、サポートベクトル法、決定木、分散分析など、使用できるアルゴリズムは多数あります。 以下に、各アルゴリズムを理解し、いつどのアルゴリズムを適用するかを理解できる良いリストを示します。 まず、最も一般的に使用されているアルゴリズムの1つ、たとえばサポートベクターメソッドや単純ベイズ分類器の使用をお勧めします。 選択に多くの時間を費やさないでください。分析の最も重要な部分は、使用する指標と予測する値です。
パート2
戦略で機械学習アルゴリズムを使用する基本的な概念を理解したので、単純なベイズ分類器を使用してAppleの株価の方向を予測する簡単な例を検討します。 まず、この分類子がどのように機能するかを理解してから、曜日を使用して価格の動きを予測する非常に簡単な例を検討し、最終的にはテクニカルインジケーターを追加してモデルを複雑にします。
単純ベイズ分類器とは何ですか?
ベイズ式を使用すると、イベントBが既に発生していることがわかっている場合にイベントAが発生する確率を見つけることができます。 通常、P(A | B)として指定されます。
この例では、「今日が水曜日であることがわかっている場合、今日の価格が上昇する可能性はどのくらいですか?」 この方法では、成長が観察された合計日数に基づいて今日の価格が上昇する確率と、今日が水曜日であるという事実、つまり水曜日に価格が何倍に成長したかという事実の両方を考慮します。
今日の価格が上昇する可能性と下落する可能性を比較し、最高値を予測として使用する機会があります。
これまで、1つの指標についてのみ説明しましたが、それらがいくつかあるとすぐに、すべての数学がより複雑になります。 これを防ぐために、 単純なベイズ分類器が使用されます (これは良い記事です)。 各インディケーターを独立したものとして、または相関していないものとして扱います(したがってナイーブという用語)。 したがって、弱いかまったく関連しないインジケーターを使用することが重要です。
これは、単純なベイズ分類器の非常に簡略化された説明です。他の機械学習アルゴリズムと同様に、さらに学習することに興味がある場合は、 こちらをご覧ください。
Rのステップバイステップの例
Rに拍車をかける
仕事に必要なもの:
言語自体は非常にシンプルです。 スクリプトファイルは作成できません。すべてがコンソールに直接書き込まれます。
さて、順番に、すべてが満たされます:
言語には厳密な型指定はありません;変数を宣言する必要はありません。 値を割り当てるには、「<-」記号を使用します
例:
ベクトルは次のように割り当てられます。
データフレームという特別なタイプがあります。 視覚的には、表に表示するのが最も簡単です。 例(CodeSchoolから取得):
行/列の範囲を指定できます。 たとえば、1行目から4行目までのすべての列を表示するには、次のように記述します。
すべての行と2番目の列のみを表示するには:
言語自体には、最初は多くの関数が存在しないため、一部のライブラリを接続して動作させる必要があります。 このために、それは規定されています:
関数を呼び出すとき、追加のパラメーターは次のように記述されます:parameter_name = value。 例:
具体的には、この関数はyahooから株価データをアップロードします。 詳細については、マニュアルをご覧ください : www.quantmod.com/documentation/getSymbols.html
残りについては、質問はないと思います。
- R言語インタープリター
- IDEとして、 RStudioを使用しました。
言語自体は非常にシンプルです。 スクリプトファイルは作成できません。すべてがコンソールに直接書き込まれます。
さて、順番に、すべてが満たされます:
言語には厳密な型指定はありません;変数を宣言する必要はありません。 値を割り当てるには、「<-」記号を使用します
例:
a <- 1.
ベクトルは次のように割り当てられます。
a <- c(1,2,3)
データフレームという特別なタイプがあります。 視覚的には、表に表示するのが最も簡単です。 例(CodeSchoolから取得):
> weights <- c(300, 200, 100, 250, 150) > prices <- c(9000, 5000, 12000, 7500, 18000) > types <- c(1, 2, 3, 2, 3) > treasure <- data.frame(weights, prices, types) > print(treasure) weights prices types 1 300 9000 1 2 200 5000 2 3 100 12000 3 4 250 7500 2 5 150 18000 3
行/列の範囲を指定できます。 たとえば、1行目から4行目までのすべての列を表示するには、次のように記述します。
treasure[1:4,]
すべての行と2番目の列のみを表示するには:
treasure[,2]
言語自体には、最初は多くの関数が存在しないため、一部のライブラリを接続して動作させる必要があります。 このために、それは規定されています:
install.packages("lib_name") library("lib_name")
関数を呼び出すとき、追加のパラメーターは次のように記述されます:parameter_name = value。 例:
getSymbols("AAPL", src = "yahoo", from = startDate, to = endDate)
具体的には、この関数はyahooから株価データをアップロードします。 詳細については、マニュアルをご覧ください : www.quantmod.com/documentation/getSymbols.html
残りについては、質問はないと思います。
次に、Rの非常に簡単な例を見てみましょう。曜日を使用して、Appleの株価が上下するかどうかを予測します。
まず、必要なライブラリがすべて揃っていることを確認しましょう。
install.packages("quantmod") library("quantmod") # install.packages("lubridate") library("lubridate") # install.packages("e1071") library("e1071") #
必要なデータを取得しましょう:
startDate = as.Date("2012-01-01") # endDate = as.Date("2014-01-01") # getSymbols("AAPL", src = "yahoo", from = startDate, to = endDate) # OHLCV Apple Yahoo Finance
必要なデータがすべて揃ったので、「曜日」インジケータを取得しましょう。
DayofWeek<-wday(AAPL, label=TRUE) #
予測するもの、つまり 価格を上下に移動し、最終的なデータセットを作成します。
PriceChange<- Cl(AAPL) - Op(AAPL) # . Class<-ifelse(PriceChange>0, "UP","DOWN") # . ( , , . . , ) DataSet<-data.frame(DayofWeek,Class) #
これで、単純ベイズ分類器を適用する準備ができました。
MyModel<-naiveBayes(DataSet[,1],DataSet[,2]) # , (DataSet[,1]), , , (DataSet[,2]).
おめでとうございます! 機械学習を使用して、Apple株を分析しました。 それでは、結果を見てみましょう。

初期データセット(以前の確率として知られている)に基づいて価格が上昇または低下する確率を表示します。 わずかな弱気バイアスが見られます。

条件付き確率がここに表示されます(各曜日の価格上昇または下落の確率が示されます)。
このモデルは、高い確率を返さないため、あまり良くないことがわかります。 それにもかかわらず、週の初めにロングポジションをオープンし、終わりに近づくほど短くする方が良いことは注目に値します。
モデルの改善
明らかに、単に曜日をターゲットにするよりも複雑な戦略を使用する必要があります。 モデルに移動平均交点を追加しましょう( ここで 、モデルにさまざまなインジケーターを追加することに関する詳細情報を取得できます )。
私は指数移動平均を使用することを好むので、5日および10日の指数移動平均(EMA)を見てみましょう。
まず、EMAを計算する必要があります。
EMA5<-EMA(Op(AAPL),n = 5) # 5- EMA EMA10<-EMA(Op(AAPL),n = 10) # 10- EMA,
次に、交差を計算します。
EMACross <- EMA5 - EMA10 # EMA5 EMA10
次に、値を小数点以下2桁に丸めます。 ナイーブベイジアン分類器がトレーニング中に見なかった値を取得した場合、0%の確率を自動的に計算するため、これは重要です。 たとえば、EMAの交差点を6桁の精度で見て、差が2.349181ドルのときに価格が下落する可能性が高く、その後、2.349182ドルの差、0%の増加確率を持つ新しいデータポイントが表示された場合、値下げ。 小数点以下2桁に切り上げることで、モデルの未知の値に遭遇するリスクを減らします(すべてのインジケーター値が見つかる可能性が高い十分に大きなデータセットがトレーニングに使用された場合)。 これは、独自のモデルを作成するときに留意すべき重要な制限です。
EMACross<-round(EMACross,2)
新しいデータセットを作成して、データをトレーニングセットとテストセットに分割しましょう。 したがって、モデルが新しいデータに対してどの程度うまく機能するかを理解できます。
DataSet2<-data.frame(DayofWeek,EMACross, Class) DataSet2<-DataSet2[-c(1:10),] # , 10- TrainingSet<-DataSet2[1:328,] # 2/3 TestSet<-DataSet2[329:492,] # 1/3
次にモデルを作成します。
EMACrossModel<-naiveBayes(TrainingSet[,1:2],TrainingSet[,3])

移動平均の交差の条件付き確率は、各ケース([、1])および標準偏差([、2])の平均値を示す数値です。 ロングトレードとショートトレードの5日間EMAと10日間EMAの差は、平均でそれぞれ0.54ドルと-0.24ドルであることがわかります。
次に、新しいデータをテストします。
table(predict(EMACrossModel,TestSet),TestSet[,3],dnn=list('predicted','actual'))

翻訳者注4
何らかの理由で、長い間、この表の読み方を理解できませんでした。 厳しい一日を過ごした人にとっては、上下の交差点の数値は、予測が実際のデータと一致した日数です。 したがって、下の列と上の行を見ると、これはモデルが上向きの動きを予測した日数ですが、実際には下向きの動きがありました。
テストサンプルで合計164日。 さらに、我々のモデルの予測は、実データと79回一致するか、ケースの48%で一致しました。
この結果は良いとは言えませんが、独自の機械学習戦略を構築する方法のアイデアを提供するはずです。 次のパートでは、このモデルを使用して戦略を改善する方法について説明します。
Translator's Note 5.これまでに、このシリーズにはさらに2つの記事があります。決定木とニューラルネットワークについてです。 同じスタイルの記事、つまり 深くはありませんが、問題の一般的な考えを伝えるだけです。 興味があれば、翻訳を続けます。 すべてのコメント、不正確、およびその他のエラーについては、個人で書いてください。