
ウィキペディアによると、鬼車は日本語で「悪魔の戦車」を意味します。
私たちは皆、正規表現に精通しています。 彼らは「スイスアーミーデベロッパーナイフ」です。 検索するもの、解析するテキストは、正規表現を使用していつでも実行できます。 実際、Rubyを使用するよりもはるかに早くそれらを使用し始めた可能性があります。これらは、Perl、JavaScript、PHP、Javaなどの最も一般的なプログラミング言語に長い間含まれています。 Rubyは1990年代半ばに登場しましたが、正規表現は1960年代、つまりほぼ30年前に戻ってきました!
しかし、正規表現は実際にどのように機能しますか?
正規表現エンジンの背後にある情報技術について詳しく知りたい場合は、ラスコックスによる素晴らしい一連の記事を読む必要があります。
ラスが書いたすべてを繰り返したくありません。 しかし、Rubyは2番目の記事で説明されている「非再帰的バックトラッキング実装」を使用していることを簡単に指摘します。これは、Perlで正規表現を使用する場合と同様に、パフォーマンスの指数関数的な低下につながります。 言い換えれば、Rubyは最も最適なThompson NFA(非決定性有限状態マシン用のThompsonアルゴリズム)を使用していません。これについては、Russが最初の記事で説明しています。
今日は、Rubyに組み込まれている正規表現エンジンである鬼車を詳しく見ていきます。 いくつかの単純なグラフィカルスキームと正規表現の例を使用して、その仕組みを説明します。 読み続けて、正規表現を使用するたびにRubyの内部で何が起こっているのかを理解してください。おそらく、知らないこともたくさんあります。
鬼車
バージョン1.9から、MRIは「Oniguruma」と呼ばれるオープンCライブラリのわずかに変更されたバージョンを使用して、PHPでも使用される正規表現を処理します。 すべての標準正規表現関数をサポートするとともに、たとえば日本語テキストなどのマルチバイト文字もサポートします。
非常に高いレベルで、これは正規表現が鬼車を通過するときに起こることです:

最初のステップで、鬼車は正規表現パターンを読み取り、それを語彙素に分割し、構文ノードのセットを含むツリー構造(抽象構文ツリー(AST))に変換します。 これは、インタープリター自体がRubyコードを処理する方法と非常に似ています。 実際、鬼車正規表現エンジンは、Rubyに直接組み込まれた2番目のプログラミング言語と考えることができます。 コードで正規表現を使用するときは常に、まったく別の言語で2番目のプログラムを作成します。 正規表現パターンを解析した後、鬼車はそれを一連の命令にコンパイルし、仮想マシン上で実行します。 これらの命令は、ラスコックスが彼の記事で説明しているステートマシンを実装します。
次に、実際に正規表現で検索すると、Oniguruma仮想マシンは、以前にコンパイルされた命令を単純に処理し、指定された文字列に適用することでそれを実行します。
今週、鬼車の仕組みを理解し、ラスコックスが書いていることと比較するために、ONIG_DEBUG_COMPILEおよびONIG_DEBUG_MATCHフラグを設定してRuby 2.0を再構築しました。 これらのフラグを設定すると、いくつかの正規表現を検索したときに多くのデバッグメッセージを表示できました。 それらで、どの仮想マシン命令テンプレートがコンパイルされ、どのように実行されたかを見ました。 ここに私が見つけたものがあります...
例1:文字列の一致
これは、指定された文字列で「茶色」という単語を検索する非常に単純なRubyスクリプトです。
str = "The quick brown fox jumps over the lazy dog." p str.match(/brown/)
再構築されたRubyインタープリターでこのコードを実行すると、多くの追加のデバッグ出力が見られます(表示するよりもはるかに多く):
$ ruby regex.rb PATTERN: /brown/ (US-ASCII) optimize: EXACT_BM exact: [brown]: length: 5 code length: 7 0:[exact5:brown] 6:[end] match_at: str: 140261368903056 (0x7f912511b590) etc ... size: 44, start offset: 10 10> "brown f..." [exact5:brown] 15> " fox ju..." [end] #<MatchData "brown">
キーポイントは次のとおりです。「
0:[exact5:brown] 6:[end]
」-この行は、/ brown / templateのコンパイル時にOnigurumaによってコンパイルされた2つの仮想マシンコマンドを示します。 このプログラムは次のようになります。
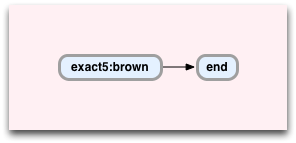
このスキームは、検索/茶色/の状態マシンと考えることができます:
-
exact5:brown
は、現在の位置で指定された文字列の5つの文字 "brown"が存在するかどうかをチェックします。 -
end
は、検索が終了し、見つかった一致を返し、実行を停止することを意味します。
鬼車は、正規表現検索を実行するときに、指定された文字列を使用して仮想マシンでこれらの命令を実行します。 私の例でこれがどのように機能するかを見てみましょう。 最初に、「
exact5:brown
」が、「brown」という単語がある場所の特定の行に適用されます。

鬼車はどのように線の始点を知るのですか? 指定された文字列と仮想マシンの最初の命令に基づいて検索を開始する場所を決定するオプティマイザーが含まれていることがわかります。 上記をご覧ください: "
optimize: EXACT_BM.. exact: [brown]: length: 5.. start offset: 10
"。 この場合、「茶色」という単語を検索する必要があることが正確にわかっていたため、鬼車はその単語が最初に出現した位置にジャンプしました。 はい、これはハックのように聞こえますが、実際には一般的な正規表現での検索アクセラレーションの単純な最適化にすぎません。
次に、
exact5:brown
は
exact5:brown
命令を実行し、次の5文字がパターンに一致するかどうかを確認します。 それらが一致するため、鬼車はそれらの後の位置に移動し、次の命令を実行します。
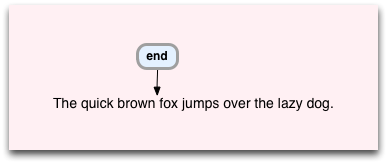
これで最後の命令が実行されます。これは単にすべてが完了したことを意味します。 仮想マシンが「
end
」を実行するたびに、実行を停止し、成功を宣言し、一致する文字列を返します。
例2:2行のいずれかと一致
もっと複雑な例を見て、何が起こるか見てみましょう。 このテンプレートでは、文字列「黒」または「茶色」のエントリを検索します。
str = "The quick brown fox jumps over the lazy dog." p str.match(/black|brown/)
再実行:
$ ruby regex.rb PATTERN: /black|brown/ (US-ASCII) optimize: EXACT exact: [b]: length: 1 code length: 23 0:[push:(11)] 5:[exact5:black] 11:[jump:(6)] 16:[exact5:brown] 22:[end] match_at: str: 140614855412048 (0x7fe37281c950), ... size: 44, start offset: 10 10> "brown f..." [push:(11)] 10> "brown f..." [exact5:black] 10> "brown f..." [exact5:brown] 15> " fox ju..." [end] #<MatchData "brown">
繰り返しますが、ここで重要なのは「
0:[push:(11)] 5:[exact5:black] 11:[jump:(6)] 16:[exact5:brown] 22:[end]
"です。 これは、テンプレート/ black | brown /を検索する仮想マシンプログラムです。

ここではすべてが少し複雑です! まず、オプティマイザーは文字 "b": "
optimize: EXACT.. exact: [b]: length: 1
"のみを検索するようになりました。 これは、単語「黒」と「茶色」の両方がこの文字で始まるためです。
次に、このプログラムの実行をステップごとに見てみましょう。
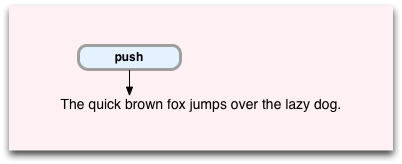
「
push
」コマンドは、文字「b」の最初の場所の位置で実行されます。 次のコマンドを渡し、ソース行に「バックトラックスタック」(バックトラックスタック)と呼ばれるものを配置します。
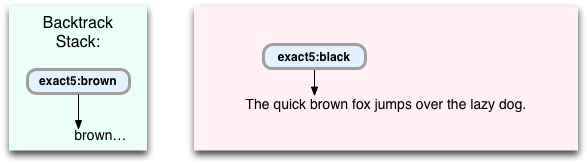
少し後で、Backtrack Stackが鬼車の仕事の重要な場所であることがわかります。 最初のパスで結果が得られなかった場合、彼女はこれを使用して、特定の文字列で代替検索パスを見つけます。 この例を続けてみましょう。私の意味がわかります。
したがって、「
exact5:black
」コマンドを続行しますが、行には「茶色」という単語しかありません。 これは、一致するものが見つからず、検索が成功しないことを意味します。 ただし、結果を返す前に、鬼車は代替検索パスのスタックをチェックします。 この場合、「
exact5.brown
」もあります-正規表現の2番目の部分/ black | brown /。 Onigurumaはこのコマンドを引き出し、実行を継続します。

偶然の一致があるため、鬼車は5文字移動し、次の指示に進みます。
end
コマンドに再び到達したため、一致する値を返すだけです。
例3:構築*
さて、私の最後の例です。 次の正規表現を使用するとどうなるか見てみましょう。
str = "The quick brown fox jumps over the lazy dog." p str.match(/brown.*/)
「茶色」の出現箇所を見つけてから、行末までの任意の文字列を探します。 デバッグ出力を見てみましょう。
$ ruby regex.rb PATTERN: /brown.*/ (US-ASCII) optimize: EXACT_BM exact: [brown]: length: 5 code length: 8 0:[exact5:brown] 6:[anychar*] 7:[end] match_at: str: 140284579067040 (0x7f968c80b4a0), ... size: 44, start offset: 10 10> "brown f..." [exact5:brown] 15> " fox ju..." [anychar*] 44> "" [end] #<MatchData "brown fox jumps over the lazy dog.">
そして、ここに新しいステートマシンがあります。
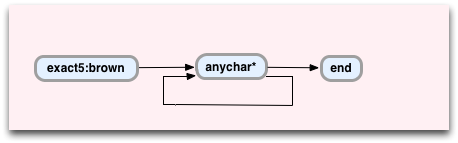
今回は、新しい
anychar*
仮想マシン命令「
anychar*
」を見ることができます。 ご想像のとおり、これは構文パターン「
.*
」を表します。 すべてのステップで何が起こるかもう一度見てみましょう。
「茶色」が初めて表示される行の10番目の位置から再び開始し、再び一致を見つけました。その結果、鬼車はさらに進んで次の指示に進みます。
次の命令は「
anychar*
」であり、その
anychar*
は次のとおりです。
- まず、任意の文字に一致するため、常に1文字ずつ実行をバイアスします。
- しかし、次のコマンドに移動する代わりに、鬼車は戻ってこの命令を再び実行しますが、新しいキャラクターに対してです。
- また、現在の文字と次のコマンド(この場合は「
end
」)をスタックにプッシュします。
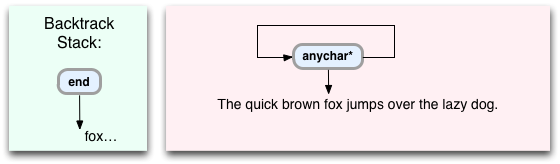
鬼車は、残りの行を単に歩いて、「茶色のキツネが怠け者の犬を飛び越える」ごとにこれらの指示を繰り返します。キャラクター。 行の残りの部分を通過するときに、
end
命令を繰り返し書き込みます。
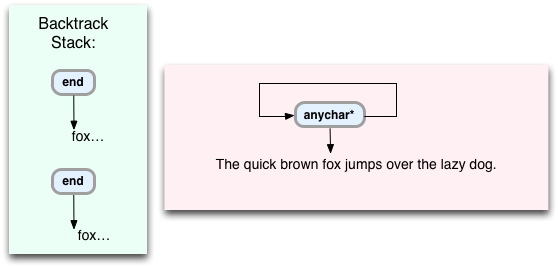
そしてまた:
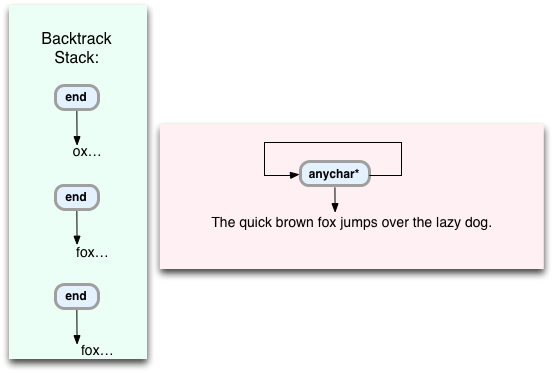
最後に、元の行の終わりに到達します。
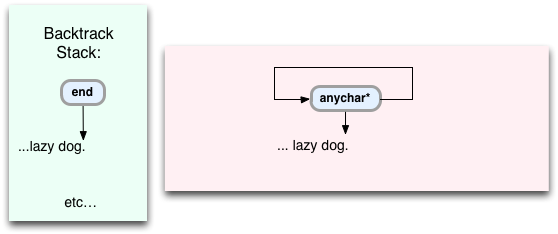
今回は、文字列にこれ以上文字がないため、「
anychar*
」は一致しません。 そのような場合にチームが試合を見つけることができない場合はどうなりますか? 前の例のように、鬼車はスタックからコマンドを削除し、それで検索を続けます。 したがって、この場合、文字列内の一致の最後の位置を示す「
end
」コマンドが実行されます。 つまり、鬼車は「茶色のキツネが怠け者の犬を飛び越える」という行末までのすべてのテキストを受け取ることになります。
しかし、なぜ各文字の後にスタックに「
anychar*
」命令を置くのでしょうか? その理由は、「
.*
」または「
.*
」がより複雑な一般式に埋め込まれた後にさらにいくつかのパターンがある場合、元の文字列のどのセグメントが最終的に完全一致につながるかが明確ではないためです。 おそらく、鬼車はすべてのオプションを試さなければならないでしょう。 この単純な例では、パターンは行末まで正しいため、スタックから複数のコマンドを取得する必要はありません。
1つの興味深い詳細。 「
.*
」の後にコマンドを追加する場合、たとえば/.*brown/を探す場合、鬼車は「
anychar*
」という命令を使用しません。 代わりに、「
anychar*-peek-next:b
」などの別の同様のコマンドを使用します。 ほぼ「
anychar*
」のように機能しますが、スタックのたびに次の位置を行に配置する代わりに、一致の位置、この場合は「b」だけをスタックに配置します。 Onigurumaは次の文字がa bでなければならないことを知っているため、この最適化は機能します。
正規表現パターンの病理学
非常に複雑な正規表現パターンを指定すると、RubyはPerlと同じパフォーマンスの低下を示すと前述しました。 これを実際にコンピューターで再現するのは非常に簡単です。 非常に単純な正規表現検索の例を試してください。
str = "aaa" p str.match(/a?a?a?aaa/)
非常に迅速に実行されるはずです。
$ time ruby regex.rb #<MatchData "aaa"> ruby regex.rb 0.02s user 0.01s system 30% cpu 0.080 total
ただし、3回ではなく29回の繰り返しを使用して繰り返す場合、Russが最初の記事の左側のチャートに示すように、エントリを見つける時間は爆発的に増加します。
str = "aaaaaaaaaaaaaaaaaaaaaaaaaaaaa" # 29 p str.match(/a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?a?aaaaaaaaaaaaaaaaaaaaaaaaaaaaa/)
29回の実行で実行:
$ time ruby regex.rb #<MatchData "aaaaaaaaaaaaaaaaaaaaaaaaaaaaa"> ruby regex.rb 17.09s user 0.01s system 99% cpu 17.098 total
または、30エントリの場合:
$ time ruby regex.rb #<MatchData "aaaaaaaaaaaaaaaaaaaaaaaaaaaaaa"> ruby regex.rb 34.00s user 0.01s system 99% cpu 34.025 total
31エントリの場合、時間は67秒であり、指数関数的に増加します。 これは、鬼車が使用するアルゴリズムが、正規表現パターンの長さに対して指数関数的に増加する可能性のある組み合わせのリストを通過するためです。 OnigurumaとRubyがRussが説明したThompsonアルゴリズムを使用した場合、これは起こりませんでした!
表面的な説明
先ほど言ったように、これは鬼車とRubyができることの表面的な説明です。 おそらくご存知のとおり、使用できる演算子と正規表現オプションは非常に多く、それぞれに仮想マシン内に対応する命令があります。 さらに、私の例は非常にシンプルでわかりやすいものでした。通常のアプリケーションでは、非常に複雑な正規表現をOniguruma仮想マシンで数百の異なる命令にコンパイルすることができます。
ただし、基本的な考え方は常に同じです。 各正規表現は、ステートマシンである仮想マシンの一連の命令にコンパイルされます。 検索中に
anychar*
すると、スタックからターゲットへのパスの異なるバリアントを選択します。各バリアントは、「
anychar*
」演算子または別の同様のコマンドで残すことができます。