成功するためには、いくつかのコンポーネントが必要です。テキストを単語と補題に解析する機能、形態学的および構文解析を実行する機能、そして最も興味深いことに、テキストの意味を検索する機能です。
テキスト解析
インターネットのロシアのセグメントには、非商業的な使用のための無料の構文エンジンがあり、形態学的および構文的な分析の問題を解決する良質のものがあります。 私はそれらのうちの2つに言及したいと思います。
私が最初に大きな利益を得て使用するのはロシア語の文法辞書のSDKです 。
2番目はYandexのtomitaパーサーです。
これらには辞書、シソーラス、解析関数が含まれており、エントリのしきい値はかなり低くなっています。
構文エンジンを使用すると、任意のテキストを機械に優しい形式に変換できます。 これは解析ツリーにすることができ、これによりフレーズ内の単語の関係を追跡できます。
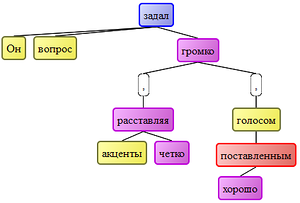
「彼は質問を声に出して、はっきりとしたアクセントをつけて、よくポーズをとった声で尋ねた」
したがって、通常の形式の単語のインデックスのベクトルだけです。
独自のセマンティックネットワークを構築する
残念ながら、ロシア語の場合、 FreeBaseレベルの強力なネットワーク(接続数19億)は現在提供されておらず、 DBPediaのロシア語セグメントは英語よりもはるかに貧弱です。 ABBYYのComprenoが使用する手動検証ネットワークなどの商用ソースも、アマチュアには利用できません。 したがって、ネットワークは独立して形成する必要があります。
必要なのは、辞書、単語間の文法的および意味的なつながりです。
辞書
私は2つの主なソースを使用しました。
アカデミックサイトのウィクショナリーおよび辞書セット。
ウィクショナリーは、最も一般的な単語のセマンティックプロパティと、関連する単語と単語の接続を提供します。 後でこれをどのように使用できるかについて説明します。 アカデミシャンは同義語と反意語の辞書を提示します-ウィクショナリーを完全に補完します。
セマンティックリンク
これは難しいです。 セマンティックリンクは、最近公開されたRuThesシソーラスを含むシソーラスで定義されていますが、すべてのシソーラスの共通の問題はそれらの制限です。 少なすぎる言葉、少なすぎるリンク。 したがって、単語間のつながりは、フィクションライブラリとニュースフィードから合意された一貫性のないNgramの統計の収集に従事することにより、独立して蓄積できます。
ただし、大量のテキストを処理するプロセスは比較的高速です。シングルバイトエンコーディングの1ギガバイトのテキストは、1週間以内に処理できます。
結果は何ですか?
現在使用されているロシア語の単語のほとんどと、単語間の32種類の接続を組み合わせたネットワーク。 「同義語」、「反意語」、「特性」、「定義」などの関係 比較のために、FreeBaseタイプのリンク-14,000以上。 しかし、この控えめなネットワークでも、重要な結果を得ることができます。
類推による結論
システムの入力で、トレーニングサンプルとして、質問と回答のペアが受信されたことを想像してください。
キュウリは何色ですか? 緑のキュウリ。
そして、システムにオレンジ色の色は何ですかという質問に正しく答えてほしいのです。
どうやってやるの? 「キュウリ」と「グリーン」を接続するネットワークを介してこのようなパスを見つける必要があります。 そして、これは「オレンジ」に適用できます。 そして、これを自動的に行う必要があります。 ネットワーク内の単語間の接続が豊富なため、次のようにこの問題を解決できます。
1.緑は色の仮名です( ウィクショナリー日本語版 )。
2.キュウリは緑色と高周波で接続されています(グラムに同意します。これは、処理された文献では、緑色のキュウリと「テーブルに緑色のキュウリがありました」との間に接続があったことを意味します)。
3.したがって、ネットワークを通るパスは、「キュウリ<ngram」の特性「>ゴール<hyperonym(hyponymの逆)>色」として定義されます。
実際、ネットワーク上のパスを見つけるタスクは、無向グラフに沿ってパスを見つける古典的なタスクです。 このようなパスがいくつか存在する可能性があることは明らかであり、それぞれが必要な目標「グリーン」だけでなく、他の同様の単語にもつながります。 たとえば、黄色。 黄色のきゅうり(熟しすぎ)も文献に記載されていますが、緑色のきゅうりよりも頻度は低くなっています。 そして、もちろん、黄色は「色」という言葉に関連して緑とまったく同じです。 したがって、検索の目標が最高の評価となるように、重み係数による各パスの重み付けを実行する必要があります。 少し改革すると、数値ではなく単語を入力信号として認識する自己学習ネットワークを形成していると言えます。
それで、見つかったパスを他の引数に適用してみましょう:
オレンジはオレンジ、海は青、雲は灰色、雲は白です。 草は通常緑色に変わりますが、紫色が現れることもあります。 どうやら、ngramの蓄積により、いくつかの素晴らしい物語が出会ったようです。
しかし、また、海は深く、水たまりは浅く、種は小さいです。 パスは普遍的であり、色だけでなく機能します。 このパスは、「何色/サイズ/深さ...」という特性の値を取得することに焦点を当てたほとんどの問題で機能します。
類似度計算
ネットワークを使用して、異なる単語間の類似度を計算するメトリックを作成できます。 草とキュウリの共通点は何ですか? どちらも緑という言葉に関連しています。 しかし、彼らはまた、「食べる」、「成長する」、そして他の多くの言葉とのつながりを持っています。 したがって、一致する2つの異なる関係の単語の数を計算すると、これらの単語間の類似度を計算できます。 これらの単語が辞書で表されておらず、単語間のすべての接続が統計の蓄積の結果として取得された場合でも。
単語間の類似度の数値をどのように使用できますか? たとえば、相互結合を決定します。 「市長」と「公務員」という言葉は、しばしば同じ文脈で言及され、したがって、他の言葉との関係の互いに近い構造を持っています。 分析されたテキストでは、同じ人が「市長」と「公務員」という言葉の後ろに隠れていると合理的に推測できます。 つまり、それらの間の接続を確立します。
同様に、本文で「彼が行った」と出会ったとき、私たちは歩く物体-人または動物について話していると計算できます。 または、役人は人に非常に似ているためです。 「閉じられました」というテキストで会ったので、私たちは企業、または企業に類似したオブジェクトについて話していると計算できます。
したがって、類似性の計算により、その文脈を考慮して、よく知られているクラス「人」、「企業」、「場所」などの1つに単語を割り当てることができます。
たとえば、このアプローチにより、このようなテキストを分離し、「she」という単語の意味を正しく判断できます。
ソコロフ工場のディレクターが会議で話をしました。 5月初旬にオープンしたことをお知らせします。 ソコロフ工場のディレクターが会議で話をしました。 彼女は生産を増やす計画を発表しました。
最後の部分
最近の機械言語学に関する国際会議「対話」の一環として、コンピューター言語システムのレビューが開催され、私はそこに参加しました。 私のシステムは、1.5か月間の競争のために特別に開発されたもので、単語間の類似性を計算するための記述された技術に基づいていました。 近い将来、競争の結果が公開されます。
いずれにせよ、私は「技術が成熟した」という事実に特別な注意を払いたいと思います。興味のある人は、テキストを理解し、意味を抽出する問題に文字通り数ヶ月以内に来ることができます。 つまり-以前は学術界でのみ利用できた人工知能の分野での実験。