
こんにちは、Habrahabr!
クォータニオンデータは、FPGA DE5-NET、XeonPhi 7120P、およびTesla k20 GPUを使用して暗号化されました。
3つすべてのピークパフォーマンスはほぼ同じですが、消費電力に違いがあります。
不要な情報で記事を積み上げないために、対応するウィキペディアの記事でクォータニオンと回転行列が何であるかについての簡単な情報を理解することをお勧めします。
QESアルゴリズムの暗号強度を調べるには、検索エンジンを使用してアルゴリズムの詳細な説明を求めてください。著者の1人はNagase T.で、記事の1つは、たとえば、クォータニオン暗号化スキームに基づくセキュアな信号伝送です。
クォータニオンを使用してデータを暗号化および復号化するにはどうすればよいですか? とても簡単です!
最初に、クォータニオンを取得します:q = w + x * i + y * j + z * k、およびそれに基づいて回転行列を構成します。たとえば、P(q)と呼びます。
ご注意 下の写真はウィキペディアのもので、マトリックスの名前はQです。
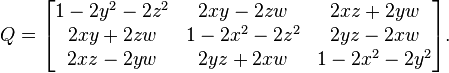
データを暗号化するには、通常の行列乗算を実行する必要があります。たとえば、 B ' = P(q)* B、ここでBは暗号化されるデータ、P(q)は回転行列、B'は暗号化されたデータです。
データを解読するには、おそらく既に推測したように、「暗号化された」行列Bに逆行列(P(q))^-1を掛けて、元のデータを取得する必要があります:B =(P(q))^- 1 * B '
ソースデータマトリックスは、ファイルまたは最初に示すように画像に基づいて入力されます。
以下は、FPGA用のOpenCLコードの変形です。ボードの機能により、暗号化マトリックスを個別の番号で転送する必要があります。
__kernel void quat(__global uchar* arrD, uchar m1x0, uchar m1x1, uchar m1x2, uchar m1x3, uchar m1x4, uchar m1x5, uchar m1x6, uchar m1x7, uchar m1x8) { uchar matrix1[9]; matrix1[0] = m1x0; matrix1[1] = m1x1; matrix1[2] = m1x2; matrix1[3] = m1x3; matrix1[4] = m1x4; matrix1[5] = m1x5; matrix1[6] = m1x6; matrix1[7] = m1x7; matrix1[8] = m1x8; int iGID = 3*get_global_id(0); uchar buf1[3]; uchar buf2[3]; buf2[0] = arrD[iGID]; buf2[1] = arrD[iGID + 1]; buf2[2] = arrD[iGID + 2]; buf1[0] = matrix1[0] * buf2[0] + matrix1[1] * buf2[1] + matrix1[2] * buf2[2]; buf1[1] = matrix1[3] * buf2[0] + matrix1[4] * buf2[1] + matrix1[5] * buf2[2]; buf1[2] = matrix1[6] * buf2[0] + matrix1[7] * buf2[1] + matrix1[8] * buf2[2]; arrD[iGID] = buf1[0]; arrD[iGID+1] = buf1[1]; arrD[iGID+2] = buf1[2]; }
XeonPhiを使用した場合、結果は次のようになりました(Y軸-時間、ms; X軸-データ量、Mb):

グラフからわかるように、XeonPhiはタスクの複雑さによく応答します。つまり、従来のデスクトッププロセッサを使用する場合、1〜25回の反復時間は約25倍異なりますが、ここでは約2倍です。
残念ながら、これらの結果は最高とはほど遠いです。 プログラミング時には、OpenMPテクノロジーとIntelコンパイラーを自動的に最適化する機能が使用されました。 下位レベルでプログラミングする場合、つまり たとえば、内発的なチームの場合、結果は数回改善される可能性があります。
Tesla k20を使用した場合、結果は次のとおりでした(Y軸-時間、ms; X軸-データ量、Mb):
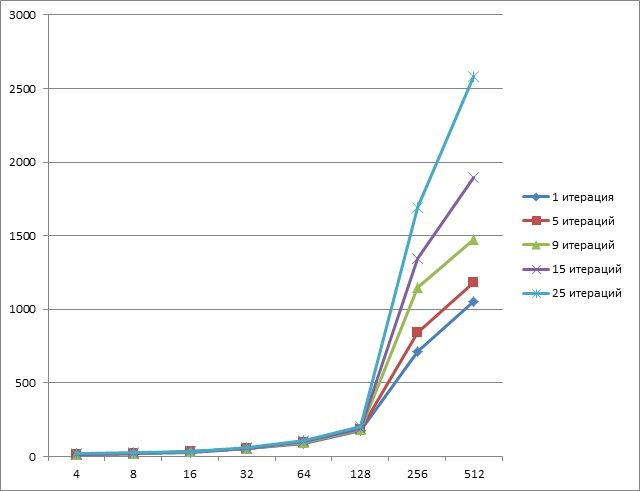
ご覧のとおり、小さなデータサイズのパイプライン処理は完全に表示されます。
FPGA De5-Netを使用した場合、結果は次のとおりでした(Y軸-時間、ms; X軸-データ量、Mb):

一見するとグラフにエラーがあるように見えますが、実際には、そのアーキテクチャにより、FPGAはデータのサイズに関係なく、優れたレベルのパイプラインを示します。
この記事にご関心をお寄せいただきありがとうございます。
UPD。
すべてのコメントを読む前に、読むことをお勧めします
habrahabr.ru/post/226779/#comment_7699309
時間を節約できます、ありがとう。