
データベースの操作:接続パラメーターを使用したJDBC接続のリスト。
ロシアのTOP-5の企業は、1時間あたり平均700万から900万ドルを稼いでいます。 したがって、非人間的な意志の努力によって1時間に短縮された、技術的に単純な2時間の長さは、まさにこの量の価値があります。
BSMは、現在のプログラムの1分がモスクワのアパートと同じ価格であることに突然気づいた人のために特別に設計されたクラスのシステムです。 そして、彼は本当にダウンタイムを持ちたくないのです。
次に、このようなシステムの実装方法を説明します。
純粋なソフトウェアソリューションの例
たとえば、石油会社には、供給を会計処理するための一連のソフトウェアがあり、それは本質的にERPです。 このコンポーネントがなければ、「地下のノーム」がすべてを修復するまで、会社の仕事は向上します。
そのような会社では、各技術リンクに独自の監視システムがあり、何かが発生した場合、最初の興味深い探求は問題を見つけることでした。 彼は各ダウンタイムから最大で半分の時間を費やしました。 問題を明確に見つけることができる監視システムを展開しました。 また、ソフトウェアの問題を早期に発見して修正するのに数時間から数日かかる場合、新しいソリューションは問題の根本原因を特定する時間を大幅に短縮しました。 障害の数ははるかに少なくなり、システムの回復時間も短縮されました。
現在、システムは単にどこで何が間違っているかを示します。 ほとんどの場合、特定の非応答サービスまたは不正確に応答するサービスについて話します。これは、再開するには続行するのに十分です。 同様に、問題の責任者を検索すると、「ボディワーク」全体が消えることを強調したいと思います-プラグがどちら側にあるかという問題を解決する代わりに(そしてこれは多くの部門や請負業者で発生します)、すぐに実行して排除できます。
Ironとの統合
BSMシステムもハードウェアと統合できます。 この場合の作業を説明するために、空港でのBSMのインストール方法について説明します。
空港があります。 その中の重要なオブジェクトは、サーバー、ストレージシステム、および一般に「ローカルデータセンターのITソリューション」のクラスに起因するすべてのものです。 しかし、たとえば、時々GladOSの音声でほぼどこに行くべきか、どの乗客に行くべきかを知らせるナビゲーションシステムもあります。 もちろん、倒れた場合は、生きている人の声でそれを宣言することができますが、もちろんこれを避ける方が良いです-評判、過度のパニック...もう一つの重要なシステムは手荷物管理システムです。 彼女が立ち上がったり、反対方向に荷物を出し始めると、ターミナル全体が乗客へのサービスを停止します。
したがって、次のようにアプローチします。
- システムの重大度に関する完全な調査を実施します。
- ボトルネックを探しています。
- ソリューションを設計しています。 私たちの場合、システムごとに、その動作をチェックするメトリックを作成する必要があります。 たとえば、手荷物の場合、手荷物配送管理システムに接続し、サービスの中断または低下を示すメトリックを追跡できます。 ストレージシステムを使用する場合、プロセスごとに単純に負荷レベルを使用します。
- ソリューション自体を展開します。 これは、「良い」および「悪い」動作のテンプレート、一連のセンサーと情報コレクター(ハードウェアとソフトウェアの両方のエージェント)、アプリケーションサーバー、処理サーバー、アラートシステムを備えたデータベースです。
- 必要に応じて、イベント応答レベルで自動化を構成します。 たとえば、アプリケーションの1つが応答を停止した場合、アプリケーションの自動診断を実行して作業を自動的に復元するか、作業の復元を実行可能なアルゴリズムとして形式化できない場合、必要に応じてアプリケーションの別のインスタンスに自動的に切り替えます。 ラゲッジテープが破損しており、適切な制御システムからこれに関する情報を取得できる場合、SMS通知を介して修理工を自動的に呼び出し、HelpDeskクラスシステムでインシデントを開始し、サポートプロセスに参加している人に電子メールで通知できます。
品質管理
そのため、BSMは障害の場所を特定する時間を短縮できます。 ソフトウェアとハードウェアの両方を追跡できます。 また、BSMシステム内には通常、ユーザーシミュレーターがあります。これらは、たとえば、TCPポートの可用性やWebページのGET応答の存在を確認できるダムの「ロボット」です。 より複雑な実装では、ロボットはアプリケーションインターフェイスを使用して一連のユーザーアクションをエミュレートできます。これらの操作を記録し、インタラクティブな視覚モードでスクリプト言語に変換できます。 アプリケーションレベルまでのトラフィックアセンブリの助けを借りて、主要な操作と関連するユーザー操作のシーケンスを分離し、各実ユーザーの操作の遅延と可用性に関する統計を収集できるモジュールもあります。
今少し余談。 ITシステムを導入するたびに、それが解決するタスクを考える必要があります。 たとえば、ITシステムのないカスタマーサービスが12分続き、手で紙の一部を埋めることのできない自動化システムが導入された場合、サービスには最大10分かかると思いますか? 古い12時間ではなく14分かかる場合は、どこかに問題があります。
したがって、BSMのタスクの1つは、サービス品質を監視することです。 その可用性だけでなく、抑制インターフェースに関する問題の検索、ユーザーによる意思決定の遅延、チェーン内の追加リンクもあります。
開発者がアプリケーションおよび新規リリースの開発とテストを忠実かつ効率的に実行する状況を基本とすると、理由は明らかであるため、顧客によるアプリケーションの仕事の質的指標の独立した監視がすべて必要です-アプリケーションの消費者と顧客以外は高品質のアプリケーション作業を必要としません。 また、品質のレベルは顧客のみが決定できます。
しかし実際には、アプリケーションの次のリリースが商業運用に移行した後のある晴れた朝に、ユーザーがオフィスに来て、すべてが遅くなっていることに気付く可能性が高くなります。 BSMがシステムの品質指標に関する情報を収集しているときの例がありました。 実装後、サードパーティシステムは時計のように機能しました。 しかし、ユーザー数の増加に伴い、一部の操作では、ユーザーがアプリケーションの応答に大幅な遅延を認めたという事実から驚きが始まりました。 BSMはユーザーとして実行され、生きている人々の背後にある基本的なパターンを繰り返します。そして、いくつかの「ボトルネック」を見つけました。
このようなソリューションは、たとえばHP Business Service Management(BSM)で構築できます。これは、最近のいくつかのプロジェクトの例です。 また、ここでHP Executive Scorecard(XS)も統合すると、ビジネスオペレーションを、IT資産と顧客サービスを管理するためのメトリックを使用した監視と関連付けることができます。
コードレビュー
同じHP BSMは、コードのどこに問題があるのかを「すぐに見る」方法を知りません。 それにもかかわらず、ダウンタイムの問題を解決するための非常に多くのタスクがこれに正確にかかっています。 したがって、コードレベルで作業するための製品との便利な統合があります。 この場合、HP Diagnosticsのスクリーンショット:
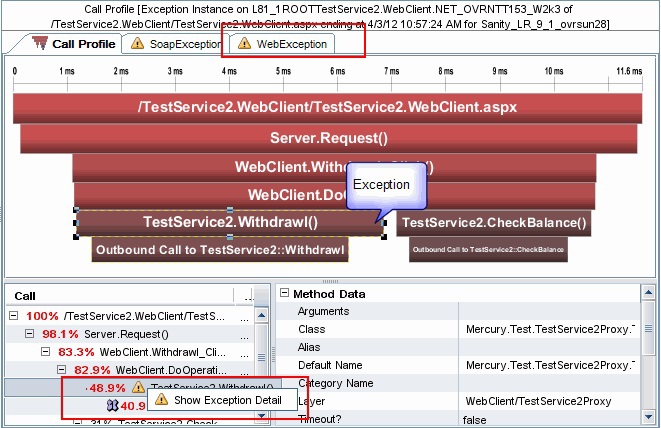
水平バーはアプリケーション内の呼び出しを示し、その長さは各呼び出しの実行時間を示し、それらのシーケンスはツリーの下に表示されます。
同じスクリーンショットは、例外を追跡する機能を示しています。
通話表示を使用すると、アプリケーションの処理速度が低下する理由を把握できます。
データフローと検出されたコンポーネントを分析することにより、Diagnosticsはアプリケーションコンポーネントとクライアント間のトポロジを構築します。
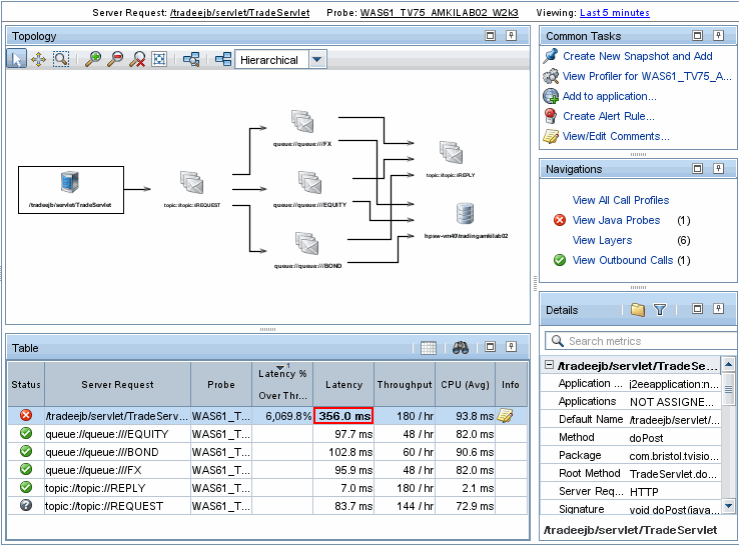
どこで何を知っているのは良いことです
まとめ
説明はかなり単純ですが、BSMは高価で複雑な玩具であり、実際、ITインフラストラクチャで実行されているすべてのデータを収集する付随プロセスのネットワーク全体を展開します。
一般に、BSMは少なくとも1〜2か月で実装され、実際には重要なサービスのダウンタイムを削減できます。 より正確には、100%信頼できるサービスがないことを考えると、避けられないダウンタイムをより短いものに変えてください。