内容
FineReaderのテキスト認識システムは非常に簡単に説明できます。
テキストを含むページがあり、それをテキストブロックに解析してから、ブロックを個別の行に、行を単語に、単語を文字に、認識した文字にさらに解析し、さらにすべてを収集してページのテキストに戻します。

それは非常に単純に見えますが、悪魔は、いつものように、詳細にあります。
次回からドキュメントからテキスト行までのレベルについて説明します。 これは多くの困難がある大きなシステムです。 序論として、おそらく、このような図を線を選択するアルゴリズムに残すことができます。

この記事では、行レベル以下からのテキスト認識の話を始めます。
小さな警告:FineReader認識システムは非常に大きく、長年にわたって継続的に開発されてきました。 このシステム全体をそのニュアンスすべてで説明するには、まずコードを使用する方が良いです。次に、非常に多くのスペースが必要です。次に、これをお読みください。 したがって、以下に書かれているものを、実用的なシステムの背後にある非常に一般化された理論の一種として扱うことをお勧めします。 つまり、テクノロジーの一般的なアイデアと方向はほぼ真実に似ていますが、実際に何が起こるかを詳細に理解するには、この記事を読むのではなく、このシステムの開発に協力してください。
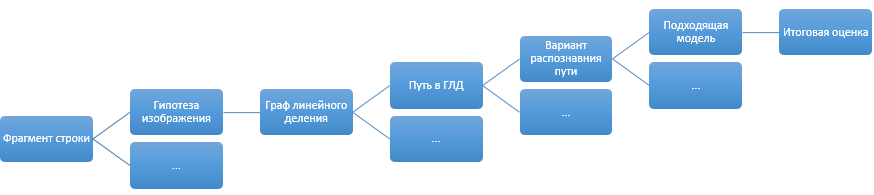
線形分割グラフ
したがって、テキスト行の白黒画像があります。 実際、画像はもちろんグレーまたはカラーであり、2値化後に白黒になります(2値化については別の記事を書く必要もありますが、 今のところこれは部分的に役立ちます)。
それで、テキスト行の白黒画像があるようにします。 それを単語に分割し、単語を認識のためにシンボルに分割する必要があります。 基本的な考え方は、いつものように明白です。文字列の画像で垂直方向の白い隙間を探し、それらを幅でクラスター化します。広い隙間は単語間のスペース、狭い隙間は文字間のスペースです。

アイデアは素晴らしいですが、実際には、スペースの幅は、たとえば、文字が斜めになったり、文字の組み合わせが不成功だったり、スティッキーテキストの場合、非常に複雑なインジケータになることがあります。

この問題には2つの解決策があります。 最初の解決策は、特定の「目に見える」ギャップ幅を考慮することです。 人は、なじみのない言語であっても、テキストを単語に、単語を記号に実際に分割できます。 これは、脳がシンボル間の垂直距離を固定するのではなく、シンボル間のいくつかの目に見える空のスペースを固定するためです。 解決策は優れています。もちろん、私たちはそれを使用しますが、常に機能するとは限りません。 たとえば、スキャン中にテキストが破損し、必要なギャップが減少したり、逆に大幅に増加したりする場合があります。
これは、2番目の解決策である線形分割グラフにつながります。 アイデアは次のとおりです。行を単語に分割し、単語を文字に分割するオプションがいくつかある場合は、考えられるすべての分割ポイントをマークしましょう。 マークされた2つのポイント間の画像の一部は、候補文字(または単語)と見なされます。 線形グラフオプションは、テキストが良好で、分割点の決定に問題がない場合は単純であり、イメージが不良である場合は困難です。


今挑戦。 グラフには多くの頂点があります。最初の頂点から最後の頂点までのパスを見つけ、いくつかの中間頂点(必ずしもすべてではない)を最高品質で通過する必要があります。 私たちはそれを思い出させると考え始めます。 研究所からの最適な制御のコースを思い出しますが、これは動的プログラミングのタスクと疑わしく似ていることを理解しています。
爆発しないようにすべてのオプションを列挙するアルゴリズムが必要だと考えましょう。
グラフの各アークについて、その品質を判断する必要があります。 単語をシンボルに線形分割したグラフを使用すると、国の各アークはシンボルになります。 アークの品質の役割では、文字認識の信頼度を使用します(計算方法-後で説明します)。 また、ラインレベルでGLDを使用する場合、このGLDの各アークは単語認識の変形であり、文字グラフから取得されます。 つまり、線形分割グラフのフルパスの全体的な品質を評価できる必要があります。
グラフ内のフルパスの品質は、オプション全体のすべてのアークのマイナスペナルティの合計として決定されます。 なぜマイナスなのか? これにより、このパスのアークの品質の合計によって、パスバリアントの最大可能品質を迅速に評価できます。つまり、バリアントの全体的な品質を計算する前に、ほとんどのオプションをカットします。
したがって、GLDの場合、標準の動的プログラミングアルゴリズムに到達します。線形分割ポイントを見つけ、アークに沿って最初から最後まで最高品質のパスを構築し、構築されたバージョンの総コストを計算します。 そして、すべての未処理のオプションが現在の最良のオプションより明らかに悪いことがわかるまで、見つかった最良のオプションを絶えず更新して、要素の総合品質を低下させる順序でGLDへのパスを整理します。
画像仮説
個々の単語の認識レベルに進む前に、議論されていない別のトピック-断片画像の仮説があります。
アイデアは次のとおりです。作業するテキストのイメージがあります。 私は本当にすべての画像を同じ方法で処理したいのですが、真実は実際の世界では画像はすべて異なるということです-それらは異なるソースから取得でき、異なる品質であり、異なる方法でスキャンできます。
一方では、考えられる歪みの多様性は非常に大きいはずですが、理解し始めると、考えられる歪みの限られたセットしか見つかりません。 したがって、テキスト仮説システムを使用します。
問題のあるテキストについて考えられる仮説の定義済みセットがあります。 仮説ごとに、以下を決定する必要があります。
- この仮説が現在の画像に当てはまるかどうかをすばやく確認し、認識前に画像の特性に基づいてこれを行うだけです。
- 特定の仮説の問題を修正する方法。
- 画像認識の結果に基づく仮説の選択の正しさの品質基準、さらに、おそらく次の仮説の推奨事項。


上の画像では、元の画像の異なる二値化とコントラストの仮説を見ることができます。
その結果、処理仮説は次のようになります。
- 画像から最適な仮説を生成します。
- 選択した仮説から歪みを修正します。
- 結果の画像を認識します。
- 認識品質を評価します。
- 認識品質が向上した場合は、変更された画像に新しい仮説を適用する必要があるかどうかを評価します。
- 品質が低下した場合は、元の画像に戻り、他の仮説を適用してみてください。
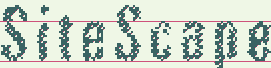
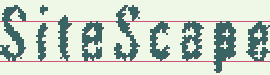
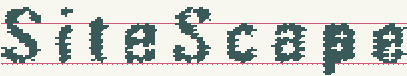
画像は、ホワイトノイズと圧縮テキストの仮説の一貫した適用を示しています。
単語品質評価
単語認識と文字認識の全体的な品質の評価という2つの重要なトピックは未解決のままでした。 文字認識はいくつかのセクションのトピックであるため、最初に認識された単語の品質の評価について説明します。
そのため、ある種の単語認識オプションがあります。 最初に頭に浮かぶのは、辞書でそれをチェックし、辞書で見つからなかった場合にペナルティを与えることです。 アイデアは優れていますが、すべての言語が辞書であるわけではなく、テキスト内のすべての単語が辞書(たとえば、固有名詞)であるとは限りません。
前に、GLD検索が正常に機能するためには、単語ごとの推定値が負である必要があると述べました。 これは積極的に私たちに干渉し始めますので、その単語に対して特定の所定の最大正評価があり、その単語に正のボーナスを与え、ボーナスと最大評価の差として最終的な負のペナルティを決定することを修正しましょう。
では、「Vasyaは2015年7月20日23.55にSU106便に到着しました」というフレーズを認識しましょう。 もちろん、一般的なルールに従ってここで各単語の品質を評価できますが、それはかなり奇妙です。 SU106とVasyaの両方がこの単語の行で非常に理解可能であると言いますが、それらが異なる教育規則を持ち、理論的には検証も異なるべきであることは明らかです
ここからモデルのアイデアが生まれます。 単語モデルは、言語の特定の種類の単語を一般化した一種の記述です。 もちろん、言語には標準的な単語モデルがありますが、数字、略語、日付、略語、固有名詞、URLなどのモデルもあります。
モデルは何を提供し、それらを通常に使用する方法は? 実際、単語検証システムを逆にしています-単語の変形を長期間にわたって調べるのではなく、各モデルにこの単語の変形が適合するかどうか、およびどの程度評価するかを決定させます。

問題のステートメントから、モデルアーキテクチャの要件が形成されます。 モデルは以下を行える必要があります。
- 単語の変形が彼女に適しているかどうかをすばやく言います。 標準テストには、単語の各文字に許可されている文字セットのすべてのチェックが含まれます。 たとえば、辞書の単語では、句読点は先頭または末尾のみである必要があり、単語の途中では、句読点セットは非常に制限されており、句読点の組み合わせは非常に制限されています(超強力?!)。シンボリックサフィックスの言語(10番目、10番目)。
- 内部ロジックにより、認識された単語の品質を評価できます。 たとえば、辞書の単語は、単なる文字セットよりも明確に上位にランク付けする必要があります。
モデルの品質を評価する場合、最終的に私たちのタスクはモデルを相互に比較することであることを忘れないでください。そのため、推定値は一貫している必要があります。 これを達成するための多かれ少なかれ通常の方法は、このモデルで単語を構築する確率を評価することに関して、モデルの評価に関連することです。 共通言語には多くの辞書語があり、誤った認識の辞書語を取得するのは簡単だとしましょう。 しかし、すべてのルールに適した通常の電話番号を収集するには、はるかに困難です。
その結果、文字列の一部を認識すると、次のような結果が得られます。
認識オプションの評価における別のポイントは、モデルの概念にも認識の評価にも適合しない追加の経験的ペナルティです。 「LLC Horns and Hooves」と「000 Horns and Hooves」は、2つの同様に通常のオプションのように見えます(特にフォント0(ゼロ)とO(文字O)の比率がわずかに異なる場合)。 しかし、どの認識オプションが正しいかは明らかです。 このような世界の小さな特定の知識のために、別のルールシステムが作成され、モデルを評価した後に気に入らなかった細かいオプションを追加することができます。
この投稿の次の部分で、認識自体について説明します。 お見逃しなく会社のブログを購読してください:)