今日は、簡単なPythonデータ分析システムを構築する方法について説明します。 フレームワークキューブとcubesviewerパッケージは、これに役立ちます。
キューブは、Pythonを使用して多次元データを操作するためのフレームワークです。 さらに、レポート作成アプリケーションの開発と一般的なデータ表示を簡素化するOLAP HTTPサーバーが含まれています。
Cubesviewerは、上記のサーバーを操作するためのWebベースのインターフェイスです。
キューブをインストールして構成する
最初に、パッケージが機能するために必要なライブラリをインストールする必要があります。
pip install pytz python-dateutil jsonschema pip install sqlalchemy flask
次に、 キューブパッケージ自体をインストールします。
pip install cubes
実践が示しているように、現在のリポジトリのバージョン(1.0alpha2)を使用することをお勧めします 。
Windowsの詳細設定
Windowsで作業する場合は、 {PYTHON_DIR} \ Lib \ site-packages \ dateutil \ tz.pyファイルの40行を置き換える必要があります。
return myfunc(*args, **kwargs).encode()
に
return myfunc(*args, **kwargs)
次に、使用するプラットフォームに関係なく、jsonパーサーが正しく機能するように次の修正を追加する必要があります。 90行目から{PYTHON_DIR} \ Lib \ site-packages \ cubes-1.0alpha-py2.7.egg \ cubes \ metadata.pyに入力する必要があります。
elif len(parts.scheme) == 1 and os.path.isdir(source): # TODO: same hack as in _json_from_url return read_model_metadata_bundle(source)
キューブのセットアップとその展開プロセスの説明
たとえば、 cubesに付属しているOLAPキューブを考えます 。 examples / hello_worldフォルダにあります (リポジトリから取得できます)。
私たちにとって最も興味深いのは2つのファイルです。
- slicer.ini-キューブのhttpサーバー設定ファイル
- model.json-キューブモデルの説明を含むファイル
それらについて詳しく見ていきましょう。 次のセクションを含む場合があるslicer.iniファイルから始めましょう。
-
[workspace]
-職場の構成 -
[server]
-サーバーのパラメーター(アドレス、ポートなど) -
[models]
-ダウンロードするモデルのリスト -
[datastore] [store]
-データストレージパラメーター -
[translations]
-モデルのローカライズ設定。
したがって、テストファイルから、サーバーがローカルマシンに配置され、5000ポートで動作することを分析します。 data.sqliteと呼ばれるローカルSQLiteデータベースがストレージとして使用されます。
サーバー構成の詳細については、ドキュメントをご覧ください 。
また、ファイルから、キューブのモデルの説明がmodel.jsonファイルにあることがわかります。このファイルの構造の説明は、これから取り上げます。
モデル記述ファイルは、次の論理セクションを含むjsonファイルです。
-
name
モデル名 -
label
-ラベル -
description
-モデルの説明 -
locale
モデルのロケール(ローカライズが指定されている場合) -
cubes
-キューブメタデータリスト -
dimensions
-dimensions
メタデータリスト -
public_dimensions
使用可能なディメンションのリスト。 デフォルトでは、すべての測定が利用可能です。
キューブとディメンションのセクションは、私たちにとって興味深いものです。 その他はすべてオプションです。
ディメンションリストアイテムには、次のメタデータが含まれます。
| キー | 説明 |
|---|---|
| お名前 | 次元識別子 |
| ラベル | ユーザーに表示されるディメンション名 |
| 説明 | ユーザーの測定の説明 |
| レベル | 測定レベルのリスト |
| 階層 | 階層リスト |
| default_hierarchy_name | 階層ID |
キューブリストアイテムには、次のメタデータが含まれています。
| キー | 説明 |
|---|---|
| お名前 | 次元識別子 |
| ラベル | ユーザーに表示されるディメンション名 |
| 説明 | ユーザーの測定の説明 |
| 寸法 | 上記の測定名のリスト |
| 対策 | 対策のリスト |
| 集合体 | 集約関数のリスト |
| マッピング | 論理的および物理的属性のマークアップ |
上記に基づいて、( item、year )のモデルに2つのディメンションがあることを理解できます。 「 アイテム 」測定には3つの測定レベルがあります。
- カテゴリ 。 表示名「Category」、フィールド「category」、「category_label」
- サブカテゴリ 。 表示名「サブカテゴリ」、フィールド「サブカテゴリ」、「サブカテゴリラベル」
- line_item 。 表示名「明細」、フィールド「line_item」
キューブのメジャーとして、 「amount」フィールドが機能します。このフィールドでは、合計と行数のカウントの機能が実行されます。
ドキュメントでキューブモデルのマーク付けの詳細をご覧ください。
設定を理解したら、テストベースを作成する必要があります。 これを行うには、 prepare_data.pyスクリプトを実行する必要があります。
python prepare_data.py
あとは、スライサーと呼ばれるキューブでテストサーバーを起動するだけです。
slicer serve slicer.ini
その後、キューブのパフォーマンスを確認できます。 これを行うには、ブラウザバーに次のように入力できます。
localhost :5000 / cube / irbd_balance / aggregate?drilldown = year
応答として、データの集計結果を含むjsonオブジェクトを取得します。 サーバーの応答形式の詳細については、 こちらをご覧ください 。
cubesviewerをインストールする
キューブを構成したら、 subviewviewerのインストールに進むことができます。 これを行うには、 リポジトリをディスクにコピーします 。
git clone https://github.com/nonsleepr/cubesviewer.git
そして、 / srcフォルダーの内容を目的の場所に移動するだけです。
cubesviewerはDjangoアプリケーションであるため、 Django(バージョン1.4以下)とリクエストおよびdjango-pistonパッケージが必要であることに注意してください。 なぜなら このバージョンのDjangoはすでに古くなっているため、上記のリンクを使用して、バージョンDjango 1.6のサブビューアーを入手できます。
それをインストールすると、行を追加する必要があるという点で元のものとわずかに異なります
allow_cors_origin: localhost:8000
その後、ファイル{CUBESVIEWER_DIR} /web/cvapp/settings.pyでアプリケーションを構成する必要があります 。 データベース設定、OLAPサーバーアドレス(
CUBESVIEWER_CUBES_URL
変数)および
CUBESVIEWER_CUBES_URL
アドレス(
CUBESVIEWER_BACKEND_URL
)を指定することにより
dajno-pistonに小さな修正を加えることは残っています
これで、アプリケーションをデータベースと同期できます。 これを行うには、 {CUBESVIEWER_DIR} / web / cvappから実行する必要があります。
python manage.py syncdb
ローカルのDjangoサーバーを起動します
python manage.py runserver
これで、ブラウザを介して
CUBESVIEWER_BACKEND_URL
指定されたアドレスに移動することができます。 そして、完成した結果をお楽しみください。
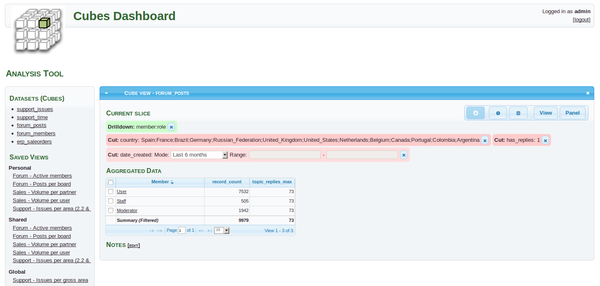
おわりに
作業を説明するために、最も単純な例を取り上げました。 実稼働プロジェクトの場合、 キューブはapacheやuswgiなどにデプロイできることに注意してください 。 この記事を使用してcubesviewerを接続するのは難しくありません。
トピックがコミュニティにとって興味深いものである場合、今後の記事の1つで公開します。