
この投稿では、Lomonosovスーパーコンピューターでの計算の経験についてお話したいと思います。 率直に言って、SCを使用する必要はありませんが、学問的な関心は何よりも重要です。 の詳細 ロモノソフの設定はここにあります 。
ノード/プロセス間のデータレート
最初に、クラスター帯域幅の簡単なテストを実行し、スレッド間でデータ転送速度がどの程度異なるかを比較することにしました。a)両方のスレッドが同じクラスターノードで実行されている場合。 b)別の 以下の値は、mpitests-osu_bwテストを使用して評価されました。
異なるノードでのピーク速度:
3.02 GB /秒
1つのノードで:
10.3 GB /秒
タスクについて少し
かなり単純な領域で拡散方程式を解く必要があります。
} {\ partial t} = D \ nabla ^ 2u({\ bf r}、t)+ f({\ bf r}、t)")
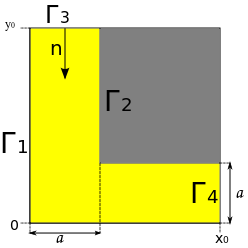
パラメーターに線形方程式があります。 フローなしで解決します。 境界1、2、4では導関数は壁0に垂直であり、境界3では濃度は与えられた関数g(t)によって決定されます。 したがって、混合境界値の問題が発生します。 有限差分法によって解決します(非常に非効率的ですが、簡単です)。
並列化について
この問題を解決するために、私はopenMPI / intelMPIを使用しました(実際のコンパイラーの比較については、別の投稿をする必要があります)。 ウィキペディアがあり、明示的なスキームを使用したとだけ言うので、数値スキームについては掘り下げません。 エリアのブロック分布を使用して、各ストリームに複数のエリアが与えられ、前のエリアから送信されたデータがゼロの場合、そのエリアは考慮されません。 ブロックの極端な列/行は、隣接するストリームからデータを受信するように設計されています。

計算で使用されるグリッドパラメーター
グリッド内のノードの数:3 * 10 ^ 6
グリッドステップ:0.0007。
物理的拡散時間:1秒
タイムステップ:6.5 * 10 ^ -7
D:0.8
3 0.01モルの境界での初期濃度。
アムダルの法則について少し
ジムアムダールは、コンピューターの数の増加に伴うコンピューターシステムのパフォーマンスの制限を示す法律を策定しました。 何らかの計算上の問題を解決する必要があるとします。 αを、順次実行されるアルゴリズムの一部とします。 次に、それぞれ1-αが並列に実行され、pノードで並列化できるため、コンピューティングシステムで得られる加速度は次のように得られます。

結果の最も興味深い部分と並列化の結果に移りましょう。
さまざまな数のスレッドでの実行時間
| パーセント数。 | 1 | 2 | 8 | 16 | 32 | 64 | 128 |
| 時間分 | 840 | 480 | 216 | 112 | 61 | 46 | 41 |
アムダールの法則により計算時間を概算します。
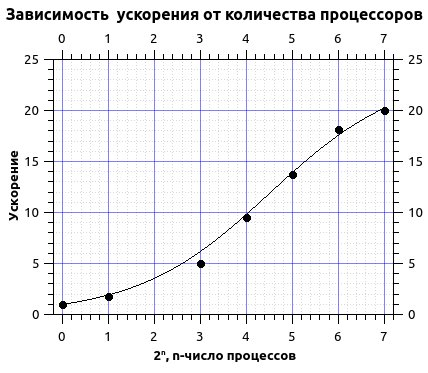
近似から、私は4.2%のオーダーのシーケンシャルコードと20倍のオーダーの最大加速度のシェアを得ました。 グラフからわかるように、曲線はプラトーになります。これから、最大加速が達成され、プロセッサ数をさらに引き込むことは実用的ではないと結論付けることができます。 さらに、この場合、200を超えるプロセス数の増加に伴い、加速が減少しました。これは、プロセス数が増加すると、それらの不合理な使用が開始されるという事実によるものです。 グリッド内の行数はプロセス数と同等になり、交換により多くの時間が費やされ、この時間が計算中に大きく貢献します。
いくつかのメモ
SCはsbatchタスク管理システムを使用し、いくつかのキューtest、regular4、regular6、gputest、gpuがあります。 このタスクでは、regular4キューを使用しました。待機時間は3日に達する可能性があります(実際には、待機時間は17〜20時間です)。