memmove()
、多くは
memcpy()
や
memmove()
などの関数に出くわしました。実際、これらの関数は同じことを行いますが、2番目の関数はメモリ領域が重複する場合に適切に対応します(追加のオーバーヘッドが発生します)
C ++の世界では、これらの関数の使用を禁止する人はいません(多くの場合、これらの関数はさまざまな最適化メカニズムを使用し、C ++の世界の対応する関数よりも高速になる可能性があります)が、イテレーターを介して動作するネイティブツール
std::copy
。 このツールは、PODタイプだけでなく、反復子をサポートするすべてのエンティティに適用できます。 標準の実装の詳細については何も言われていませんが、ライブラリの開発者は、可能であれば最適化された
memcpy()
/
memmove()
を使用しないほど愚かではないと想定できます。
しかし、気をつけて、重複する領域(重複するメモリブロック)が何であるかを見たいですか? 結局のところ、タスクは実際、それほど珍しいことではありません。 たとえば、あるストリームからMPEG-TSパケット(サイズが188バイト、各パケットが0x47 /同期バイト/で始まる)を読み取りたい場合、最初の(そしておそらく次のように:M2TSを処理する可能性があります)ブロックサイズが192バイトで、ほとんどの場合、追加の4バイト(/ timestamp /)を無視できるコンテナは、パケットの途中で読み込めます。 そのような場合、これは通常次のように行われます:188バイトのブロックを減算し、ゼロ位置にある場合は同期バイトを探します-そうでない場合はすべてが正常であり、それから最後までのデータをブロックの先頭に移動する必要があり、欠落している部分を読み込む必要があります、その後パッケージは控除されたとみなされ、処理のためにパッケージを提供できます。
データをブロックの先頭にコピーするプロセスは、次の図で明確に示されています。

つまり オーバーラップがあることがわかります。
memmove()
類似物を使用することは論理的ですが、標準ライブラリには
std::move
のみがあり、これは絶対に間違っています(ここでは笑顔が必要です)。 しかし、同時に、 std :: copyの説明を読むと、次の行が表示されます。
結果が範囲内の要素を指すような方法で範囲は重複してはならない[最初、最後)。
つまり 実際、コピーする領域(結果)の先頭が[最初、最後)の領域の外側にある場合、すべてが問題ないはずです。 そして、本当にそうです。
しかし、この重複するコピースキームを見てみましょう。
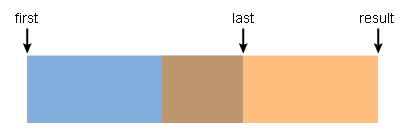
結果がここにあるという事実に注意を払うまで。 画像の意味は、メモリブロックを先頭から前方にいくつかシフトする必要があることです。このシフトがシフトされたブロックのサイズよりも小さい場合、宛先アドレスは[first、last)内にあるため、適用可能性の条件は
std::copy
は尊重されません。 そして、あなたがそれを適用する場合、私たちは単に重複領域のデータを上書きします。
しかし、ここで彼の兄弟が救助に来て、この問題を解決します:
std::copy_backward
この関数の完全な違いは、最後からコピーを実行することです。 つまり 2番目の図に示されているケースの場合、lastから(さらに大まかに)要素を取得して結果に移動し、次にlast-1からresult-1、次にlast-2からresult-2などになります。
このようなコピー方式では、重複領域への書き込みを開始すると、その領域のデータはすでに処理されていることがわかります。 つまり すべてが私たちにとって良いことです。 面白いのは、
std::copy_backward
word for wordの重複領域の適用条件が
std::copy
この条件を繰り返すことです。
したがって、要約すると、簡単なルール:
- 結果が<first(「ブロックを先頭/または左/にシフト」)の場合、結果が宛先ブロックの先頭を示すため、
std::copy
使用します。 - result> first(「ブロックを末尾/または右/にシフト」)の場合、
std::copy_backward
使用して、結果として宛先ブロックの末尾を指定します。
このテキストは、英語の記事www.trilithium.com/johan/2006/02/copy-confusionを創造的に再考したもので、写真は同じ場所から撮影されたもので、私の経験からの例です。
参照: