
以前のメモでは、ロックフリーデータ構造が構築される基礎、およびロックフリーデータ構造の要素の寿命を制御するための基本的なアルゴリズムについて説明しました。 これは、ロックフリーコンテナー自体の説明の前置きでした。 しかし、その後、私は問題に遭遇しました:さらなるストーリーを構築する方法は? 知っているアルゴリズムを説明してください。 これはかなり退屈です:多くの[擬似]コード、豊富な詳細、もちろん重要ですが、非常に具体的です。 最後に、これは、私が参照する公開された作品、およびより詳細で厳密なプレゼンテーションにあります。 競争力のあるコンテナの設計へのアプローチを開発する方法を示すために、興味深いことについて興味深いことを伝えたかったのです。
さて、プレゼンテーション方法は次のようにすべきだと思いました。何らかの種類のコンテナ(ターン、マップ、ハッシュマップ)を使用し、この種類のコンテナの現在知られている元のアルゴリズムを確認します。 どこから始めますか? そして、最も単純なデータ構造であるスタックを思い出しました。
スタックについて何と言えますか? これは、ささいなデータ構造であり、言うことはほとんどありません。
実際、競合スタックの実装に関する作業はそれほど多くありません。 しかし、一方で、スタック自体よりもアプローチに専念しているもの。 私が興味を持っているのはアプローチです。
ロックフリースタック
スタックは、おそらくロックフリーアルゴリズムが作成された最初のデータ構造です。 Treiberが1986年の記事で最初に公開したと考えられていますが、このアルゴリズムがIBM / 360システムのドキュメントで最初に説明されたという証拠があります。
歴史的な隠れ家
一般に、Treiberの記事は一種の旧約聖書であり、おそらくロックフリーデータ構造に関する最初の記事です。 いずれにせよ、私は以前のものを知りません。 ロックフリーのアプローチの創始者へのオマージュとして、それは明らかに現代の作品の参考文献で非常に頻繁に言及されています。
アルゴリズムは非常に単純なので、 libcdsから適応コードを提供します (興味のある人は、
cds::intrusive::TreiberStack
intrusive stack):
// m_Top – bool push( value_type& val ) { back_off bkoff; value_type * t = m_Top.load(std::memory_order_relaxed); while ( true ) { val.m_pNext.store( t, std::memory_order_relaxed ); if (m_Top.compare_exchange_weak(t, &val, std::memory_order_release, std::memory_order_relaxed)) return true; bkoff(); } } value_type * pop() { back_off bkoff; typename gc::Guard guard; // Hazard pointer guard while ( true ) { value_type * t = guard.protect( m_Top ); if ( t == nullptr ) return nullptr ; // stack is empty value_type * pNext = t->m_pNext.load(std::memory_order_relaxed); if ( m_Top.compare_exchange_weak( t, pNext, std::memory_order_acquire, std::memory_order_relaxed )) return t; bkoff(); } }
このアルゴリズムは、ボーン(たとえば、 ここ )によって繰り返し逆アセンブルされるため、繰り返しません。 アルゴリズムの簡単な説明は、目的の結果が得られるまで、
m_Top
アトミックプリミティブCASの助けを借りてハンマーするという事実に還元されます。 シンプルでかなり原始的。
2つの興味深い詳細に注意してください。
- 安全なメモリ再生(SMR)は
pop
メソッドでのみ必要ですm_Top
フィールドを読み取るのはそこだけだからです。m_Top
フィールドはpush
読み取られないpush
(m_Top
ポインターへのアクセスはありません)、ポインターでハザードを保護する必要はありません。 通常、ロックフリーコンテナクラスのすべてのメソッドでSMRが必要になるため、これは興味深いことです。 - 神秘的な
bkoff
オブジェクトと、CASが失敗した場合のbkoff()
への呼び出し
この非常に
bkoff
については、さらに詳しく説明します。
バックオフ戦略

CASが失敗するのはなぜですか? 明らかに、
m_Top
の現在の値を
m_Top
てからCASを適用しようとする間に、他のスレッドが
m_Top
の値を変更することが
m_Top
です。 つまり、競争の典型的な例があります。 競合が激しい場合、N個のスレッドが
push
/
pop
実行すると、そのうちの1つだけが勝ち、残りのN-1はCPU時間を浪費し、CASで互いに干渉します( MESIキャッシュプロトコルを思い出してください )。
そのような状況が検出されたときにプロセッサをアンロードするにはどうすればよいですか? メインタスクから戻って何か役に立つことをするか、単に待つことができます。 それがバックオフ戦略の目的です。
もちろん、特定のタスクについてはわからないので、「役に立つことはできません」という一般的なケースでは、待つことしかできません。 どうやって待つの?
sleep()
オプションに注意してください-このような小さな待機タイムアウトを提供できるオペレーティングシステムはほとんどありません。また、コンテキストの切り替えのオーバーヘッドが大きすぎます-CASランタイムよりも大きいです。
学術環境では、 指数関数的バックオフ戦略が一般的です。 アイデアは非常に簡単です。
class exp_backoff { int const nInitial; int const nStep; int const nThreshold; int nCurrent; public: exp_backoff( int init=10, int step=2, int threshold=8000 ) : nInitial(init), nStep(step), nThreshold(threshold), nCurrent(init) {} void operator()() { for ( int k = 0; k < nCurrent; ++k ) nop(); nCurrent *= nStep; if ( nCurrent > nThreshold ) nCurrent = nThreshold; } void reset() { nCurrent = nInitial; } };
つまり、ループの長さを増やすたびに、ループ内で
nop()
を実行します。
nop()
代わりに、もっと便利なものを呼び出すことができます。たとえば、「内部問題を完了する時間がある」ことをプロセッサに伝える
指数バックオフの問題は単純です-適切なパラメーター
nInitial
、
nStep
、
nThreshold
を見つけるのは困難
nThreshold
。 これらの定数は、アーキテクチャとタスクに依存しています。 上記のコードでは、それらのデフォルト値は天井から取得されます。
したがって、実際には、デスクトッププロセッサとエントリレベルサーバーに適した選択肢は、
yield()
バックオフ-別のスレッドへの切り替えです。 このようにして、他のより成功したフローに時間を与え、彼らが必要とすることを行い、私たちを煩わせないことを望みます(そしてそれらを止めます)。
とにかくバックオフ戦略を適用する方法はありますか? 実験では、一つのことを示しています。正しいボトルネックに正しいバックオフ戦略を適用すると、ロックフリーコンテナーのパフォーマンスが数倍向上する可能性があります。
考慮されたバックオフ戦略は、失敗したCASの問題を解決するのに役立ちますが、主なタスク(スタックの操作)の実装にはまったく寄与しません。 バックオフ戦略が積極的に運用を支援するように、
push
/
pop
とバックオフを何らかの形で組み合わせることは可能ですか?
消去バックオフ
一方、
push
/
pop
で失敗したCASの問題を考慮してください。 CASが失敗するのはなぜですか? 別のスレッドが
m_Top
変更したため。 そして、この他のスレッドは何をしますか?
push()
または
pop()
実行します。 スタックの
push
操作と
pop
操作は相補的である
push
注意してください:1つのスレッドが
push()
し、同時に他のスレッドが
pop()
する場合、原則として
m_Top
スタックの最上部にアクセスする意味はありません:プッシュストリームは単にそのデータをポップストリームに転送しますが、スタックの主要なプロパティであるLIFOは違反されません。 スタックの最上部をバイパスして、これらの両方のフローをまとめる方法を理解することは残っています。
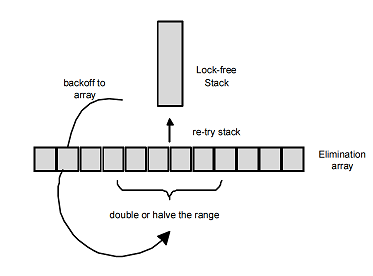
2004年に、Hendler、Shavit、およびYerushalmiは、Treiberアルゴリズムの修正を提案しました。このアルゴリズムでは、スタックの最上部を使用せずにプッシュストリームとポップストリーム間でデータを転送するタスクが、 削除バックオフ戦略(エリミネーションバック戦略)と呼ばれる特別なバックオフ戦略を使用して解決されます-off、私もそれを吸収バックオフ戦略として翻訳します)。
サイズNの消去配列があります(Nは小さな数です)。 この配列は、スタッククラスのメンバーです。 CASが失敗してバックオフすると、スレッドはその操作(
push
または
pop
)のハンドルを作成し、この配列内の任意のセルをランダムに選択します。 セルが空の場合、その記述子へのポインターを書き込み、通常のバックオフ(指数など)を実行します。 この場合、フローはパッシブと呼ばれます。
選択したセルに他の(パッシブ)ストリームの操作記述子Pへのポインターが既に含まれている場合、ストリーム(アクティブと呼びましょう)は、その操作の種類を確認します。 操作が補完的な場合
push
と
pop
、それらは相互に吸収されます:
- アクティブスレッドが
push
を実行すると、引数をP記述子に書き込み、パッシブスレッドのpop
操作に渡します。 - アクティブなスレッドが
pop
場合、補完的なpush
操作の引数をハンドルPから読み取ります。
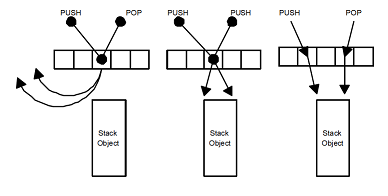
次に、アクティブスレッドは、削除配列セルのエントリを処理済みとしてマークし、パッシブストリームがバックオフを終了したときに、誰かが魔法のように作業を実行したことを確認します。 その結果、アクティブスレッドとパッシブスレッドは、スタックの最上部にアクセスせずに操作を実行します 。
選択した消去配列セルの操作が同じ場合(プッシュプッシュまたはポップポップの状況)、運はありません。 この場合、アクティブなスレッドは通常のバックオフを実行してから、通常どおり
push
/
pop
スタックトップのCAS)を実行しようとします。
バックオフが終了したパッシブストリームは、消去配列内の記述子をチェックします。 記述子に操作が完了したというメモがある場合、つまり、補完的な操作を持つ別のストリームが見つかった場合、パッシブストリームはその
push
/
pop
正常に完了します。
上記のアクションはすべて、ロックなしでロックなしで実行されるため、実際のアルゴリズムは説明されているアルゴリズムよりも複雑ですが、意味は変わりません。
記述子には、操作コード(
push
または
pop
)および操作の引数が含まれます:
push
の場合、追加する要素へのポインター
nullptr
の場合、ポインターフィールドは空のままです(
nullptr
)。除去が成功した場合、吸収
push
操作の要素へのポインターが書き込まれます。
除去バックオフにより、高負荷でスタックを大幅にアンロードすることができ、低で、スタックのCASトップがほぼ常に成功する場合、このスキームはオーバーヘッドをまったく導入しません。 アルゴリズムには微調整が必要です。これは、タスクと実際の負荷に応じて、最適な消去配列サイズを選択することにあります。 また、操作中に除去配列のサイズが小さな制限内で変化し、負荷に適応する場合、アルゴリズムの適応バージョンを提供できます。
不均衡の場合、
push
操作と
pop
操作がバッチで行われる場合-
pop
なしで多くの
push
、
push
なしで多くの
pop
-アルゴリズムは具体的なゲインを与えませんが、従来のTreiberアルゴリズムと比較してパフォーマンスの低下はほとんどないはずです。
フラット結合
ここまで、ロックフリースタックについて説明しました。 次に、通常のロックベースのスタックを考えます。
template <class T> class LockStack { std::stack<T *> m_Stack; std::mutex m_Mutex; public: void push( T& v ) { m_Mutex.lock(); m_Stack.push( &v ); m_Mutex.unlock(); } T * pop() { m_Mutex.lock(); T * pv = m_Stack.top(); m_Stack.pop() m_Mutex.unlock(); return pv; } };
明らかに、競合他社では、そのパフォーマンスは非常に低くなります。スタックへのすべての呼び出しはミューテックスでシリアル化され、すべてが厳密に順番に実行されます。 パフォーマンスを改善する方法はありますか?
N個のスレッドが同時にスタックにアクセスする場合、そのうちの1つだけがミューテックスをキャプチャし、残りはミューテックスが解放されるのを待ちます。 しかし、mutexで受動的に待機する代わりに、待機中のスレッドは、バックオフの排除のように、操作をアナウンスし、勝者のスレッド(mutexの所有者)は、作業に加えて兄弟からタスクを実行できます。 このアイデアは、2010年に記述され、今日まで発展しているフラット結合アプローチの基礎を形成しました。
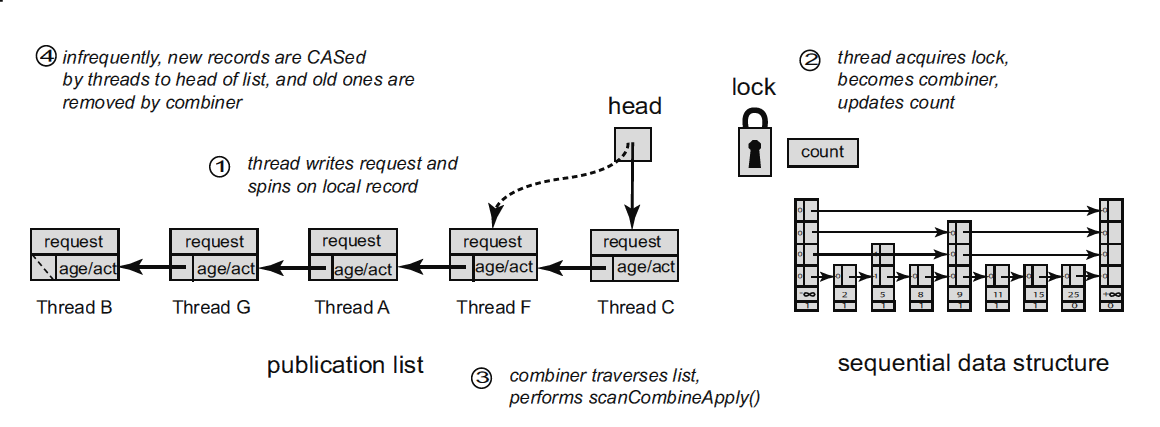
フラット結合アプローチのアイデアは、次のように説明できます。 私たちの場合、各データ構造、スタックでは、ミューテックスとパブリケーションリストは、スタックで動作するスレッドの数に比例したサイズに関連付けられています。 スタックへの最初の呼び出しの各スレッドは、スレッドローカルストレージ(TLS)にあるアナウンスメントのリストにそのレコードを追加します。 操作が実行されると、スレッドはそのレコード(要求(
push
または
pop
)とその引数)で要求を発行し、mutexをキャプチャしようとします。 ミューテックスがキャプチャされると、ストリームはコンバイナになります(コンバイナ、 コンバインラムと混同しないでください):アナウンスメントのリストをスキャンし、そこからすべてのリクエストを収集し、それらを実行します(スタックの場合、上記で説明した削除を適用できます)、結果をアナウンスリストの要素に書き込み、最終的にミューテックスを解放します。 ミューテックスをキャプチャする試みが失敗した場合、コンバイナがリクエストを実行し、アナウンスメントレコードに結果を配置するときに、スレッドはアナウンスメントで待機(スピン)します。
アナウンスメントのリストは、それを管理するオーバーヘッドを削減するように設計されています。 重要な点は、アナウンスのリストがめったに変更されないことです。そうしないと、ロックフリーパブリケーションリストがスタックの側面にねじ込まれ、スタック自体が何らかの形で高速化される可能性が低くなります。 操作の要求は、アナウンスメントリストの既存のエントリに入力されます。これは、ストリームのプロパティであり、TLSにあることを思い出します。 一部のリストエントリのステータスは「空」である可能性があります。これは、対応するスレッドが現在データ構造(スタック)でアクションを実行していないことを意味します。 随時、コンバイナはアナウンスのリストを間引いて、長時間アクティブでないレコードを除外します(したがって、リストエントリには何らかの種類のタイムスタンプが必要です)。これにより、リストの表示にかかる時間が短縮されます。
一般に、フラット結合は複雑なロックフリーデータ構造に正常に適用される非常に一般的なアプローチであり、たとえば、フラット結合スタックの実装に消去バックオフを追加するなど、さまざまなアルゴリズムを組み合わせることができます。 パブリックライブラリのC ++でのフラット結合の実装も非常に興味深いタスクです。事実、研究論文では、アナウンスメントのリストは通常、各コンテナオブジェクトの属性であり、各コンテナは、 TLSに独自のエントリがあります。 すべてのフラットな結合オブジェクトに対して単一の公開リストを使用したより一般的な実装が必要ですが、速度を落とさないことが重要です。
歴史スパイラル
実装前に操作を発表するという考え方がロックフリーアルゴリズムの研究の始まりに戻っているのは興味深いことです。1990年代初頭、従来のロックベースのデータ構造をロックフリーに変換する一般的な方法を構築しようとしました。 理論の観点からは、これらの試みは成功していますが、実際には低速でロックのない重いアルゴリズムが得られます。 これらの一般的なアプローチのアイディアは、実行前に操作をアナウンスすることであり、競合するスレッドがそれを確認して完了を支援することでした。 実際には、そのような「ヘルプ」はむしろ障害でした。スレッドは同じ操作を同時に実行し、お互いにプッシュしたり干渉したりしていました。
積極的な支援から受動的に作業を別のより成功したストリームに委任するまで、強調の少しの再配置が必要でした。
積極的な支援から受動的に作業を別のより成功したストリームに委任するまで、強調の少しの再配置が必要でした。
おわりに
スタックのような単純なデータ構造は、書くべきものがないように思えますが、競争力のあるデータ構造の開発に非常に多くの興味深いアプローチを示すことができたことは驚くべきことです!
バックオフ戦略は 、ロックフリーアルゴリズムの構築のあらゆる場所に適用できます。原則として、各操作は「成功しません」という原則に従って無限ループに囲まれ、ループ本体の最後、つまり反復が失敗したときは不要ではありませんバックオフを設定します。これにより、高負荷時に重要なコンテナデータへの圧力を軽減できます。
除去のバックオフは、スタックおよびそれほどではないがキューに適用される、あまり一般的ではないアプローチです。
近年開発されたフラットコンバインは、競合のないコンテナの構築における特別な傾向です。ロックフリーとファイングレインロックベースの両方です。
将来これらのテクニックに出会えることを願っています。
ロックフリーのデータ構造