最初に、エントロピープレフィックスコーディングの背後にある基本的な考え方を見てみましょう。 たとえば、「KUKUSHAKAKUKUSHONUKUPILAKAPUSHON」など、ロシア語のアルファベットの文字で構成されるメッセージがあるとします。 このメッセージには、10個の異なる文字{K、Y、W、A、O、N、P、I、L、Y}しかありません。つまり、各文字は4ビットを使用してエンコードできます。
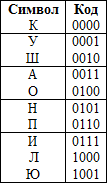
つまり、このような単純なブロックコーディングを使用したメッセージ全体は、116ビットを占有します。
ただし、他のコードをシンボルに関連付けることができます。例:
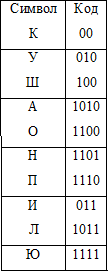
Tabのコードを使用する場合。 2、メッセージの長さはすでに90ビットであり、ゲインは22%以上です。 注意深い読者は、タブのコードに気付くでしょう。 1は一定の長さを持ち、簡単にデコードできることを意味します。 タブで。 2つのコードには可変長がありますが、別の重要なプロパティであるプレフィックスがあります。 prefixプロパティは、他のコードの先頭にコードがないことを意味します。 任意のプレフィックスコードについて、対応するツリーを構築できます。これを使用して、メッセージを一意にデコードできます。
エンコードされたメッセージから読み取られたゼロビットが左へのツリーに沿った動きに対応し、シングルビットが右への動きに対応することに同意する場合、デコードプロセスは明白になります。
問題は、最小限の冗長性でコードツリーを構築できるアルゴリズムがあるかどうかということです。 ハフマンは、そのようなアルゴリズムが存在することを証明しただけでなく、提案しました。 それ以来、最小限の冗長性でコードツリーを構築するためのアルゴリズムは彼にちなんで命名されました。 ハフマンアルゴリズムの基本的な手順を以下に示します。
- アルファベットのすべての文字はフリーノードとして表されますが、ノードの重みはメッセージ内のシンボルの頻度に比例します。
- 空きノードのセットから、最小の重みを持つ2つのノードが選択され、選択したノードの重みの合計に等しい重みを持つ新しい(親)ノードが作成されます。
- 選択したノードは空きリストから削除され、それらに基づいて作成された親ノードがこのリストに追加されます。
- フリーリストに複数のノードが存在するまで、手順2〜3が繰り返されます。
- 構築されたツリーに基づいて、アルファベットの各シンボルにプレフィックスコードが割り当てられます。
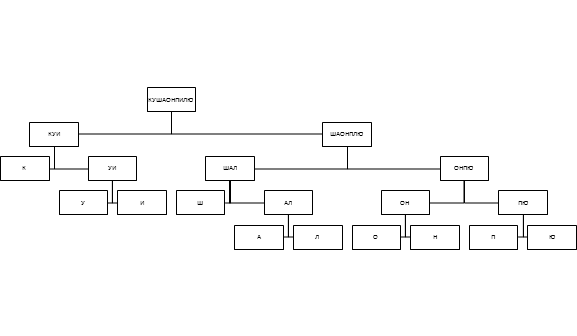
メッセージでは、ハフマンツリーは次のようになります。
ハフマンアルゴリズムを使用してエンコードされたメッセージは、わずか87ビット(ブロックコードと比較して25%のゲイン)しか占有しません。
すべての計算において、記号とコードの対応表をデコードする過程で既知であることを暗黙に暗示しましたが、実際にはこの条件は満たされていないため、表自体はエンコードされたメッセージとともに送信されます。 ほとんどの場合、このテーブルはエンコードされたメッセージの量と比較して小さく、その送信の事実は圧縮効率にほとんど影響しません。
それでも、テーブルの重みが重要になる状況が時々あります。 たとえば、ロスレスビデオ圧縮に関する私の論文では、この状況は常に発生しています。 さらに、アルファベットの力は数千万のエントリです。
従来のアプローチを使用する場合、テーブルに要素(対応するコード)が渡されると、オーバーヘッドが非常に大きくなるため、効果的な圧縮を忘れることがあります。 フォーム要素の送信-周波数にも欠点があります:
- デコーダーの肩には、コードツリーを構築する計算上困難なタスクがあります。
- 周波数の広がりは数桁であり、標準の実際の算術では常に正確に表示できるとは限りません。
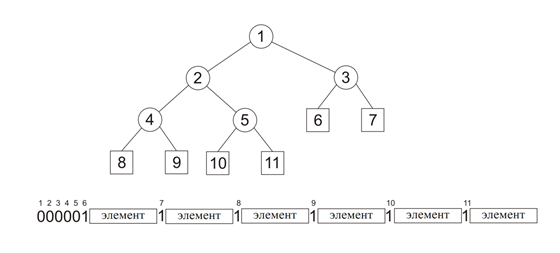
研究の結果、データベース全体ではなく、ツリーの構造を記述する要素と少量の追加情報を直接送信できるようになりました。 同時に、2つの追加ビットのみが各基本要素に追加送信されます。
構築されたコードツリーの走査順序に同意します。たとえば、幅の走査を使用します。 トラバーサル中に分割ツリーノードに遭遇した場合、ビット0が送信され、トラバーサル中にリーフが見つかった場合、ビット1およびkビットがエンコードされ、対応するベース要素がエンコードされます。 その結果、データベースの各要素に転送されるのは2ビットだけです。
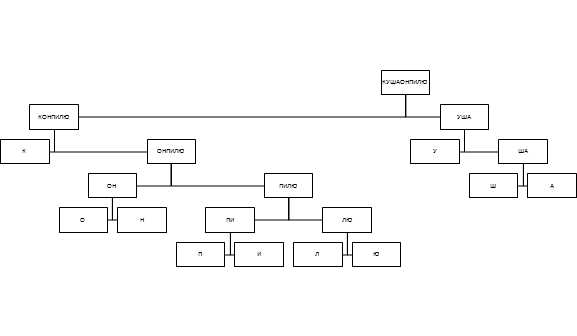
指定された表現は可逆です。つまり、説明された方法で構築された各行に対して、元のコードツリーを構築することが可能です。 明らかなメモリ節約に加えて、提案された送信方法は、デコード中にコードツリーを構築する必要をなくし、それによりデコード速度を大幅に向上させます。 この図は、説明した方法を使用したビット文字列としてのバイナリツリーの表現を示しています。
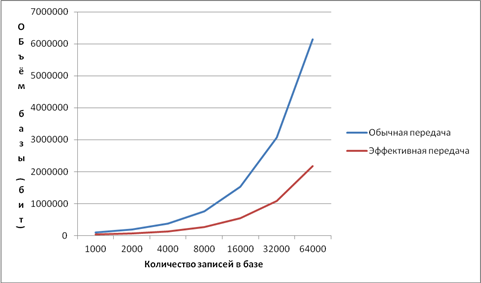
説明したエンコード方法を使用すると、伝送量が大幅に削減されます。 図は、ベースを送信するために説明した方法を使用する場合の送信ボリュームを示しています。
ただし、この方法でも大幅に改善できます。 エンコードとデコードの場合、ノードの相対的な(レベル内の)配置は絶対に重要ではないため、ノードをシャッフルする手順を実行できます。これは、すべての葉をツリーの左側に移動し、分割ノードを右側に移動することです。 つまり、ツリー:

ツリーに変換します

このような変換後、単一ビットは分割ノードだけでなく、このレベルで処理されたノードの左側にあるすべてのノードも分割していることを意味します。
このような最適化は重要ではないように思えるかもしれませんが、世界で(ほとんどのテストビデオシーケンスで)最高の損失のない圧縮率を達成できるようになったのは、それらでした。
PS完全に構築されたハフマンツリーの場合でも、小さな配列の場合に基本コードから要素コードを取得するタスクは実質的に不可能になり、最終的に根本的に新しいタイプのバイナリツリーが出現しました。 それが誰かに興味があるなら、私は喜んで別のトピックを書きます。
PPS提案されているビデオ圧縮方法については確実に説明しますが、少し後で説明します。