ステージング
ビジネスインテリジェンスソリューション(ビジネス分析)の問題は、自動化されたプロセスまたは一連のプロセスの結果に関する統計的、分析的な情報を関係者に提供することにあります。
たとえば、電子ストアの人々が行った購入を修正するビジネスプロセスがあります。 ビジネスプロセスのリレーショナルモデルでは、当然、売り手、買い手、商品、およびその他のエンティティが存在します。 さらに、ビジネスプロセスが成功した場合、つまり データの流れはかなり激しく、このデータを分析して経済的な問題を含むさまざまな問題を解決する必要があります。 投資家にとって、これは以下を反映するデータの集まりです。
- 今年の第1四半期に販売された商品の数
- 昨年売り手が販売した商品の量
- 毎月の特定のタイプの製品の販売のダイナミクス
- そして、他の多くの
さらに、店舗、レストラン、その他の種類のアクティビティを含む保有について話している場合、データ量が増加し、分析データの表現の種類も増加することがあります。
したがって、開発者は、データ分析のための最も広く、最も効果的で便利なツールを提供するという問題に直面しています。 Oracle、SAP、Microsoft、MicroStrategy、Pentahoなどのさまざまなブランドが提供するOLAPソリューションが助けになります。
事前にいくつかの予約をしたい:
- この記事では、ビジネスインテリジェンスソリューション(ビジネスインテリジェンス)のメインである専用リポジトリ(DBMS)を使用せずに、マルチパラメーターデータをRAMに保存する方法を提案しています。
- この記事では、OLAPキューブ、MOLAP、ROLAP、HOLAPの古典的な形式での構築の原則については説明しません。 それらの概要については、次の記事をお勧めします。
habrahabr.ru/post/66356-多次元キューブ、OLAPおよびMDX
habrahabr.ru/post/187782-手順でPentahoベースのOLAPサーバーを起動する
habrahabr.ru/post/67272-OLAPキューブを作成する パート1
habrahabr.ru/company/eastbanctech/blog/173711-シンプルなBIソリューションを構築する際の初心者向けの6つの実用的なヒント。
ブランドが提供するソリューションが特定のタスクに完全に適していない(それがまったく適切でない)か、会社の予算が特定のブランドの使用を許可していないと仮定します。
モデル設計
過去3年間の私の活動を考慮して、DevExpress、HighCharts、ExtJSなどのHTMLテクノロジとライブラリを使用して、エンドユーザーにマルチパラメーターデータを提供するビジネスダッシュボードを作成しています。 集約ストレージの機能は、集中的なデータ読み取りとブロック更新です。 作業の一環として、さまざまなタイプのリレーショナルデータモデルが集計の格納についてテストされましたが、これらのタイプはどれも望ましい効果をもたらしませんでした-高速読み取り速度。 これにより、この記事で説明したソリューションが実現しました。すべての集計データをRAMに保存するには、次のタスクが必要です。
- RAMの経済的な使用
- 指定された基準に従ってデータを抽出するための効率的なアルゴリズム
- ファイルストレージからのデータの保存と読み取り
まず、操作するエンティティを決定する必要があります。
- インジケータは、定量的および定性的な特性によって定義される名前付きエンティティです。 例-「収入」または「費用」
- 測定単位は、測定が計算される測定を定義する名前付きエンティティです。 例-「ドル」または「ルーブル」
- ディレクトリおよびディレクトリの要素は、インジケータに関連付けられた定性的特性を定義する名前付きエンティティです。 たとえば、要素「男性」と「女性」を含む「性的ディレクトリ」
- 期間-測定が行われた期間を定義する名前付きエンティティ。 例-「年」、「四半期」、「月」、「日」
- 値-集計値を数値形式で定義する名前付きエンティティ
リポジトリに保存する必要があるデータの次の例は、次のとおりです。
- 「女性」のコンテキストでの期間「2011」における企業の指標「所得」は、300「ドル」の値を持っていました
- 期間「2013年の第1四半期」の企業の指標「消費」の値は100「ルーブル」でした
このようにエンティティを定義したら、それらの関係を決定するクラスのオブジェクトモデルを決定する必要があります。
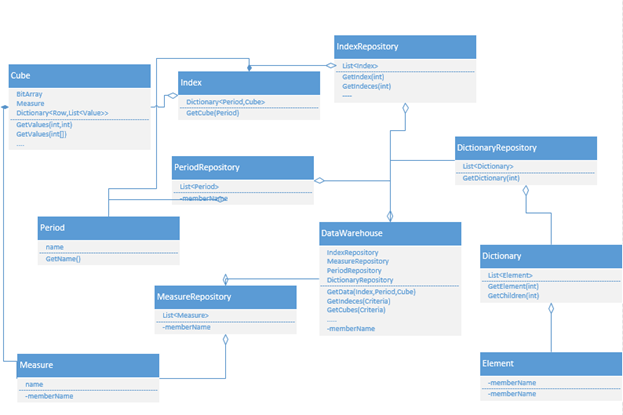
図からわかるように、クラス図には、 ObjectName Repository、DataWarehouseなどのユーティリティクラスが含まれています。 これらのクラスは、データコレクションを使用する場合に便利であり、特定のルールに従ってオブジェクトを提供するメインインターフェイスを定義する必要があります。
インデックスクラス-インジケーターの名前、インジケーターの可視属性、特定のアプリケーションに必要なその他の属性などの特性を含む「インジケーター」の本質を説明します。 IndexクラスにはCubeクラスが含まれます。
Cubeクラスは、インジケーター値の定性的特性と値自体(別名Data Cube)のリポジトリです。 特性の各セットは、キューブのすべてのディメンションの交差点にあります。 たとえば、「重量」、「色」、「サイズ」などの3つの特性の立方体がある場合、この3次元空間の各ポイントは、これらの各次元の確立された基準を構成します。 。 任意のデータキューブは、2次元マトリックスの形式で表すことができます。マトリックスの列には参照が含まれ、行には指定された特性が与えられます。 たとえば、このようなマトリックスの行1は、「重量-100 kg」、「色-赤」、「サイズ-小」の値を持つことができます。 次に、データ集合体を保存するために、可能なすべての特性の組み合わせを記述するマトリックスが必要です。 このようなクラスを作成する場合、RAMのデータストレージを最適化するために2つの方法を使用できます。
- オフセットを使用して1次元データ配列を使用する
- ビットマップを使用します。 この場合、マトリックスの各列の多様性を分析することが提案されています。 たとえば、「性別のディレクトリ」列の場合、「合計」、「男性」、「女性」の3つの値のみが必要です。 この列の値を占める可能性のあるデータの最大量は3ビットのみです。 したがって、各ディレクトリについて
Cubeクラスには、品質特性のセット全体の共通の測定単位を定義するMeasureクラスが含まれています。 これにより、利用可能な特性に応じて、さまざまな測定単位でインジケータの値を保存できます。 つまり 異なるキューブの同じインジケータには、キューブに対応する測定単位が含まれる場合があります。 たとえば、これはインジケータ「製品の販売」である場合があります。これは、「物」および金銭的な「ルーブル」で物理的に測定されます。 この記事では、単純なタイプのインジケーターのみを提供し、その測定単位は1つのキューブに対して1つのみです。 実際には、そのようなインジケータがあり、その測定単位はキューブの品質特性によって異なります。 次に、新しいレベルの抽象化に移行し、単純なデータセットと複雑なデータセットを提供するクラスを導入する必要があります。
Cubeクラスには、値自体(値セット)も含める必要があります。 つまり 特性の各セット-数値で表現される値を持つ必要があります。 この段階で、データ分類方法を適用して、RAM内のストレージを最適化できます。 たとえば、データベースを操作し、数値のストレージまたはフィールドを選択します-ほとんどの場合、可能な限り最大の浮動小数点数を選択します。 ただし、これは、特にRAMに関しては、非常にリソースを消費します。 実際には、すべてのインジケータがそのような精度を必要とするわけではありません。 たとえば、インジケータ「計画の割合」には、0〜100の整数値のみが必要な場合があります。1バイトで十分です。 したがって、BYTEからDECIMALまで、必要な最大タイプを決定するために、各インジケーターのデータの予備分析を実装できます。 次に、値の抽象化レベルに進み、このクラスからすべてを生成し、アプリケーションの実装に必要なすべての型を生成します。 実際には、この分析によって大幅なデータ圧縮が行われました。たとえば、データベースの値が1億の場合、DECIMALデータ型が必要なのはそのうちの5%だけでした。
この場合、そのようなストレージをモデル化するときは、すべてのデータをハードディスクに保存して読み込むためのメソッドを実装する必要があります。 標準のシリアル化を避け、BinaryWriterとBinaryReaderに基づいて独自のコードを作成することを強くお勧めします。 また、MemoryStreamクラスを集中的に使用することもお勧めします。 つまり ハードドライブの読み取りと書き込みのプロセスは、いくつかの段階に分かれています。
- メモリ内のストリームへの読み取り
- 標準アルゴリズムによるストリーム圧縮
- ハードドライブへのストリームの記録
そしてその逆:
- ハードディスクからメモリストリームへの読み取り
- フロー減圧
- データの読み取り
このアプローチにより、ハードドライブをロードすることなく、中央処理装置のいくつかのコアを使用してデータの圧縮および読み取りプロセスを最適化できます。 つまり ハードドライブからの読み取りと書き込みは順次実行されますが、メモリ内のストリームからの読み取りと書き込みは並列化できます。 そのため、実際には、ハードディスクから1億個の値(約2 GBの圧縮データ)を読み取り、メモリで解凍してクラス(最大35 GB)を生成するには、32コアXeonサーバーを使用して約5分かかります。 リレーショナルDBMSから同様のデータを抽出するには、約5日かかりました。
この記事では、そのようなリポジトリのデータを更新するオプションについては説明しません。 ただし、データの読み取りなど、ストレージの主なタスクでは、このモデルは100%に対応します。 このようなストレージのデータを更新するには、メモリモードへの排他的アクセスを提供する必要があります。 また、システムを開発するには、RAMの技術的な制限を考慮して、システムを分散RAM(シャーディング)に合わせて開発する必要があります。
この記事では、データ集約手順が外部環境で行われ、集約がすでにシステムに入っていることを前提としています。
また、この記事では、特にLINQテクノロジーの使用を考慮して、ほとんどの場合、オブジェクトの類似性または相違点の特性を比較する操作がある、自明性の観点からアプリケーションコードを提供していません。
おわりに
リレーショナルデータベースのすべての美しさと汎用性には、事前に準備されたテンプレートを使用して解決できないタスクがあります。 集約データストレージの例-BIシステムを設計するための代替アプローチが示されています。 ご覧のとおり、このアプローチにより、情報システムのボトルネックである集中的な抽出中にハードドライブからデータを読み取るプロセスが実質的に排除されます。 ハードドライブからの読み取りプロセスを除外したため、ハードドライブの技術的能力によって与えられるデータへのアクセス速度を制限するという主要な問題を解決します。
実際、集約ストレージデータを使用する場合、たとえば次のように実装する必要のある限られた機能が発生します。
- 指定されたタイプの「期間」について、指定された「特性」の「指標」の値を取得します
- 「特性」の一部が定義されている場合、キューブごとに「残差」(つまり、インジケータごとの残りの利用可能なすべての特性)を取得
- 複数の指標からのデータを組み合わせる
- 与えられた特性による指標の検索
ほとんどの場合、データ出力は、指定された基準に従って満たされたマトリックスです。これは、リレーショナルデータベースから取得された同じRecordSetとDataTableです。