最初の部分では、ニューロンの特性について説明しました。 2番目は、彼らの学習に関連する基本的な特性について話しました。 すでに次のパートで、実際の脳の仕組みを説明します。 しかしその前に、最後の努力をして、もう少し理論をとる必要があります。 今では、特に興味深いとは思えないでしょう。 おそらく、私自身はそのようなトレーニングポストをマイナスしているでしょう。 しかし、これらの「アルファベット」はすべて、将来の理解に大いに役立ちます。
パーセプトロン
機械学習では、教師との学習と教師なしの学習という2つの主なアプローチが共有されます。 上記の主要なコンポーネントを強調する方法は、教師なしで教えることです。 ニューラルネットワークは、入力で何が供給されるかについての説明を受け取りません。 入力データストリームに存在する統計パターンを単に強調表示します。 対照的に、教師による指導は、トレーニングセットと呼ばれるいくつかの入力画像について、どの出力を取得したいかを知っていることを示唆しています。 したがって、タスクは、入力データと出力データを接続するパターンをキャッチするような方法でニューラルネットワークを構成することです。
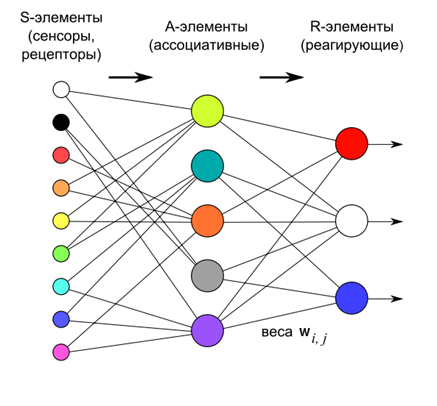
1958年に、フランクローゼンブラットは、パーセプトロンと呼ばれる構造(Rosenblatt、1958)について説明しました。
ローゼンブラットによると、パーセプトロンはニューロンの3つの層で構成されています。 最初の層は、入力にあるものを決定する感覚要素です。 2番目のレイヤーは連想要素です。 センサーレイヤーとの関係は厳密に定義されており、センサーレイヤー上よりも一般的な説明の関連図への移行を決定します。
パーセプトロンは、3番目の反応層のニューロンの重みを変更することにより訓練されます。 トレーニングの目的は、パーセプトロンに提出された画像を正しく分類させることです。
第3層のニューロンは、しきい値加算器として機能します。 したがって、それらのそれぞれの重みは、特定の超平面のパラメータを決定します。 線形に分離可能な入力信号がある場合、出力ニューロンは分類器として機能するだけです。
もし
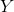 パーセプトロンaの実出力のベクトルです。
パーセプトロンaの実出力のベクトルです。 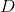 受信することが予想されるベクトルである場合、エラーベクトルはニューラルネットワークの品質を示します。
受信することが予想されるベクトルである場合、エラーベクトルはニューラルネットワークの品質を示します。
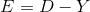
標準誤差を最小化するために目標を設定した場合、重みを変更するためのいわゆるデルタ規則を導出できます。
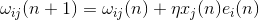
この場合、ゼロの重みが初期近似になります。
この規則は、パーセプトロンの場合に適用されるヘブの規則に過ぎません。
出力層の後ろに1つ以上の反応層を配置し、計算の必要性よりも生物学的信頼性のためにRosenblattによって導入された関連層を放棄すると、下図に示すような多層パーセプトロンが得られます。
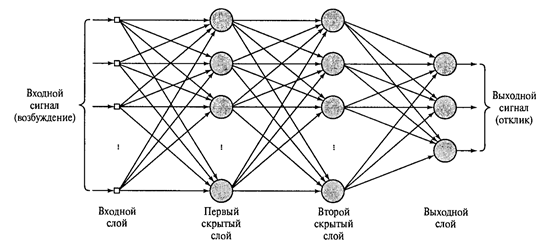
2つの隠れ層を持つ多層パーセプトロン(Khaikin、2006年)
反応層のニューロンが単純な線形加算器である場合、そのような複雑さにはあまり意味がありません。 出力は、隠れ層の数に関係なく、入力信号の線形結合のままです。 ただし、しきい値加算器は非表示レイヤーで使用されるため、このような新しいレイヤーはそれぞれ直線性の連鎖を破り、独自の興味深い説明を伝えることができます。
長い間、多層パーセプトロンを訓練する方法は明確ではありませんでした。 主な方法-エラーの逆伝播の方法は、1974 A.I. ガラシュキンと独立して同時にポール・J・バーボス。 その後、1986年に再発見され、広く知られるようになりました(David E. Rumelhart、Geoffrey E. Hinton、Ronald J. Williams、1986)。
このメソッドは、フォワードとリバースの2つのパスで構成されています。 ダイレクトパスでは、トレーニング信号が供給され、出力層のアクティビティを含むすべてのネットワークノードのアクティビティが計算されます。 受信に必要なものから取得したアクティビティを減算すると、エラー信号が決定されます。 リターンパスでは、エラー信号は出力から入力へ逆方向に伝播します。 この場合、この誤差を最小限に抑えるためにシナプスの重みが調整されます。 この方法の詳細な説明は、多くの情報源で見つけることができます(たとえば、Khaikin、2006)。
多層パーセプトロンでは情報がレベルごとに処理されるという事実に注意を払うことが重要です。 同時に、各レイヤーは、入力信号に特徴的な独自の機能セットを選択します。 これにより、大脳皮質の領域間で情報がどのように変換されるかについて特定の類似性が生まれます。
畳み込みネットワーク。 ネオコグニトロン
多層パーセプトロンと実際の脳の比較は非常にarbitrary意的です。 一般的には、ゾーンからクラストのゾーンへ、またはパーセプトロンのレイヤーからレイヤーへと上昇するにつれて、情報はますます一般化された記述を獲得します。 しかし、皮質の構造は、パーセプトロンのニューロン層の組織よりもはるかに複雑です。 D.ヒューベルとT.ヴィーゼルの視覚系の研究により、視覚皮質の構造をよりよく理解することが可能になり、この知識をニューラルネットワークで使用することが奨励されました。 使用された主なアイデアは、知覚ゾーンの局所性と、ニューロンを1つのレイヤー内の機能に分割することです。
知覚の局所性はすでによく知られています。つまり、情報を受け取るニューロンは信号の入力空間全体を監視するのではなく、その一部のみを監視します。 このような追跡領域は、ニューロンの受容野と呼ばれると以前に言いました。
受容野の概念には、別の明確化が必要です。 伝統的に、ニューロンの受容体フィールドは、ニューロンの機能に影響を与える受容体の空間と呼ばれています。 ここでの受容体は、外部信号を直接知覚するニューロンです。 2つの層で構成されるニューラルネットワークを想像してください。最初の層は受容体層で、2番目の層は受容体に接続されたニューロンです。 2番目の層の各ニューロン、それと接触している受容体-これがその受容野です。
次に、複雑な多層ネットワークを作成します。 入り口から遠ざかるほど、どの受容体とそれらが深部ニューロンの活動にどのように影響するかを示すのが難しくなります。 ある瞬間から、どんなニューロンに対しても、既存のすべての受容体はその受容野と呼ばれることが判明するかもしれません。 このような状況では、彼が直接シナプス接触しているニューロンのみがニューロンの受容野と呼ばれます。 これらの概念を分離するために、入力受容体の空間-初期受容野と呼びます。 そして、ニューロンと直接相互作用するニューロンの空間-さらなる明確化なしの局所受容野または単なる受容野。
ニューロンの機能への分割は、一次視覚野の2つの主要なタイプのニューロンの検出に関連しています。 単純なニューロンは、元の受容野の特定の場所にある刺激に反応します。 複雑なニューロンは、その位置に関係なく、刺激に対してアクティブです。
たとえば、次の図は、単純なセルの初期受容野の感度パターンがどのように見えるかのオプションを示しています。 正の領域はそのようなニューロンを活性化し、負の領域は抑制します。 単純なニューロンにはそれぞれ最適な刺激があり、それに応じて最大の活動を引き起こします。 しかし、この刺激が初期受容野の位置に厳密に結び付けられていることが重要です。 同じ刺激ですが、横にシフトしても、単純なニューロン反応は発生しません。
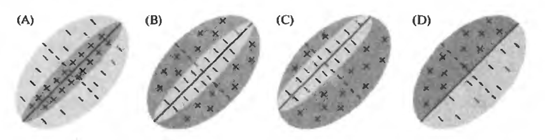
単純な細胞の初期受容野(Nicholls J.、Martin R.、Wallas B.、Fuchs P.)
複雑なニューロンにも好ましい刺激がありますが、最初の受容野での位置に関係なく、この刺激を認識することができます。
これらの2つのアイデアから、ニューラルネットワークの対応するモデルが生まれました。 このような最初のネットワークは、福島邦彦によって作成されました。 コグニトロンと呼ばれます。 彼は後に、より高度なネットワークであるネオコグニトロン(福島、1980年)を作成しました。 ネオコグニトロンは、いくつかの層の構造です。 各層は、単純なニューロン(s)と複雑なニューロン(c)で構成されています。
単純なニューロンのタスクは、その受容野を監視し、訓練された画像を認識することです。 単純なニューロンはグループ(平面)で収集されます。 1つのグループ内で、単純なニューロンは同じ刺激に調整されますが、各ニューロンは受容野の断片を監視します。 一緒に、彼らはこの画像のすべての可能な位置をソートします(以下の図)。 同じ平面の単純なニューロンはすべて同じ重みを持ちますが、受容野は異なります。 別の方法で状況を想像できます。それは、元の画像のすべての位置に対して一度にその画像を試すことができるニューロンです。 これにより、位置に関係なく同じ画像を認識できます。
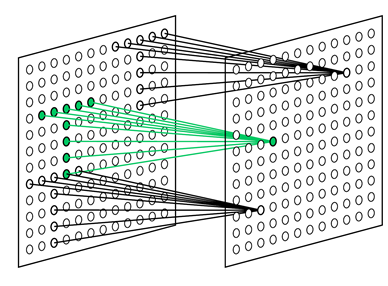
異なる位置で選択されたパターンを検索するように構成された単純なセルの受容フィールド(福島K.、2013)
各複雑なニューロンは、単純なニューロンの平面を監視し、その平面内の少なくとも1つの単純なニューロンがアクティブな場合にトリガーされます(下図)。 単純なニューロンの活動は、彼がその特定の場所、つまり彼の受容野で特徴的な刺激を認識したことを示唆しています。 複雑なニューロンの活動とは、単純なニューロンによって監視されているレイヤー上で同じ画像が一般的に見つかることを意味します。
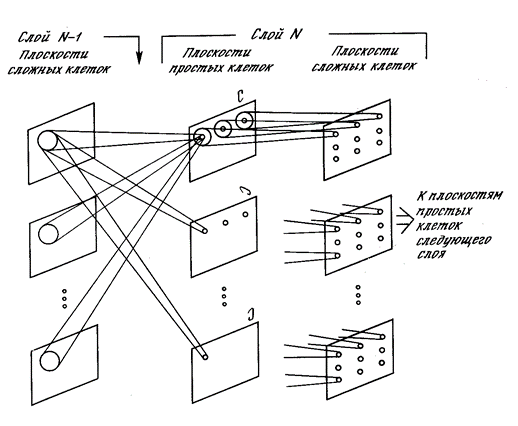
ネオコグニトロン機
入力後の各層には、前の層の複雑なニューロンとその入力によって形成された画像があります。 レイヤーからレイヤーへと、情報の一般化がますます増えており、その結果、元の画像内の位置や何らかの変換に関係なく、特定の画像が認識されるようになります。
画像分析に適用される場合、これは、最初のレベルが小さな受容野を通過する特定の角度の線を認識することを意味します。 彼は、画像内のどこでも可能なすべての方向を検出することができます。 次のレベルでは、基本記号の可能な組み合わせを検出し、より複雑な形式を定義します。 目的の画像を決定できるようになるまで、そのレベルまで続けます(下図)。

ネオコグニトロン認識プロセス
このようなデザインは、手書き認識に使用される場合、筆記方法に耐性があります。 認識の成功は、表面の動きや回転、または変形(張力または圧縮)の影響を受けません。
ネオコグニトロンと完全に接続された多層パーセプトロンの最も大きな違いは、同数のニューロンで使用される重みの数が大幅に少ないことです。 これは、ネオコグニトロンが位置に関係なく画像を判別できる「トリック」によるものです。 単純なセルの平面は、本質的に、その重みが畳み込みのコアを決定する1つのニューロンです。 このコアは前のレイヤーに適用され、すべての可能な位置で実行されます。 実際には、各平面のニューロンは、これらの位置の座標に座標を設定します。 これは、単純な細胞の層のすべてのニューロンが、核に対応する画像が受容野に現れるかどうかを監視するという事実につながります。 つまり、このような画像がこの層の入力信号のどこかに発生すると、少なくとも1つの単純なニューロンによって検出され、対応する複雑なニューロンの活動を引き起こします。 このトリックを使用すると、どこにいても特徴的な画像を見つけることができます。 しかし、これは正確にトリックであり、実際の皮質の仕事に特に対応するものではないことを覚えておく必要があります。
ネオコグニトロンのトレーニングは、教師なしで行われます。 これは、要因の完全なセットを分離するための前述の手順に対応しています。 実際の画像がネオコグニトロンに入力されると、ニューロンはこれらの画像に特徴的なコンポーネントを分離する以外に選択肢がありません。 したがって、手書きの数字を入力に送信すると、最初の層の単純なニューロンの小さな受容野には、線、角度、共役が表示されます。 競技ゾーンのサイズは、各空間領域でいくつの異なる要因が際立っているかを決定します。 まず、最も重要なコンポーネントが強調表示されます。 手書きの数字の場合、これらは異なる角度の線になります。 自由な要素が残っている場合、より複雑な要素が目立つ可能性があります。
層から層へ、学習の一般原則は保持されます-多くの入力信号の特性である要因が強調表示されます。 特定のレベルで、手書きの数字を最初のレイヤーに送信することにより、これらの数字に対応する要因を取得します。 各図は、別個の要素として際立った安定した一連の機能の組み合わせであることがわかります。 ネオコグニトロンの最後の層には、検出する画像と同じ数のニューロンが含まれています。 この層のニューロンの1つの活動は、対応する画像の認識を示します(下図)
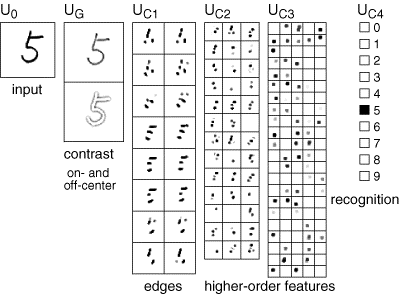
ネオコグニトロンでの認知(福島K.、ネオコグニトロン、2007年)
以下のビデオでは、ネオコグニトロンの視覚的表現を取得できます。
教師なしで学習する代わりに、教師とともに学習します。 したがって、数字のある例では、ネットワーク自体が統計的に安定したフォームを識別するまで待つことができませんが、どのような数字が彼女に提示され、適切なトレーニングが必要かを彼女に伝えます。 このような畳み込みネットワークのトレーニングで最も重要な結果は、Yan LeCunによって達成されました(Y. LeCunおよびY. Bengio、1995)。 彼は、ネオコグニトロンのようなアーキテクチャが大脳皮質の構造に漠然と似ているネットワークを訓練するために、エラー逆伝播法をどのように使用できるかを示しました。

手書き認識のための畳み込みネットワーク(Y. LeCunおよびY. Bengio、1995)
これについては、最小限の初期情報が思い出され、より興味深く驚くべきことに行くことができると仮定します。
継続
前のパーツ:
パート1.ニューロン
パート2.要因