 このトピックでは、テーブルを操作する際のパフォーマンスの改善についてお話したいと思います。
このトピックでは、テーブルを操作する際のパフォーマンスの改善についてお話したいと思います。
このトピックは新しいものではありませんが、データベースが絶えずデータを増大させている場合(テーブルが大きくなり、それらの検索と選択が遅い場合)に特に重要になります。
通常、これは設計が不十分な回路によるもので、元々大量のデータを処理するように設計されていません。
テーブル内のデータが増えても、テーブルを操作する際の生産性が低下しないように、回路を設計する際にいくつかのルールを採用することをお勧めします。
最初の、おそらく最も重要なもの。 テーブルのデータ型には、最小限の冗長性が必要です。
SQL Serverが動作するすべてのデータは、8 KBの固定サイズを持ついわゆるページに保存されます。 書き込みおよび読み取り時、サーバーは個別の行ではなくページで動作します。
したがって、テーブルで使用されるデータタイプがコンパクトであればあるほど、それらを格納するために必要なページが少なくなります。 より少ないページ-より少ないディスク操作。
ディスクサブシステムの負荷の明らかな削減に加えて、この場合、別の利点があります-ディスクから読み取る場合、ページは最初に特別なメモリ領域( Buffer Pool )に配置され、次に目的の目的で使用されます-データを読み取りまたは変更します。
コンパクトデータタイプを使用する場合、 バッファプール内の同じページ数により多くのデータを入れることができます。これにより、RAMを無駄にせず、論理演算の数を減らします。
次に、小さな例を考えてみましょう-各従業員の就業日に関する情報を保存するテーブル。
CREATE TABLE dbo.WorkOut1 ( DateOut DATETIME , EmployeeID BIGINT , WorkShiftCD NVARCHAR(10) , WorkHours DECIMAL(24,2) , CONSTRAINT PK_WorkOut1 PRIMARY KEY (DateOut, EmployeeID) )
テーブルのデータ型は正しく選択されていますか? どうやら。
たとえば、企業には非常に多くの従業員がいる(2 ^ 63-1)ため、この状況に対応するためにBIGINTデータ型が選択されていることは非常に疑わしいです。
冗長性を削除し、そのようなテーブルからのクエリが高速かどうかを確認しますか?
CREATE TABLE dbo.WorkOut2 ( DateOut SMALLDATETIME , EmployeeID INT , WorkShiftCD VARCHAR(10) , WorkHours DECIMAL(8,2) , CONSTRAINT PK_WorkOut2 PRIMARY KEY (DateOut, EmployeeID) )
実行計画では、平均行サイズとクエリが返す予想行数に依存するコストの違いを確認できます。
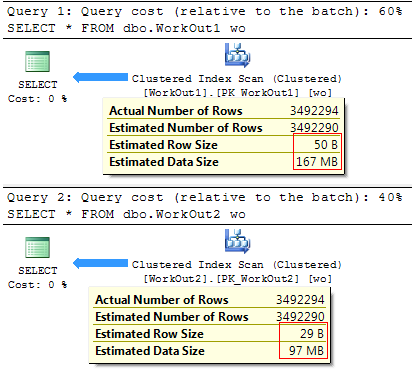
読む必要があるデータの量が少ないほど、クエリはより速く実行されることが論理的です。
(3492294行が影響を受けます)
SQL Serverの実行時間:
CPU時間= 1919ミリ秒、経過時間= 33606ミリ秒。
(3492294行が影響を受けます)
SQL Serverの実行時間:
CPU時間= 1420ミリ秒、経過時間= 29694ミリ秒。
ご覧のとおり、冗長性の少ないデータ型を使用すると、クエリのパフォーマンスにプラスの効果があり、問題のあるテーブルのサイズを大幅に削減できます。
ところで、次のクエリを使用してテーブルのサイズを確認できます。
SELECT table_name = SCHEMA_NAME(o.[schema_id]) + '.' + o.name , data_size_mb = CAST(do.pages * 8. / 1024 AS DECIMAL(8,4)) FROM sys.objects o JOIN ( SELECT p.[object_id] , total_rows = SUM(p.[rows]) , total_pages = SUM(a.total_pages) , usedpages = SUM(a.used_pages) , pages = SUM( CASE WHEN it.internal_type IN (202, 204, 207, 211, 212, 213, 214, 215, 216, 221, 222) THEN 0 WHEN a.[type] != 1 AND p.index_id < 2 THEN a.used_pages WHEN p.index_id < 2 THEN a.data_pages ELSE 0 END ) FROM sys.partitions p JOIN sys.allocation_units a ON p.[partition_id] = a.container_id LEFT JOIN sys.internal_tables it ON p.[object_id] = it.[object_id] GROUP BY p.[object_id] ) do ON o.[object_id] = do.[object_id] WHERE o.[type] = 'U'
問題のテーブルの場合、クエリは次の結果を返します。
table_name data_size_mb -------------------- ------------------------------- dbo.WorkOut1 167.2578 dbo.WorkOut2 97.1250
2番目のルール。 重複を避け、データの正規化を適用します。
実際、最近、 T-SQLコードをフォーマットするための1つの無料Webサービスのデータベースを分析しました。 そこにあるサーバー部分は非常にシンプルで、1つのテーブルで構成されています。
CREATE TABLE dbo.format_history ( session_id BIGINT , format_date DATETIME , format_options XML )
フォーマット中に毎回、現在のセッションのID、サーバーシステム時間、およびユーザーがSQLコードをフォーマットした設定が保存されました。 次に、データを使用して、最も一般的な書式設定スタイルを特定しました。
サービスの人気が高まると、テーブル内の行数が増加し、プロファイルのフォーマット処理に時間がかかりました。 その理由は、サービスアーキテクチャでした。テーブルに挿入するたびに、設定の完全なセットが保存されました。
設定のXML構造は次のとおりです。
<FormatProfile> <FormatOptions> <PropertyValue Name="Select_SelectList_IndentColumnList">true</PropertyValue> <PropertyValue Name="Select_SelectList_SingleLineColumns">false</PropertyValue> <PropertyValue Name="Select_SelectList_StackColumns">true</PropertyValue> <PropertyValue Name="Select_SelectList_StackColumnsMode">1</PropertyValue> <PropertyValue Name="Select_Into_LineBreakBeforeInto">true</PropertyValue> ... <PropertyValue Name="UnionExceptIntersect_LineBreakBeforeUnion">true</PropertyValue> <PropertyValue Name="UnionExceptIntersect_LineBreakAfterUnion">true</PropertyValue> <PropertyValue Name="UnionExceptIntersect_IndentKeyword">true</PropertyValue> <PropertyValue Name="UnionExceptIntersect_IndentSubquery">false</PropertyValue> ... </FormatOptions> </FormatProfile>
合計450のフォーマットオプション-テーブルの各行には約33 KBが必要でした。 また、毎日のデータの増加は100MBを超えました。 毎日ベースが成長し、その分析が長くなり始めました。
状況を修正するのは簡単であることが判明しました-すべての一意のプロファイルが個別のテーブルに移動され、オプションの各セットに対してハッシュが取得されました。 SQL Server 2008以降では、 sys.fn_repl_hash_binary関数を使用してこれを行うことができます。
その結果、回路は正規化されました。
CREATE TABLE dbo.format_profile ( format_hash BINARY(16) PRIMARY KEY , format_profile XML NOT NULL ) CREATE TABLE dbo.format_history ( session_id BIGINT , format_date SMALLDATETIME , format_hash BINARY(16) NOT NULL , CONSTRAINT PK_format_history PRIMARY KEY CLUSTERED (session_id, format_date) )
そして、校正要求が以前は次のようなものだった場合:
SELECT fh.session_id, fh.format_date, fh.format_options FROM SQLF.dbo.format_history fh
新しいスキームで同じデータを取得するには、JOINを作成する必要がありました。
SELECT fh.session_id, fh.format_date, fp.format_profile FROM SQLF_v2.dbo.format_history fh JOIN SQLF_v2.dbo.format_profile fp ON fh.format_hash = fp.format_hash
クエリの実行時間を比較すると、スキームを変更しても明確な利点はありません。
(3090行が影響を受けます)
SQL Serverの実行時間:
CPU時間= 203ミリ秒、経過時間= 4698ミリ秒。
(3090行が影響を受けます)
SQL Serverの実行時間:
CPU時間= 125ミリ秒、経過時間= 4479ミリ秒。
しかし、この場合の目標はもう1つ追求されました-分析を加速することです。 また、最も一般的なフォーマットプロファイルのリストを取得する前に、非常に洗練されたクエリを作成する必要があった場合:
;WITH cte AS ( SELECT fh.format_options , hsh = sys.fn_repl_hash_binary(CAST(fh.format_options AS VARBINARY(MAX))) , rn = ROW_NUMBER() OVER (ORDER BY 1/0) FROM SQLF.dbo.format_history fh ) SELECT c2.format_options, c1.cnt FROM ( SELECT TOP (10) hsh, rn = MIN(rn), cnt = COUNT(1) FROM cte GROUP BY hsh ORDER BY cnt DESC ) c1 JOIN cte c2 ON c1.rn = c2.rn ORDER BY c1.cnt DESC
データの正規化により、クエリ自体だけでなく、大幅に単純化することが可能になりました。
SELECT fp.format_profile , t.cnt FROM ( SELECT TOP (10) fh.format_hash , cnt = COUNT(1) FROM SQLF_v2.dbo.format_history fh GROUP BY fh.format_hash ORDER BY cnt DESC ) t JOIN SQLF_v2.dbo.format_profile fp ON t.format_hash = fp.format_hash
しかし、実行時間を短縮するためにも:
(10行が影響を受けます)
SQL Serverの実行時間:
CPU時間= 2684ミリ秒、経過時間= 2774ミリ秒。
(10行が影響を受けます)
SQL Serverの実行時間:
CPU時間= 15ミリ秒、経過時間= 379ミリ秒。
また、ディスク上のデータベースのサイズを小さくすることもできました。
database_name row_size_mb ---------------- --------------- SQLF 123.50 SQLF_v2 7.88
次のクエリを使用して、データベースのデータファイルのサイズを返すことができます。
SELECT database_name = DB_NAME(database_id) , row_size_mb = CAST(SUM(CASE WHEN type_desc = 'ROWS' THEN size END) * 8. / 1024 AS DECIMAL(8,2)) FROM sys.master_files WHERE database_id IN (DB_ID('SQLF'), DB_ID('SQLF_v2')) GROUP BY database_id
この例で、データの正規化とデータベースの冗長性の最小化の重要性を示すことができたと思います。
三番目。 インデックスに含まれる列を慎重に選択します。
インデックスは、テーブルからの選択を大幅に高速化できます。 テーブルのデータと同様に、インデックスはページに保存されます。 したがって。 インデックスの保存に必要なページが少ないほど、検索を高速化できます。
クラスタ化インデックスに含めるフィールドを選択することは非常に重要です。 クラスタ化インデックスのすべての列は、(ポインタによって)各非クラスタ化に自動的に含まれるため。
4番目。 中間テーブルと統合テーブルを使用します。
ここではすべてが非常に単純です。小さなテーブルから単純なクエリを作成できる場合、毎回大きなテーブルから複雑なクエリを作成する理由です。
たとえば、データ統合リクエストが利用可能です:
SELECT WorkOutID , CE = SUM(CASE WHEN WorkKeyCD = 'CE' THEN Value END) , DE = SUM(CASE WHEN WorkKeyCD = 'DE' THEN Value END) , RE = SUM(CASE WHEN WorkKeyCD = 'RE' THEN Value END) , FD = SUM(CASE WHEN WorkKeyCD = 'FD' THEN Value END) , TR = SUM(CASE WHEN WorkKeyCD = 'TR' THEN Value END) , FF = SUM(CASE WHEN WorkKeyCD = 'FF' THEN Value END) , PF = SUM(CASE WHEN WorkKeyCD = 'PF' THEN Value END) , QW = SUM(CASE WHEN WorkKeyCD = 'QW' THEN Value END) , FH = SUM(CASE WHEN WorkKeyCD = 'FH' THEN Value END) , UH = SUM(CASE WHEN WorkKeyCD = 'UH' THEN Value END) , NU = SUM(CASE WHEN WorkKeyCD = 'NU' THEN Value END) , CS = SUM(CASE WHEN WorkKeyCD = 'CS' THEN Value END) FROM dbo.WorkOutFactor WHERE Value > 0 GROUP BY WorkOutID
テーブル内のデータがあまり頻繁に変更されない場合は、別のテーブルを作成できます。
SELECT * FROM dbo.WorkOutFactorCache
そして、驚くことではありませんが、統合されたテーブルからの読み取りが高速になります。
(185916行が影響を受けます)
SQL Serverの実行時間:
CPU時間= 3448ミリ秒、経過時間= 3116ミリ秒。
(185916行が影響を受けます)
SQL Serverの実行時間:
CPU時間= 1410ミリ秒、経過時間= 1202ミリ秒。
5番目。 各ルールには独自の例外があります。
データ型を冗長性の少ないものに変更することでクエリの実行時間を短縮できる場合の例をいくつか示しました。 しかし、これは常にそうではありません。
たとえば、 BITデータ型には1つの機能があります。SQLServerは、この型の列のグループのディスク上のストレージを最適化します。 たとえば、テーブルにBIT型の列が8個以下の場合、それらは1バイトとしてページに格納され、 BIT型の列が最大16個ある場合、2バイトとして格納されます。
幸いなことに、テーブルが占めるスペースが大幅に減り、ディスク操作の回数が減ります。
悪いニュースは、このタイプのデータをサンプリングすると、暗黙的なデコードが発生することです。これは、プロセッサリソースを非常に要求します。
これを例で示します。 従業員のカレンダースケジュールに関する情報を含む3つの同一のテーブルがあります(31 + 2 PK列)。 それらはすべて、統合された値のデータ型のみが異なります(1-稼働し、0-欠落しました):
SELECT * FROM dbo.E_51_INT SELECT * FROM dbo.E_52_TINYINT SELECT * FROM dbo.E_53_BIT
冗長性の低いデータを使用すると、テーブルのサイズが著しく減少しました(特に最後のテーブル)。
table_name data_size_mb -------------------- -------------- dbo.E31_INT 150.2578 dbo.E32_TINYINT 50.4141 dbo.E33_BIT 24.1953
ただし、 BITタイプを使用しても速度が大幅に向上することはありません。
(1000000 row(s) affected) Table 'E31_INT'. Scan count 1, logical reads 19296, physical reads 1, read-ahead reads 19260, ... SQL Server Execution Times: CPU time = 1607 ms, elapsed time = 19962 ms. (1000000 row(s) affected) Table 'E32_TINYINT'. Scan count 1, logical reads 6471, physical reads 1, read-ahead reads 6477, ... SQL Server Execution Times: CPU time = 1029 ms, elapsed time = 16533 ms. (1000000 row(s) affected) Table 'E33_BIT'. Scan count 1, logical reads 3109, physical reads 1, read-ahead reads 3096, ... SQL Server Execution Times: CPU time = 1820 ms, elapsed time = 17121 ms.
実装計画では逆のことが言えますが:
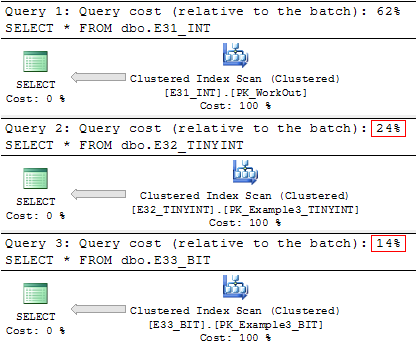
観察の結果、テーブルに含まれるBIT列が8 ビット以下の場合、デコーディングの悪影響は発生しないことがわかりました 。
ちなみに、 SQL Serverメタデータでは、 BITデータ型はほとんど使用されないことに注意してください-BINARY型を使用し、特定の値を取得するために手動でシフトすることがよくあります。
そして最後に言及すること。 不要なデータを削除します。
実際、なぜこれを行うのですか?
データをフェッチするとき、SQL Serverは先読みと呼ばれるパフォーマンス最適化メカニズムをサポートします。これは、クエリを実行するために必要なデータとインデックスページを予測し、これらのページを実際に必要になる前にバッファーキャッシュに入れます。
したがって、テーブルに余分なデータが大量に含まれていると、不必要なディスク操作が発生する可能性があります。
さらに、不要なデータを削除することにより、 バッファープールからデータを読み取る際の論理操作の数を減らすことができます。データの検索と選択は、より少ないデータで行われます。
結論として、私が追加できること-テーブルの列のデータ型を慎重に選択し、将来のデータベースの負荷を考慮に入れてください。
この記事を英語圏の聴衆と共有したい場合は、翻訳へのリンクを使用してください。
SQL Serverデータベースのテーブルサイズを削減するための実用的なヒント