私たちのプロジェクトPT Application Inspectorは、さまざまなプログラミング言語でソースコードを分析するためのいくつかのアプローチを実装しています。
- 署名検索
- コードの静的な抽象解釈の結果として得られた数学モデルの特性の研究。
- デプロイされたアプリケーションの動的分析および静的分析の結果の検証。
私たちの一連の記事は、署名検索モジュール(PM、パターンマッチング)の構造と動作原理に専念しています。 このようなアナライザーの利点は、速度、テンプレートの記述の容易さ、および他の言語へのスケーラビリティです。 欠点の中でも、このモジュールは、コード実行の高レベルモデルの構築を必要とする複雑な脆弱性を分析できません。
とりわけ、開発されたモジュールに対して次の要件が策定されました。
- いくつかのプログラミング言語のサポートと新しい言語の簡単な追加。
- 構文エラーと意味エラーを含むコードの解析のサポート。
- テンプレートをユニバーサル言語(DSL、ドメイン固有言語)で記述する機能。
私たちの場合、すべてのテンプレートはソースコードの脆弱性または欠陥を記述しています。
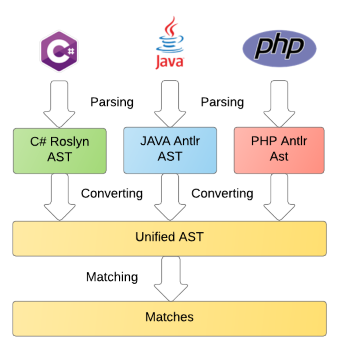
コード分析のプロセス全体は、次のステップに分けることができます。
- 言語依存表現(抽象構文ツリー、AST)への解析。
- ASTを言語に依存しない統一された形式に変換します
- DSLで説明されているテンプレートへの直接マッピング。
この記事は、最初の段階、つまり解析、さまざまなパーサーの機能と機能の比較、Java、PHP、PLSQL、TSQL、さらにはC#文法を例として使用して実際に理論を適用することに専念します。 残りの手順については、以降の出版物で説明します。
内容
解析理論
初めに、疑問が生じるかもしれません:なぜ統一されたASTを構築し、正規表現を使用する代わりにグラフマッチングアルゴリズムを開発するのですか? 実際、正規表現を使用してすべてのパターンを簡単かつ便利に説明できるわけではありません。 たとえば、C#では、名前付きグループとバックリンクのおかげで、C#の正規表現にはコンテキストのない文法の力があることに注意してください(ただし、そのような表現を使用してパターンを記述するプロセスは、 他のわいせつな表現を伴う 複雑)。 このテーマに関するPVS-Studioの開発者からの記事もあります。 さらに、結果として得られる統一されたASTの接続性により、将来、それを使用して、コードプロパティのグラフなど、コード実行のより複雑な表現を構築できるようになります 。
用語
構文解析理論に精通している人はこのセクションを飛ばすかもしれません。
解析は、ソースコードを構造化ビューに変換するプロセスです。 典型的なパーサーは、レクサーとパーサーの組み合わせです。 レクサーは、ソースコード内の文字をトークンと呼ばれる意味のあるシーケンスにグループ化します。 その後、トークンのタイプが決定されます(識別子、番号、文字列など)。 トークンは、トークンの意味とそのタイプの組み合わせです。 次の図の例では、トークンはsp 、 = 、 100です。 パーサーは、解析ツリーと呼ばれるトークンストリームから接続されたツリー構造を構築します。 この場合、 assignはツリーのノードの1つです。 抽象構文ツリーまたはASTは、ブラケット、コンマなどの重要でないトークンが削除される、より高いレベルの解析ツリーです。 ただし、字句解析と解析の手順を組み合わせたパーサーがあります。
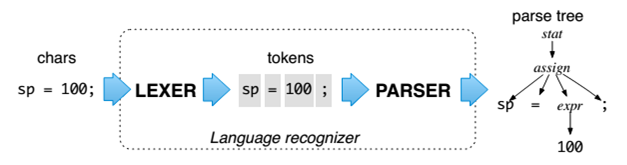
ルールは、さまざまなASTノードを記述するために使用されます。 すべての規則の結合は、言語の文法と呼ばれます。 文法に基づいて言語を解析するための特定のプラットフォーム(ランタイム)用のコードを生成するツールがあります。 これらはパーサージェネレーターと呼ばれます。 たとえば、 ANTLR 、 Bison 、 Coco /R。 ただし、何らかの理由で、たとえばRoslynのように、パーサーは手動で作成されることがよくあります。 手動のアプローチの利点は、パーサーがより効率的で読みやすい傾向があることです。
.NETテクノロジでプロジェクトを開発することが最初に決定されたので、C#コードの分析にRoslynを使用し、他の言語にはANTLRを使用することが決定されました。後者は.NETランタイムをサポートし、他の選択肢は機能が少ないためです。
形式言語の種類
Chomsky階層によると、4種類の形式言語があります。
- 通常の例: a n
- コンテキストフリー(CS、例: a n b n )
- 状況依存(短絡、例: a n b n c n )
- チューリング完全。
正規表現を使用すると、比較のために最も単純な構造のみを記述できますが、日常の練習でほとんどのタスクをカバーします。 正規表現のもう1つの利点は、ほとんどの最新のプログラミング言語でサポートされていることです。 チューリング完全言語は、ライティングと構文解析の両方の複雑さのために実用的ではありません(難解な言語のThueを思い出すことができます)。
現在、最新のプログラミング言語のほぼ全体の構文は、CS文法を使用して記述できます。 KS言語のパーサーと正規表現を「指で」比較すると、後者には記憶がありません。 KZ言語とCS言語のパーサーを比較すると、後者は以前にアクセスしたルールを覚えていません。
さらに、ある場合の言語はCOPであり、別の場合はKZです。 セマンティクス、つまり 言語の定義、特に型の一貫性との整合性、その言語はKZと見なすことができます。 たとえば、 T a = new T ()。 ここで、右側のコンストラクターの型は、左側に示されているものと同じでなければなりません。 通常、解析段階の後にセマンティクスを確認することをお勧めします。 ただし、CS文法を使用して解析できない構文構造があります。たとえば、PHPのHeredocは次のとおりです。$ x = <<< EOL Hello world EOL ; その中で、 EOLトークンは区切り線の始まりと終わりのマーカーであるため、訪問したトークンの値を覚えておく必要があります。 この記事では、このようなKSおよびKZ言語の分析に焦点を当てます。
ANTLR

このパーサージェネレーターはLL(*)であり 、20年以上存在し、2013年に4番目のバージョンがリリースされました。 現在、GitHubで開発中です。 現時点では、Java、C#、Python2、Python3、JavaScriptの言語でパーサーを生成できます。 C ++のアプローチについては、Swift。 このツールでは、文法の開発とデバッグが非常に簡単になりました。 LLLR文法は左再帰規則を許可しないという事実にもかかわらず、バージョン4からANTLRでは、そのような規則を書くことができます(非表示または間接左再帰の規則を除く)。 パーサーが生成されると、そのようなルールは通常の非左再帰ルールに変換されます。 これにより、たとえば算術式の記録が短縮されます。
expr : expr '*' expr | expr '+' expr | <assoc=right> expr '^' expr | id ;
さらに、バージョン4では、Adaptive LL(*)アルゴリズムの使用により、解析パフォーマンスが大幅に向上しています。 このアルゴリズムは、比較的低速で予測不可能なGLLおよびGLRアルゴリズムの利点を組み合わせますが、これらのアルゴリズムはあいまいさ(自然言語解析で使用)を伴うケースを解決でき、標準の高速LL再帰降下アルゴリズムはすべてを解決することはできませんあいまいなタスク。 アルゴリズムの本質は、各ルールでのLLパーサーの擬似並列起動、キャッシュ、および適切な予測の選択です(GLRとは異なり、いくつかの選択肢が許容されます)。 したがって、アルゴリズムは動的です。 アルゴリズムの理論上の最悪の複雑さはO(n 4 )であるという事実にもかかわらず、実際には、既存のプログラミング言語の解析速度は線形です。 また、4番目のバージョンでは、構文エラーを検出した後に解析プロセスを復元する機能が大幅に進化しました。 ANTLR 4アルゴリズムと他の解析アルゴリズムとの違いの詳細については、「 適応LL(*)解析:動的分析の力」を参照してください。
ロズリン

Roslynは単なるパーサーではなく、C#コードを解析、分析、コンパイルするための完全なツールです。 その開発はGitHubでも進行中ですが、ANTLRよりもかなり若いです。 この記事では、セマンティクスに関係なく、構文解析機能についてのみ説明します。 Roslynは、忠実で不変のスレッドセーフツリーでコードを解析します。 信頼性は、構文エラーが含まれている場合でも、そのようなツリーをスペース、コメント、プリプロセッサディレクティブを含む文字から文字へのコードに変換できるという事実にあります。 不変性により、複数のスレッドでツリーを簡単に処理できるようになります。各スレッドは、変更のみが保存されるツリーの「スマート」コピーを作成するためです。 このツリーには、次のオブジェクトが含まれる場合があります。
- 構文ノードは、他のいくつかのノードを含み、特定のデザインを表示する非ターミナルツリーノードです。 また、オプションのノード(ifの場合はElseClauseSyntaxなど)を含めることもできます。
- 構文トークン -キーワード、識別子、リテラル、または句読点を表示するターミナルノード。
- 構文トリビアは、スペース、コメント、またはプリプロセッサディレクティブを表示するターミナルノードです(コードに関する情報を失うことなく簡単に削除できます)。 トリビアは親を持つことができません。 これらのノードは、ツリーを変換してコードに戻す場合(リファクタリングなど)に不可欠です。
解析の問題
文法とパーサーを開発するとき、考慮しなければならないいくつかの問題があります。
識別子としてのキーワード
キーワードを解析するときに識別子になることもよくあります。 たとえば、C#では、 async Method()
シグネチャの前に配置されたasync
キーワードは、メソッドが非同期であることを意味します。 ただし、指定された単語が変数の識別子として使用される場合、 var async = 42;
、コードも有効になります。 ANTLRはこの問題を2つの方法で解決します。
- 構文規則にセマンティック述語を使用:
async: {_input.LT(1).GetText() == "async"}? ID ;
async: {_input.LT(1).GetText() == "async"}? ID ;
; ただし、非同期トークン自体は存在しません。 文法がランタイムに依存し、見苦しいため、このアプローチは不適切です。 - idルール自体にトークンを含めることにより:
ASYNC: 'async'; ... id : ID ... | ASYNC;
あいまいさ
自然言語では、あいまいに解釈されるフレーズがあります(「これらの種類の鉄鋼は私たちのワークショップにあります」など)。 正式な言語では、このような構成も発生する場合があります。 たとえば、次のスニペット:
stat: expr ';' // expression statement | ID '(' ')' ';' // function call statement; ; expr: ID '(' ')' | INT ;
ただし、自然言語とは異なり、それらはおそらく不適切に設計された文法の結果です。 ANTLRは、パーサー生成のプロセスでそのようなあいまいさを検出できませんが、 LL_EXACT_AMBIG_DETECTION
オプションがLL_EXACT_AMBIG_DETECTION
場合、解析プロセスでそれらを直接検出できます(既に述べたように、ALLは動的アルゴリズムであるため)。 あいまいさは、レクサーとパーサーの両方で発生する可能性があります。 2つの同一のトークンのレクサーでは、ファイル内で上記で宣言されたトークンが形成されます(識別子を持つ例)。 ただし、あいまいさが実際に有効な言語(C ++など)では、次のようにセマンティック述語(コード挿入)を使用して解決できます。
expr: { isfunc(ID) }? ID '(' expr ')' // func call with 1 arg | { istype(ID) }? ID '(' expr ')' // ctor-style type cast of expr | INT | void ;
また、文法を少しやり直すことであいまいさを修正できる場合もあります。 たとえば、C#にはビット単位の右シフト演算子RIGHT_SHIFT: '>>'
; 2つの山括弧を使用して、ジェネリッククラスを記述することもできます: List<List<int>>
。 トークン>>
を定義すると、2つのリストの構築は解析できません。これは、パーサーが演算子>>
2つの閉じ括弧の代わりに記述されていると想定するためです。 この問題を解決するには、 RIGHT_SHIFT
トークンを単に拒否するだけで十分です。 同時に、 LEFT_SHIFT: '<<'
トークンLEFT_SHIFT: '<<'
を残すことができます。これは、山括弧を解析する際の文字のシーケンスが有効なコードで見つからないためです。
このモジュールでは、開発された文法にあいまいさがあるかどうかについて、まだ詳細にテストしていません。
スペース、コメントの処理。
解析に関する別の問題はコメント処理です。 ここで不便な点は、文法にコメントを含めると、実際には各ノードにコメントが含まれるため、複雑すぎることが判明することです。 ただし、重要な情報が含まれている可能性があるため、コメントも破棄できません。 ANTLRは、いわゆるチャネルを使用してコメントを処理し、多くのコメントを他のトークンから分離します。 Comment: ~[\r\n?]+ -> channel(PhpComments);
Roslynでは、コメントはツリーノードに含まれますが、特別なタイプの構文トリビアがあります。 ANTLRとRoslynはどちらも、特定の通常のトークンに関連付けられている簡単なトークンのリストを提供します。 ANTLRでは、ストリーム内のインデックスiのトークンに対して、左または右から特定のチャネルからすべてのトークンを返すメソッドがあります: getHiddenTokensToLeft(int tokenIndex, int channel)
、 getHiddenTokensToRight(int tokenIndex, int channel)
。 Roslynでは、そのようなトークンはすぐに端末構文トークンに含まれます。
すべてのコメントを取得するために、ANTLRでは特定のチャネルのすべてのトークンを取得できます: lexer.GetAllTokens().Where(t => t.Channel == PhpComments)
、およびRoslynでは、ルートノードのすべてのDescendantTriviaを次のSyntaxKindで取得できます。 SingleLineCommentTrivia 、 MultiLineCommentTrivia 、 SingleLineDocumentationCommentTrivia 、 MultiLineDocumentationCommentTrivia 、 DocumentationCommentExteriorTrivia 、 XmlComment 。
スペースとコメントを処理することは、LLVMなどのコードを分析に使用できない理由の1つです。スペースとコメントは、単にその中に捨てられます。 コメントに加えて、スペースの処理も重要です。 たとえば、ifの1つのステートメントでエラーを検出するには(例は、FreeBSDカーネルのrummaged記事PVS-Studioから取られています ):
case MOD_UNLOAD: if (via_feature_rng & VIA_HAS_RNG) random_nehemiah_deinit(); random_source_deregister(&random_nehemiah);
解析エラー処理。

各パーサーの重要な機能はエラー処理です-次の理由から:
- 解析プロセスは、1つのエラーだけで中断されるべきではありませんが、正しく復元され、コードをさらに解析する必要があります(たとえば、セミコロンが抜けた後)。
- 多くの無関係なエラーの代わりに、関連するエラーとその場所を検索します。
ANTLRのエラー
ANTLRには、次のタイプの解析エラーがあります。
トークン認識エラー (Lexer no viable alt); 既存のトークンからトークンを生成するためのルールがないことを示す唯一の既存の字句エラー:
クラス# {int i; }-このようなトークンは#です。
トークンがありません( トークンがありません); この場合、ANTLRは不足しているトークンをトークンストリームに挿入し、不足していることをマークし、存在するかのように解析を続行します。
クラスT {int f(x){a = 3 4 5; } } -最後にこのようなトークン}
があります。
追加トークン (外部トークン); ANTLRは、トークンが誤っていることをマークし、存在しないかのようにさらに解析を続けます。この例では、このようなトークンが最初です。
クラスT ; {int i; }
互換性のない入力チェーン (入力の不一致); この場合、「パニックモード」がオンになり、入力トークンチェーンは無視され、パーサーは同期セットからトークンを予期します。 次の例では、トークン4と5は無視され、同期トークンは;です。
クラスT {int f(x){a = 3 4 5 ; }}
- 代替がない (実行可能な代替入力がない); このエラーは、他のすべての解析エラーを説明しています。
クラスT { int; }
さらに、次のようにルールに選択肢を追加することにより、エラーを手動で処理できます。
function_call : ID '(' expr ')' | ID '(' expr ')' ')' {notifyErrorListeners("Too many parentheses");} | ID '(' expr {notifyErrorListeners("Missing closing ')'");} ;
さらに、ANTLR 4は独自のエラー処理メカニズムを使用できます。 これは、たとえば、パーサーのパフォーマンスを向上させるために必要です。最初に、高速SLLアルゴリズムを使用してコードが解析されますが、あいまいさでコードを誤って解析する可能性があります。 このアルゴリズムを使用して、少なくとも1つのエラー(コードのエラーまたはあいまいさのいずれか)があることが判明した場合、コードは完全ではあるがより高速ではないALLアルゴリズムを使用して解析されます。 もちろん、実際のエラー(スキップなど)を含むコードは常にLLを使用して解析されますが、通常、そのようなファイルはエラーのないファイルよりも少なくなります。
// try with simpler/faster SLL(*) parser.getInterpreter().setPredictionMode(PredictionMode.SLL); // we don't want error messages or recovery during first try parser.removeErrorListeners(); parser.setErrorHandler(new BailErrorStrategy()); try { parser.startRule(); // if we get here, there was no syntax error and SLL(*) was enough; // there is no need to try full LL(*) } catch (ParseCancellationException ex) { // thrown by BailErrorStrategy tokens.reset(); // rewind input stream parser.reset(); // back to standard listeners/handlers parser.addErrorListener(ConsoleErrorListener.INSTANCE); parser.setErrorHandler(new DefaultErrorStrategy()); // full now with full LL(*) parser.getInterpreter().setPredictionMode(PredictionMode.LL); parser.startRule(); }
ロズリンのエラー
Roslynには次の解析エラーがあります。
- 構文がありません Roslynは、プロパティ値
IsMissing = true
対応するノードを完成させIsMissing = true
(典型的な例は、セミコロンなしのステートメントです)。 - 不完全なメンバー ; 別の
IncompleteMember
ノードが作成されます。 - 数値、ストリング、または文字リテラルの誤った値 (例えば、大きすぎる値、空の文字):
NumericLiteralToken
、StringLiteralToken
またはCharacterLiteralToken
等しいKindを持つ別個のノード。 - 余分な構文 (たとえば、ランダムに入力された文字):Kind =
SkippedTokensTrivia
で別のノードが作成されます。
次のコードスニペットは、これらのすべてのエラーを示しています
(RoslynはVisual Studio Syntax Visualizerのプラグインでプローブするのにも便利です):
namespace App { class Program { ; // Skipped Trivia static void Main(string[] args) { a // Missing ';' ulong ul = 1lu; // Incorrect Numeric string s = """; // Incorrect String char c = ''; // Incorrect Char } } class bControl flow { c // Incomplete Member } }
よく考え抜かれたこれらのタイプの構文エラーのおかげで、Roslynは任意の数のエラーのあるツリーを文字ごとにコードに戻すことができます。
理論から実践へ

PHPの場合、上記の理論を視覚的に応用したT-SQLパーサー、 php 、 tsql 、 plsql grammarが開発され、オープンソースでレイアウトされました。 Java解析では、既製のjavaおよびjava8の文法が使用され、比較されました。 また、RoslynとANTLRに基づいたパーサーを比較するために、言語のバージョン5と6をサポートするようにC#文法を変更しました。 これらの文法の開発と使用における興味深い点を以下に説明します。 SQLベースの言語は命令型よりも宣言型ですが、T-SQLの方言であるPL / SQLには命令型構文( 制御フロー )のサポートがあり、その大部分はアナライザーが開発しています。
JavaおよびJava8の文法
ほとんどの場合、Java 7文法に基づくパーサーは、Java 8よりも高速にコードを解析します。例外は、たとえば、 ManyStringConcatenation.javaファイルでの深い再帰の場合を除きます。 これは単なる合成例ではなく、類似の「スパゲッティコード」を持つファイルに実際に遭遇したことに注意してください。 判明したように、問題全体はまさに式の左の再帰規則によるものです。 Java 8の文法には、プリミティブな再帰を伴うルールのみが含まれています。 原始再帰のルールは、通常のルールとは異なり、代替の左または右の部分でのみ参照され、両方で同時に参照されることはありません。 正規の再帰式の例:
expression : expression ('*'|'/') expression | expression ('+'|'-') expression | ID ;
また、上記のルールをプリミティブな左再帰ルールに変換すると、次のルールが取得されます。
expression : multExpression | expression ('+'|'-') multExpression ; multExpression : ID | multExpression ('*'|'/') ID ;
または、非再帰的です(ただし、この場合、解析後の式はバイナリでなくなるため、処理があまり便利ではありません)。
expression : multExpression (('+'|'-') multExpression)* ;
操作に正しい連想性(指数など)がある場合、プリミティブな右再帰規則が使用されます。
expression : <assoc=right> expression '^' expression | ID ;
powExpression : ID '^' powExpression | ID ;
一方では、左利きのルールを変換することで、多数の同種の操作があるめったに出会わないファイルの高メモリ消費と低パフォーマンスの問題を排除し、他方では、多くのファイルの残りのパフォーマンスの問題を引き起こします。 したがって、潜在的に非常に深くなる可能性がある式(たとえば、文字列の連結)にはプリミティブな再帰を使用し、他のすべての場合(たとえば、数値の比較)には通常の再帰を使用することをお勧めします。
PHP文法
.NETプラットフォームでPHPを解析するためのPhalangerプロジェクトがあります。 ただし、このプロジェクトが実際に開発されておらず、ASTノードをトラバースするための訪問者インターフェイスも提供していないという事実に不安を感じました(Walkerのみ)。 したがって、ANTLRの下でPHP文法を独自に開発することが決定されました。
大文字と小文字を区別しないキーワード。
ご存知のように、PHPでは、変数名(「$」で始まる)を除くすべてのトークンは大文字と小文字が区別されません。 ANTLRの場合、大文字と小文字を区別しない方法は2つの方法で実装できます。
すべてのラテン文字の断片的な字句規則を宣言し、それらを次の方法で使用します。
Abstract: ABSTRACT; Array: ARRAY; As: AS; BinaryCast: BINARY; BoolType: BOOLEAN | BOOL; BooleanConstant: TRUE | FALSE; ... fragment A: [aA]; fragment B: [bB]; ... fragment Z: [zZ];
ANTLRのスニペットは、他のトークンで使用できるトークンの一部であり、
ただし、それ自体はトークンではありません。 トークンを記述するための基本的な構文糖衣です。 たとえば、フラグメントを使用しない場合、最初のトークンは次のように記述できます。Abstract: [Aa] [Bb] [Ss] [Tt] [Rr] [Aa] [Cc] [Tt]
。 このアプローチの利点は、生成されたレクサーがランタイムに依存しないことです。これは、大文字と小文字が文法ですぐに宣言されるためです。 マイナスのうち、このアプローチを使用したレクサーのパフォーマンスは、2番目の方法よりも低いことに注意してください。
- 文字の入力ストリーム全体を下位(または上位)レジスタに移動し、レクサーを開始します。レクサーでは、このレジスタにすべてのトークンが記述されます。 ただし、 カスタムファイルまたはストリングストリームの実装とLAのオーバーライドで説明されているように、このような変換はランタイム(Java、C#、JavaScript、Python)ごとに個別に行う必要があります。 さらに、このアプローチでは、一部のトークンが大文字と小文字を区別し、他のトークンがそうでないことを確認することは困難です。
開発されたPHP文法では、通常、構文解析よりも短時間で字句解析が実行されるため、最初のアプローチが使用されました。 とにかく、文法がランタイムに依存していることが判明したという事実にもかかわらず、このアプローチは、文法を他のランタイムに移植するタスクを潜在的に単純化します。 さらに、大文字と小文字を区別しないトークンの説明を容易にするために、プルリクエストRFC大文字と小文字を区別しない概念実証を作成しました。 しかし、残念ながら、彼はANTLRコミュニティからあまり承認を受けていませんでした。
PHP、HTML、CSS、JavaScriptの字句モード。
ご存じのように、PHPコードの挿入は、ほぼどこでもHTMLコード内に配置できます。 CSSおよびJavaScriptコードの挿入もこのHTMLに配置できます(これらの挿入は「アイランド」とも呼ばれます)。 たとえば、次のコード( 代替構文を使用)は有効です。
<?php switch($a): case 1: // without semicolon?> <br> <?php break ?> <?php case 2: ?> <br> <?php break;?> <?php case 3: ?> <br> <?php break;?> <?php endswitch; ?>
または
<script type="text/javascript"> document.addEvent('domready', function() { var timers = { timer: <?=$timer?> }; var timer = TimeTic.periodical(1000, timers); functionOne(<?php echo implode(', ', $arrayWithVars); ?>); }); </script>
幸いなことに、ANTLRには、いわゆるモードのメカニズムがあり、特定の条件下でトークンの異なるセットを切り替えることができます。 たとえば、 SCRIPTモードとSTYLEモードは、それぞれJavaScriptとCSSのトークンのストリームを生成するように設計されています(ただし、この文法では、実際には単に無視されます)。 デフォルトモードでは、 DEFAULT_MODE HTMLトークンが生成されます。 ターゲットコードをレクサーに挿入することなく、ANTLRで代替構文のサポートを実装できることに注意してください。 つまり、 nonEmptyStatementにはinlineHtmlルールが含まれ、これにはDEFAULT_MODEモードで受信したトークンが含まれます。
nonEmptyStatement : identifier ':' | blockStatement | ifStatement | ... | inlineHtml ; ... inlineHtml : HtmlComment* ((HtmlDtd | htmlElement) HtmlComment*)+ ;
複雑な状況依存構造。
ANTLRはKS文法のみをサポートしますが、いわゆるアクション、つまり、許容される言語のセットを少なくとも状況依存に拡張する任意のコードの挿入があることに注意してください。 このような挿入の助けを借りて、 Heredocなどの構造の処理が実装されました。
<?php foo(<<< HEREDOC Heredoc line 1. Heredoc line 2. HEREDOC ) ; ?>
T-SQLの文法
「SQL」の共通のルートにもかかわらず、T-SQL文法(MSSQL)とPL / SQLは互いにかなり異なります。
この困難な言語用に独自のパーサーを開発しないことを嬉しく思います。 ただし、既存のパーサーは、完全性、関連性(放棄されたGOLDパーサーの文法 )、およびC#のオープンソース( 一般的なSQLパーサー )の基準を満たしていませんでした。 TSQL MSDN. : , , ( SQL- MSDN). , . , . , - .
PL/SQL
PL/SQL , ANTLR3 . , java-runtime. java , AST ( , ). ,
decimal_key : {input.LT(1).getText().equalsIgnoreCase("decimal")}? REGULAR_ID
:
decimal_key: DECIMAL
, .
C#-
, , 5 6 , . . -, runtime.
C# ( , , . . false ):
#if DEBUG && false Sample not compilied wrong code var 42 = a + ; #else // Compilied code var x = a + b; #endif
, -, COMMENTS_CHANNEL DIRECTIVE . codeTokens
, . . , ANTLR . — CSharpPreprocessorParser.g4 . true
false
#if
, #elif
, else
, true
, , . Conditional Symbols ( "DEBUG").
true
, codeTokens
, — . ( var 42 = a + ;
) . : CSharpAntlrParser.cs .
文字列補間
, , , (interpolation-expression), . , (, #0.##). , (regular), (verbatium), . MSDN .
, :
s = $"{p.Name} is \"{p.Age} year{(p.Age == 1 ? "" : "s")} old"; s = $"{(p.Age == 2 ? $"{new Person { } }" : "")}"; s = $@"\{p.Name} ""\"; s = $"Color [ R={func(b: 3):#0.##}, G={G:#0.##}, B={B:#0.##}, A={A:#0.##} ]";
, . CSharpLexer.g4 .
テスト中
ANTLR
Roslyn, , . ANTLR :
- , . , TSQL antlr grammars-v4 . C# AllInOne.cs , Roslyn.
- .
- . PHP WebGoat , phpbb , Zend Framework . C# Roslyn-1.1.1 , Corefx-1.0.0-rc2 , ImageProcessor-2.3.0 , Newtonsoft.Json-8.0.2 .
ANTLR Roslyn
Release . ANTLR 4 4.5.0-alpha003 Roslyn (Microsoft.CodeAnalysis) 1.1.1.
WebGoat.PHP
— 885. — 137 248, — 4 461 768.
— 00:00:31 ( 55%, 45%).
PL/SQL Samples
— 175. — 1 909, — 55 741.
< 1 . ( 5%, 95%).
CoreFX-1.0.0-rc2
— 7329. — 2 286 274, — 91 132 116.
:
- Roslyn: 00:00:04 .,
- ANTLR: 00:00:24 . ( 12%; 88%).
Roslyn-1.1.1
— 6527. — 1 967 672, — 74 319 082.
:
- Roslyn: 00:00:03 .,
- ANTLR: 00:00:16 . ( 12%; 88%).
CoreFX Roslyn , C# ANTLR 5 Roslyn, . , « » , Roslyn, C#- Java, Python JavaScript ( ), .
, , . PHP, , . , , T-SQL PL/SQL ( ) ( 20). , C# SHARP: NEW_LINE Whitespace* '#';
SHARP: '#';
, 7 , 10 ! , , #, ( , ).
ANTLR Roslyn
C#-, ANTLR:
namespace App { class Program { static void Main(string[] args) { a = 3 4 5; } } class B { c }
ANTLR
- token recognition error at: '' at 3:5
- mismatched input '4' expecting {'as', 'is', '[', '(', '.', ';', '+', '-', '*', '/', '%', '&', '|', '^', '<', '>', '?', '??', '++', '--', '&&', '||', '->', '==', '!=', '<=', '>=', '<<'} at 8:19
- extraneous input '5' expecting {'as', 'is', '[', '(', '.', ';', '+', '-', '*', '/', '%', '&', '|', '^', '<', '>', '?', '??', '++', '--', '&&', '||', '->', '==', '!=', '<=', '>=', '<<'} at 8:21
- no viable alternative at input 'c}' at 15:5
- missing '}' at 'EOF' at 15:6
Roslyn
- test(3,5): error CS1056: Unexpected character ''
- test(8,19): error CS1002:; expected
- test(8,21): error CS1002:; expected
- test(15,5): error CS1519: Invalid token '}' in class, struct, or interface member declaration
- test(15,6): error CS1513: } expected
, Roslyn , ANTLR. . . , Roslyn , . , ( , ), ANTLR . ANTLR , ( , ). , #if
, . ( - ).
, ANTLR 4 , , . ( 70000 PHP ) , . lexer.Interpreter.ClearDFA()
parser.Interpreter.ClearDFA()
.
, . , GetAllTokens()
ClearDFA()
( ) "Object reference not set to an instance of an object". , ANTLR C#, ( ) ( ) ReadWriterLockSlim
.
Roslyn . 5 C# aspnet-mvc-6.0.0-rc1 , roslyn-1.1.1 , corefx , Newtonsoft.Json-8.0.2 ImageProcessor-2.3.0 200 .
おわりに
ANTLR Roslyn. 次の記事で教えてくれます:
- AST Visitor Walker (Listener);
- , ANTLR 4;
- .NET;
- AST;
- DSL .
VladimirKochetkov « SAST» 40 60 .
ソース
- Modeling and Discovering Vulnerabilities with Code Property Graphs; Fabian Yamaguchi; 2014.
- Compilers: Principles, Techniques, and Tools; Alfred V. Aho, Monica S. Lam, Ravi Sethi, and Jeffrey D. Ullman; 2006.
- The Definitive ANTLR Reference; Terence Parr; 2014.
- Adaptive LL(*) Parsing: The Power of Dynamic Analysis, Terence Parr; Sam Harwell; 2014.
- Roslyn code & docs, https://github.com/dotnet/roslyn
- ANTLR grammars, https://github.com/antlr/grammars-v4
- ANTLR code, https://github.com/antlr/antlr4