GPUを使用した人は誰でも、クエリプーリング、銀行の競合、およびその対処方法を知っています。それが機能しなかった場合は、CUDAプログラミングの基礎に関する有用な記事を見つけることができます[1] 。 GTX8800カードは、ある意味では良いものであり、CUDAの最初のバージョンであり、最初のバージョンのみをサポートしていたため、銀行の競合がある場合、またはグローバルメモリへのリクエストが結合されていない場合に明らかに見える回。 これはすべて、カードを操作するすべてのルールをよりよく理解し、通常のコードを書くのに役立ちました。
新しいモデルはますます多くの機能を追加しており、開発を容易にし、スピードアップしています。 アトミック操作、キャッシュ、動的並行性などが登場しました。
投稿では、時空間画像フィルタリングとコンピューティング機能= 1.0の実装、および新しい機能で結果を高速化する方法について説明します。
一時的なフィルタリングは、衛星を観測する場合や、正確なバックグラウンド抑制が必要なその他のフィルタリング状況で役立ちます。

理論のビット
彼はできる限り縮小しましたが、最も重要なものは残しました。 したがって、一連のフレームが入力されます。 各フレームは、マトリックスのノイズ、背景、および有用な信号の合計として表すことができます。
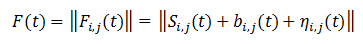
いくつかの以前のフレームを使用して、新しく到着したフレームを白くし、存在する場合は信号を選択できます。 これを行うには、前のフレームの実装に従って、このフレームの背景を予測し、その推定値を取得する必要があります。 履歴内のフレームの数をNとすると、バックグラウンド推定値は、いくつかの重みを持つフレームの合計として表すことができます。
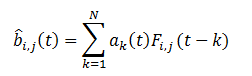
品質基準は、フレームと予測される背景の差であり、最小化する必要があります。
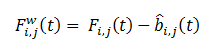
ソリューションの形式は次のとおりです。
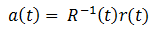
サンプル相関行列は次のように計算されます。
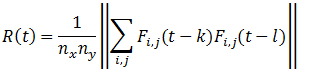
右側のベクトルの形式は次のとおりです。
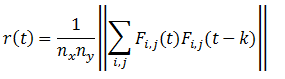
ここで、k、l-は1からNまで変化します。
ただし、この方法ではフレームシフトは考慮されません。 係数を想像するなら
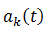 明示的なシフト関数として
明示的なシフト関数として 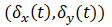 いくつかの参照フレームに関連して、品質基準を定式化し、ソリューションを書き出すことができます。 たくさんの式があるはずですが、結果として シフトのみに依存します。
いくつかの参照フレームに関連して、品質基準を定式化し、ソリューションを書き出すことができます。 たくさんの式があるはずですが、結果として シフトのみに依存します。
シフトは、いくつかの参照フレームに対して計算されます。
 次の式に従って:
次の式に従って:
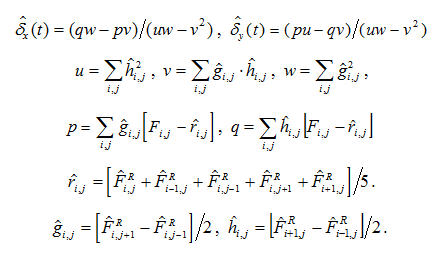
参照フレームに対するフレームシフトがわかっているので、次の式に従って係数ベクトルa(t)を計算します。
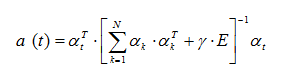
ここで、αは次数nの多項式の係数ベクトル、γは十分に小さい量、Eは単位行列です。
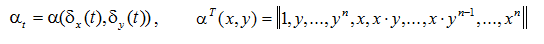
GPUの実装
2番目のフィルタリング方法の実装を検討してください。 GPUでは、フレームを白くする機能とフレームオフセットを見つける機能を転送することが有利です。 既知のシフトによるホワイトニングの係数を計算する機能は、時間がかからず、タスクが小さすぎます。
すぐにこれが私が書いた最初のプロジェクトの1つであることを予約します。そのため、コードは完璧であると主張していません。
最初に、一連のフレームをビデオカードのメモリにスローする必要があります。 これを行うには、GPUメモリへのポインターを持つ配列を選択し、GPUメモリにもコピーします。
float **h_array_list, **d_array_list; h_array_list = ( float** )malloc( num_arrays * sizeof( float* )); cudaMalloc((void**)&d_array_list, num_arrays * sizeof( float * )); for ( int i = 0; i < num_arrays; i++ ) cudaMalloc((void**)&h_array_list[i], data_size); cudaMemcpy( d_array_list, h_array_list, num_arrays * sizeof(float*), cudaMemcpyHostToDevice );
このような組織では、わずかな欠陥があります。 次のようにフレームから読み取る場合
int bx = blockIdx.x; int by = blockIdx.y; int tx = threadIdx.x; int ty = threadIdx.y; int aBegin = nx * BLOCK_SIZE * by + BLOCK_SIZE * bx; float a = inFrame[ j ][ aBegin + nx * ty + tx]
そのような読み取りを備えた以前のバージョンの計算機能では、グローバルメモリへの要求は結合されませんでした。
これはキャッシュになり、フレームへのポインタがキャッシュに格納され、すぐに読み取られます。 クエリを結合するためのルールを満たすには、まずこれらのポインタを共有メモリにロードする(これにも時間がかかります)か、次のようにする必要があります。
float **h_array_list, **d_array_list; h_array_list = ( float** )malloc( 16 * num_arrays * sizeof( float* ) ); cudaMalloc((void**)&d_array_list, 16 * num_arrays * sizeof(float *)); for ( int i = 0; i < num_arrays; i++ ) { cudaMalloc((void**)&h_array_list[i*16], data_size); for( int j = 1; j < 16; j++ ) h_array_list[ i*16 + j ] = h_array_list[ i*16 ]; } cudaMemcpy( d_array_list, h_array_list, 16*num_arrays * sizeof(float*), cudaMemcpyHostToDevice );
この場合、読み取り要求が結合され、速度が著しく向上することがわかります。
GPUのホワイトニングフレームの機能は次のようになります。
__global__ void kernelWhite( float * out, float ** inFrame, float *at, int nx, int mem ) { int bx = blockIdx.x; int by = blockIdx.y; int tx = threadIdx.x; int ty = threadIdx.y; int aBegin = nx * BLOCK_SIZE * by + BLOCK_SIZE * bx; __shared__ float frame1 [BLOCK_SIZE][BLOCK_SIZE]; __shared__ float a [32]; int i = ty * BLOCK_SIZE + tx; // if( i < mem ) a[ i ] = at[ i ]; __syncthreads (); frame1 [ty][tx] = 0; // for( int j = 0; j < mem; j++ ) { frame1 [ty][tx] += a[ j ]*inFrame[ j*16 + tx ][ aBegin + nx * ty + tx]; } // out [ aBegin + nx * ty + tx ] = inFrame[ mem*16 + tx ][ aBegin + nx * ty + tx] - frame1 [ty][tx]; }
一般に、ここではすべてが簡単です。フレームをホワイトニングした結果の共有メモリを作成し、係数ベクトルをロードし、フローを同期してから、これらの係数でフレームを循環させます。 ここでは、フローの正方形ブロックではなく、線形ブロックを選択することもできます。これは、インデックス作成の計算数を減らすため、一般にさらに正確です。
シフト検索機能では、標準の最適化アルゴリズムを使用して配列の合計を検索しました[2] 。 この関数では、最初に係数rij、gij、hijを見つけてから、上記の式を使用して合計を計算する必要があります。
__global__ void kernelShift(float * inFrameR、float * inFrame、float * outData、int nx)
__global__ void kernelShift ( float *inFrameR, float *inFrame, float *outData, int nx ) { int bx = blockIdx.x; int by = blockIdx.y; int tx = threadIdx.x; int ty = threadIdx.y; int aBegin = nx * BLOCK_SIZE * by + BLOCK_SIZE * bx; // __shared__ float rij [BLOCK_SIZE*BLOCK_SIZE]; __shared__ float gij [BLOCK_SIZE*BLOCK_SIZE]; __shared__ float hij [BLOCK_SIZE*BLOCK_SIZE]; __shared__ float tmp [BLOCK_SIZE*BLOCK_SIZE]; __shared__ float p [BLOCK_SIZE*BLOCK_SIZE]; __shared__ float q [BLOCK_SIZE*BLOCK_SIZE]; __shared__ float frame1 [BLOCK_SIZE][BLOCK_SIZE]; // shared memeory frame1 [ty][tx] = inFrameR [ aBegin + nx * ty + tx]; // __syncthreads (); int i = ty * BLOCK_SIZE + tx; // gij, hij, rij 1414. if( tx > 0 && > 0 && tx < BLOCK_SIZEm1 && ty < BLOCK_SIZEm1 ) { gij[ i ] = ( frame1[ty + 1][tx] - frame1[ty - 1][tx] )/2.0; hij[ i ] = ( frame1[ty][tx + 1] - frame1[ty][tx - 1] )/2.0; rij[ i ] = ( frame1[ty][tx] + frame1[ty][tx + 1] + frame1[ty][tx - 1] + frame1[ty + 1][tx] + frame1[ty - 1][tx] )/5.0; } else { gij[ i ] = 0; hij[ i ] = 0; rij[ i ] = 0; } // __syncthreads (); // shared memeory frame1 [ty][tx] = inFrame [ aBegin + nx * ty + tx] - rij[i]; // p, q p [i] = gij [i]*frame1 [ty][tx]; q [i] = hij [i]*frame1 [ty][tx]; // u tmp [i] = hij [i]*hij [i]; // v rij[i] = hij [i]*gij [i]; // w hij [i] = gij [i]*gij [i]; __syncthreads (); for ( int s = BLOCK_SIZEhalfqrt; s > 32; s >>= 1 ) { if ( i < s ) { p [i] += p [i + s]; q [i] += q [i + s]; tmp [i] += tmp [i + s]; rij [i] += rij [i + s]; hij [i] += hij [i + s]; } __syncthreads (); } if ( i < 32 ) { p [i] += p [i + 32]; p [i] += p [i + 16]; p [i] += p [i + 8]; p [i] += p [i + 4]; p [i] += p [i + 2]; p [i] += p [i + 1]; q [i] += q [i + 32]; q [i] += q [i + 16]; q [i] += q [i + 8]; q [i] += q [i + 4]; q [i] += q [i + 2]; q [i] += q [i + 1]; tmp [i] += tmp [i + 32]; tmp [i] += tmp [i + 16]; tmp [i] += tmp [i + 8]; tmp [i] += tmp [i + 4]; tmp [i] += tmp [i + 2]; tmp [i] += tmp [i + 1]; rij [i] += rij [i + 32]; rij [i] += rij [i + 16]; rij [i] += rij [i + 8]; rij [i] += rij [i + 4]; rij [i] += rij [i + 2]; rij [i] += rij [i + 1]; hij [i] += hij [i + 32]; hij [i] += hij [i + 16]; hij [i] += hij [i + 8]; hij [i] += hij [i + 4]; hij [i] += hij [i + 2]; hij [i] += hij [i + 1]; } if ( i == 0 ) { outData [ by*gridDim.x + bx ] = p[0]; outData [ by*gridDim.x + bx + gridDim.x*gridDim.y] = q[0]; outData [ by*gridDim.x + bx + 2*gridDim.x*gridDim.y] = tmp [0]; outData [ by*gridDim.x + bx + 3*gridDim.x*gridDim.y] = rij [0]; outData [ by*gridDim.x + bx + 4*gridDim.x*gridDim.y] = hij [0]; } };
最後に、すべてのブロックの結果を合計する必要があります。 ブロックの数はそれほど多くないので、プロセッサですでに結果を取得する方がより有益です。 シフトはフレームごとに独立して計算されるため、フィルターメモリフレームにインデックスを付けるためにストリームテーブルに別のディメンションを追加することにより、1つのコアがすべてのフレームのシフトを考慮する実装を考え出すことができます。 ただし、これはフレームが小さい場合に役立ちます。
// . int numbCoeff = regInfo->nx / threads.x*regInfo->nx / threads.y; cudaMemcpy( coeffhost, coeffdev, numbCoeff*5* sizeof ( float ), cudaMemcpyDeviceToHost ); float q = 0, p = 0; float u = 0, v = 0, w = 0; for( int i = 0; i < numbCoeff; i++ ) { p += coeffhost[ i ]; q += coeffhost[ i + numbCoeff]; u += coeffhost[ i + 2*numbCoeff]; v += coeffhost[ i + 3*numbCoeff]; w += coeffhost[ i + 4*numbCoeff]; } dx = ( q * w - p * v )/( u * w - v * v ); dy = ( p * u - q * v )/( u * w - v * v );
ここでの主な欠点は何ですか。
1.プロセッサで得られる最終結果。
2.参照フレームrij、gij、hijの係数は、各フレームで繰り返し計算されます。
プロファイラーで結果を見て、この実装がうまく機能するかどうかを評価しましょう。 プロファイラーは、読み取り要求が結合されており、ほとんどの場合、指示がかかることを通知します。
オフセット検索カーネル:
フレームをホワイトニングするためのカーネル:
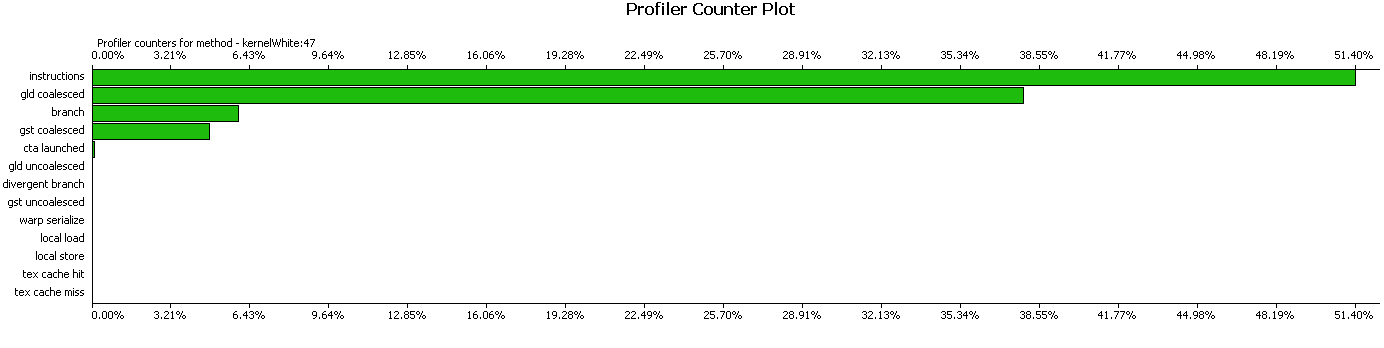
稼働時間と最適化
古いGTX8800は別のコンピューターにあり、既にどこかに行っていたので、GTX Titanの結果を示します。
サイズが512x512のフレームの場合、次の作業時間の結果が得られました。 せん断係数を計算するためのコアには60μsかかります。 係数のコピーと最終合計を追加すると、130μsになります。 20フレームのメモリでは、動作時間はそれぞれ2.6 msです。 フレームのホワイトニング機能には156μsかかります。 プロセッサ上の係数を計算する機能もあり、これはさらに50μsです。 合計で2.806ミリ秒が取得されます。
したがって、CPUでは、シフトの計算に40ミリ秒、フレームのホワイトニングに30ミリ秒、係数の計算にさらに50μsかかります。 合計で70ミリ秒になります。これはGPUの25倍の速度です(実際、これはそうではありませんが、後で詳しく説明します)。
実装は非常にシンプルで、SS = 1.0と互換性があります。 修正できるものを見てみましょう。 シフトの検索における最後のアクションは、アトミック操作を介して変更および実装できます。これは、数倍速く動作します。
変更されたコードは次のようになります。
// if ( i == 0 ) { atomicAdd( &outData[0], p[0] ); atomicAdd( &outData[1], q[0] ); atomicAdd( &outData[2], tmp[0] ); atomicAdd( &outData[3], rij[0] ); atomicAdd( &outData[4], hij[0] ); } // CPU float p = coeffhost[ 0 ]; float q = coeffhost[ 1 ]; float u = coeffhost[ 2 ]; float v = coeffhost[ 3 ]; float w = coeffhost[ 4 ]; dx = ( q * w - p * v )/( u * w - v * v ); dy = ( p * u - q * v )/( u * w - v * v );
この場合、カーネルはほぼ同じ時間、66μsかかります。
個別のカーネルを作成してそれらを計算することにより、複数の再カウントrij、gij、hijを取り除くことができますが、毎回それらをロードする必要があり、1つの参照フレームをロードする代わりに、係数を持つ3つのフレームをロードする必要があるため、これは3倍のメモリです 最適な解決策は、コア内のフレームをループすることにより、すべてのシフトを一度に計算するために1つのコアを作成することです。
より一般的なタスクがあり、それを行うことはできませんが、カーネルを複数回起動する必要があるとします。 この時点で、すべてが正常であり、カーネルは一般的に最適に記述され、加速は最大25倍であると考えるかもしれませんが、プロファイラーを見ると、次の図が表示されます。
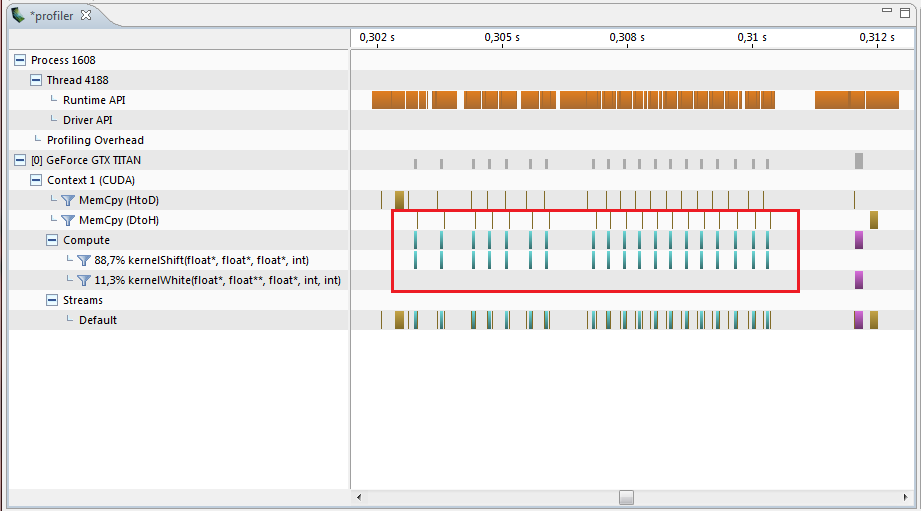
GPUでの機能はごく短時間しか機能せず、残りは遅延、メモリのコピー、その他の中間操作です。 合計で11.5ミリ秒が実行され、すべてのフレームのシフトが計算されます。 その結果、加速度はCPUに対してわずか6倍でした。 すべての中間計算を削除し、カーネルをループで次々に実行します。
for( int j = 0; j < regressInfo->memory - 1; j++ ) kernelShift<<< SKblocks, SKthreads >>> ( … );
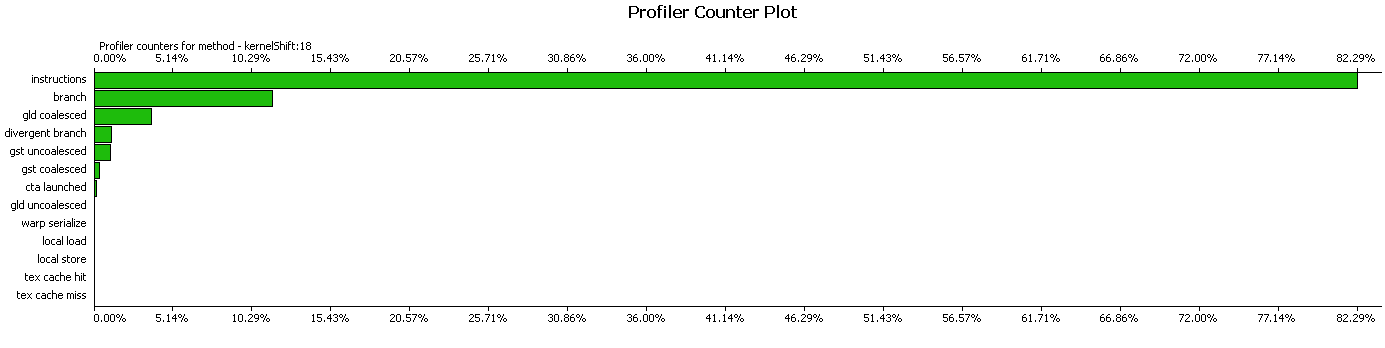
最適化後、プロファイラーはまったく異なる画像を表示します。
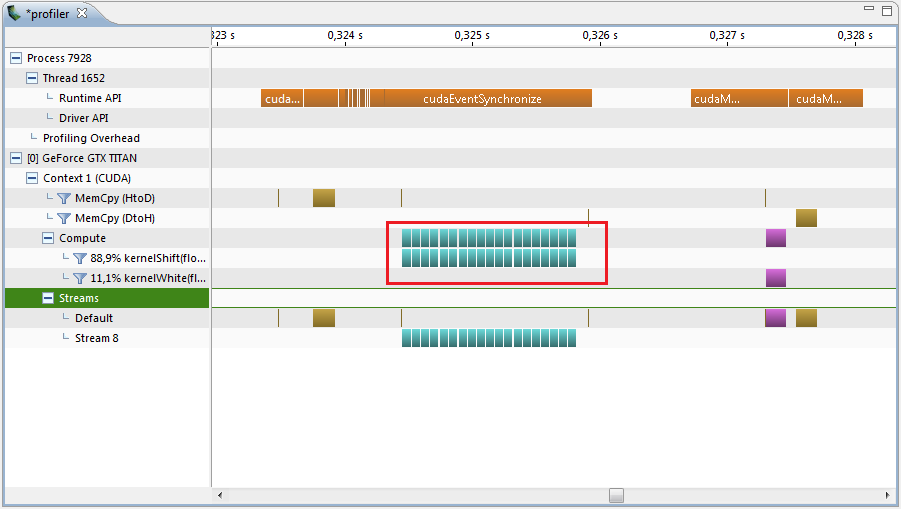
より良いことが起こりましたよね?..シフトの計算を行う部分は、11.5ミリ秒ではなく1.40ミリ秒かかります。 4μsに等しいコア間に小さな間隔が残っており、プロファイラーが生成されます。 そして、異なるスレッドでカーネルを実行してみましょう。
// stream for( int it = 0; it < 4; it++ ) cudaStreamCreate( &streamTX[it] ); …… for( int j = 0; j < regressInfo->memory - 1; j++ ) kernelShift<<< SKblocks, SKthreads, 0, streamTX[j%4] >>> (…);
プロファイラーはそのような結果を表示し、ここでは間隔は1.22 msです。
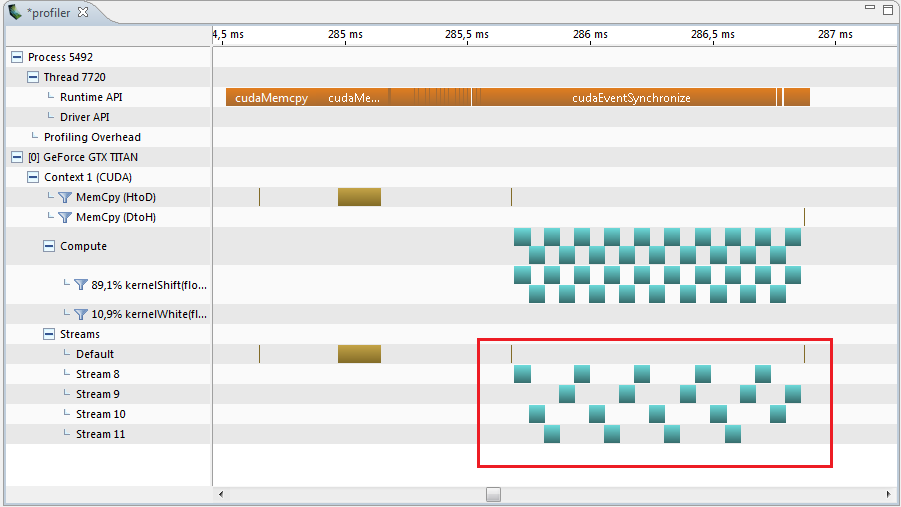
そして、これは0.066 * 20 = 1.320よりも0.12 ms小さくなっています。
プロセッサの負荷は84%です。
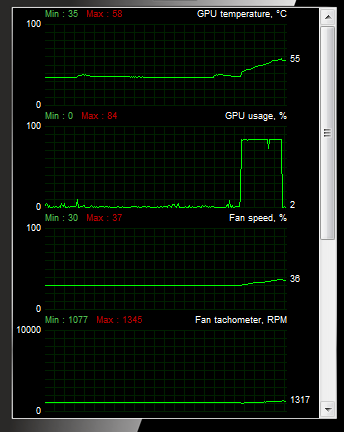
その結果、合計時間は1.22ms + 50μs+ 156μs= 1.426 msとなり、CPUの50倍の速度になります。
もちろん、シフトを計算するために1つのコアを記述する方が正しいでしょうが、これは異なる最適化パスであり、過小評価できないより一般的な方法を検討しました。 GPUで適切な実装を作成できますが、GPUとの相互作用を最適化することは忘れてください。 カーネルにかかる時間が短いほど、CPUに何らかのアクションがある呼び出し間の間隔が大きくなります。
結果をフィルタリングする
たとえば、星空の写真が撮影され、動く薄暗い物体、小さな振動、固有のノイズがそれらに追加されました。
処理する前に:

処理後:

処理する前に:

処理後:

アルゴリズムに加えて、以前のフレームからオブジェクトを削除する機能を追加することもできます。これは、フィルタリング結果を大きく損ない、痕跡を残す可能性があるためです。
残念ながら、実際の記録を取得することはできませんでしたが、それができて読者が興味を持つ場合は、結果について書きます。
PS広角カメラから4GB 10Mpixフレームを見つけました。 私はそれを処理しようとします。
1. CUDAでメモリを操作します。
2. CUDAで金額を計算するアルゴリズム。