前戯
今日は、VMWare vSphereクラスターのニーズを満たすために、2台のLinuxベースのサーバーから予算フェイルセーフiSCSIストレージを作成した方法を説明します。 同様の記事( たとえば )がありましたが、私のアプローチは多少異なり、そこで使用されているソリューション(同じハートビートとiscsitarget)はすでに古くなっています。
この記事は、「カーネルをパッチしてコンパイルする」というフレーズを恐れない経験豊富な管理者を対象としていますが、一部の部分はコンパイルせずに単純化して省くことができますが、自分でどのように書くかを説明します。 素材を膨張させないために、いくつかの簡単なことをスキップします。 この記事の目的は、すべてを段階的に概説するのではなく、一般的な原則を示すことです。
入門
私の要件は単純でした。単一障害点のない仮想マシン用のクラスターを作成しました。 また、ボーナスとして、ストレージはデータを暗号化できる必要があり、サーバーをドラッグした敵が彼らに届かないようにしました。
VSphereは、最も確立された完成品としてハイパーバイザーとして選択され、iSCSIは、FCまたはFCoEスイッチの形で追加の金融注入を必要としないため、プロトコルとして選択されました。 オープンソースのSASターゲットでは、それは悪くないにしてもかなりきついので、このオプションも拒否されました。
ストレージは残ります。 主要ベンダーのさまざまなブランドソリューションは、自社と同期レプリケーションのライセンスの両方のコストが高いために破棄されました。 したがって、私たちは自分でそれを行うと同時に、学習します。
ソフトウェアが選択されたとき:
- Debian Wheezy + LTS Core 3.10
- iSCSI ターゲットSCST
- レプリケーション用のDRBD
- クラスタリソースの管理と監視のためのPacemaker
- 暗号化のためのDM-Cryptコアサブシステム(プロセッサ内のAES-NI命令は非常に役立ちます)
その結果、短い苦痛の中で、そのような単純なスキームが生まれました。
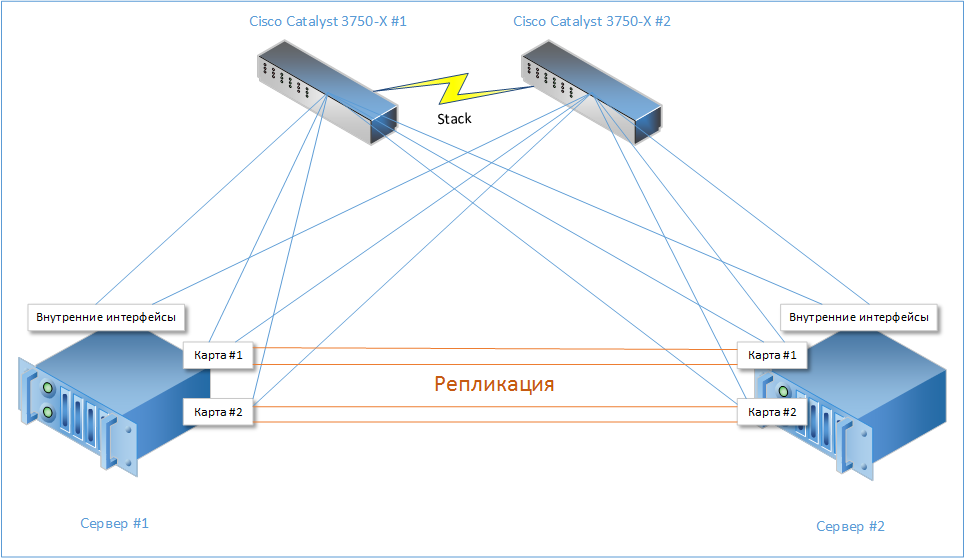
各サーバーに10ギガビットインターフェース(2つの組み込みと4つの追加ネットワークカード)があることを示しています。 それらのうち6つはスイッチスタックに接続され(それぞれ3つ)、残りの4つは隣接サーバーに接続されます。
また、DRBDを介したレプリケーションも行われます。 レプリケーションカードは、必要に応じて10 Gbpsに置き換えることができますが、手元に持っていたので、「それが何であるかを盲目にしました」。
したがって、いずれかのカードが突然死亡しても、どのサブシステムも完全に機能しなくなることはありません。
これらのストレージの主なタスクは、大容量データ(ファイルサーバー、メールアーカイブなど)の信頼できるストレージであるため、3.5インチディスクのサーバーを選択しました。
- 16台の3.5インチドライブ用Supermicro SC836E26-R1200エンクロージャ
- Supermicro X9SRi-Fマザーボード
- IntelプロセッサーE5-2620
- 4 x 8GB DDR3 ECCメモリ
- 緊急フラッシュキャッシュフラッシュ用のスーパーキャパシタを備えたLSI 9271-8i RAIDコントローラ
- 16 Seagate Constellation ES.3 3Tb SASドライブ
- 2 x 4ポートIntelイーサネットI350-T4ネットワークカード
ビジネス向け
ディスク
各サーバーに8つのディスクの2つのRAID10アレイを作成しました。
以来RAID6を拒否することを決定 十分なスペースがあり、ランダムアクセスタスクでのRAID10のパフォーマンスが向上しています。 さらに、この場合の再構築時間と負荷を下回るのは1つのディスクのみであり、アレイ全体ではありません。
一般的に、ここでは誰もが自分で決定します。
ネットワーク部
iSCSIプロトコルでは、ボンディング/イーサチャネルを使用して速度を上げることは意味がありません。
理由は簡単です-同時に、ハッシュ関数を使用してチャネルを介してパケットを配布するため、そのようなIP / MACアドレスを選択してIP1からIP2へのパケットが1つのチャネルを通過し、IP1からIP3を別のチャネルへ通過させることは非常に困難です。
ciscoには、パケットがどのEtherchannelインターフェイスを飛行するかを確認できるコマンドもあります。
# test etherchannel load-balance interface port-channel 1 ip 10.1.1.1 10.1.1.2 Would select Gi2/1/4 of Po1
したがって、ここでは、構成するLUNへの複数のパスを使用することをお勧めします。
スイッチで、6つのVLAN(サーバーの外部インターフェイスごとに1つ)を作成しました。
stack-3750x# sh vlan | i iSCSI 24 iSCSI_VLAN_1 active 25 iSCSI_VLAN_2 active 26 iSCSI_VLAN_3 active 27 iSCSI_VLAN_4 active 28 iSCSI_VLAN_5 active 29 iSCSI_VLAN_6 active
インターフェイスは汎用性のためにトランキングされており、他の何かは後で見られます:
interface GigabitEthernet1/0/11 description VMSTOR1-1 switchport trunk encapsulation dot1q switchport mode trunk switchport nonegotiate flowcontrol receive desired spanning-tree portfast trunk end
サーバーの負荷を減らすには、スイッチのMTUを最大に設定する必要があります(より多くのパケット-> 1秒あたりのパケット数が少ない->中断が少ない)。 私の場合、これは9198です。
(config)# system mtu jumbo 9198
ESXiは9000を超えるMTUをサポートしていないため、まだマージンがあります。
各VLANにはアドレススペースが割り当てられました。簡単にするために、10.1のようにします。 VLAN_ID .0 / 24(たとえば、10.1.24.0 / 24)。 アドレスが不足している場合、より小さなサブネット内に維持できますが、より便利です。
各LUNは個別のiSCSIターゲットで表されるため、各共通ターゲットは「共通」クラスタアドレスで選択され、現在このターゲットにサービスを提供しているノードで発生します:10.1。 VLAN_ID .10および10.1 VLAN_ID .20
また、サーバーには管理用の永続アドレスがありますが、私の場合は10.1.0.100/24および.200(別個のVLAN内)です。
ソフトウェア
そのため、ここでは両方のサーバーに最小限の形式でDebianをインストールしますが、これについては詳しく説明しません。
パッケージアセンブリ
コンパイラとソースでサーバーが乱雑にならないように、別の仮想マシンでアセンブリを行いました。
Debianでカーネルをビルドするには、ビルドに不可欠なメタパッケージを置くだけで十分です。おそらく、他の何かを正確に覚えていません。
kernel.orgから最新のカーネル3.10をダウンロードして解凍します。
# cd /usr/src/ # wget https://www.kernel.org/pub/linux/kernel/v3.x/linux-3.10.27.tar.xz # tar xJf linux-3.10.27.tar.xz
次に、安定したSCSTブランチの最新リビジョンをSVNからダウンロードし、カーネルバージョンのパッチを生成して適用します。
# svn checkout svn://svn.code.sf.net/p/scst/svn/branches/2.2.x scst-svn # cd scst-svn # scripts/generate-kernel-patch 3.10.27 > ../scst.patch # cd linux-3.10.27 # patch -Np1 -i ../scst.patch
iscsi-scstdデーモンをビルドします。
# cd scst-svn/iscsi-scst/usr # make
結果のiscsi-scstdは、サーバーに配置する必要があります(例: / opt / scst)
次に、サーバーのカーネルを構成します。
暗号化をオンにします(必要な場合)。
SCSTおよびDRBDにこれらのオプションを含めることを忘れないでください。
CONFIG_CONNECTOR=y CONFIG_SCST=y CONFIG_SCST_DISK=y CONFIG_SCST_VDISK=y CONFIG_SCST_ISCSI=y CONFIG_SCST_LOCAL=y
これを.debパッケージの形式で収集します(このためには、fakeroot、kernel-package、debhelperを同時にインストールする必要があります)。
# fakeroot make-kpkg clean prepare # fakeroot make-kpkg --us --uc --stem=kernel-scst --revision=1 kernel_image
出力でkernel-scst-image-3.10.27_1_amd64.debパッケージを取得します
次に、DRBDのパッケージを収集します。
# wget http://oss.linbit.com/drbd/8.4/drbd-8.4.4.tar.gz # tar xzf drbd-8.4.4.tar.gz # cd drbd-8.4.4 # dh_make --native --single Enter
debian / rulesファイルを次の状態に変更します(そこには標準ファイルがありますが、カーネルモジュールは収集しません)。
#!/usr/bin/make -f # export KDIR="/usr/src/linux-3.10.27" override_dh_installdocs: < , > override_dh_installchangelogs: < > override_dh_auto_configure: ./configure \ --prefix=/usr \ --localstatedir=/var \ --sysconfdir=/etc \ --with-pacemaker \ --with-utils \ --with-km \ --with-udev \ --with-distro=debian \ --without-xen \ --without-heartbeat \ --without-legacy_utils \ --without-rgmanager \ --without-bashcompletion %: dh $@
Makefile.inファイルでは、SUBDIRS変数を修正し、その変数からドキュメントを削除します 。そうしないと、パッケージはドキュメントの呪いと共に収集されません。
収集するもの:
# dpkg-buildpackage -us -uc -b
パッケージdrbd_8.4.4_amd64.debを取得します
それだけです。他のものを収集する必要はなく、両方のパッケージをサーバーにコピーしてインストールする必要はありません。
# dpkg -i kernel-scst-image-3.10.27_1_amd64.deb # dpkg -i drbd_8.4.4_amd64.deb
サーバー構成
ネットワーク
インターフェイスは、次のように/etc/udev/rules.d/70-persistent-net.rulesに名前が変更されました。
int1-6はスイッチに移動し、 drbd1-4は隣接サーバーに移動します。
/ etc / network / interfacesは非常に恐ろしい外観をしており、悪夢では夢にも思わないでしょう:
auto lo iface lo inet loopback # Interfaces auto int1 iface int1 inet manual up ip link set int1 mtu 9000 up down ip link set int1 down auto int2 iface int2 inet manual up ip link set int2 mtu 9000 up down ip link set int2 down auto int3 iface int3 inet manual up ip link set int3 mtu 9000 up down ip link set int3 down auto int4 iface int4 inet manual up ip link set int4 mtu 9000 up down ip link set int4 down auto int5 iface int5 inet manual up ip link set int5 mtu 9000 up down ip link set int5 down auto int6 iface int6 inet manual up ip link set int6 mtu 9000 up down ip link set int6 down # Management interface auto int1.2 iface int1.2 inet manual up ip link set int1.2 mtu 1500 up down ip link set int1.2 down vlan_raw_device int1 auto int2.2 iface int2.2 inet manual up ip link set int2.2 mtu 1500 up down ip link set int2.2 down vlan_raw_device int2 auto int3.2 iface int3.2 inet manual up ip link set int3.2 mtu 1500 up down ip link set int3.2 down vlan_raw_device int3 auto int4.2 iface int4.2 inet manual up ip link set int4.2 mtu 1500 up down ip link set int4.2 down vlan_raw_device int4 auto int5.2 iface int5.2 inet manual up ip link set int5.2 mtu 1500 up down ip link set int5.2 down vlan_raw_device int5 auto int6.2 iface int6.2 inet manual up ip link set int6.2 mtu 1500 up down ip link set int6.2 down vlan_raw_device int6 auto bond_vlan2 iface bond_vlan2 inet static address 10.1.0.100 netmask 255.255.255.0 gateway 10.1.0.1 slaves int1.2 int2.2 int3.2 int4.2 int5.2 int6.2 bond-mode active-backup bond-primary int1.2 bond-miimon 100 bond-downdelay 200 bond-updelay 200 mtu 1500 # iSCSI auto int1.24 iface int1.24 inet manual up ip link set int1.24 mtu 9000 up down ip link set int1.24 down vlan_raw_device int1 auto int2.25 iface int2.25 inet manual up ip link set int2.25 mtu 9000 up down ip link set int2.25 down vlan_raw_device int2 auto int3.26 iface int3.26 inet manual up ip link set int3.26 mtu 9000 up down ip link set int3.26 down vlan_raw_device int3 auto int4.27 iface int4.27 inet manual up ip link set int4.27 mtu 9000 up down ip link set int4.27 down vlan_raw_device int4 auto int5.28 iface int5.28 inet manual up ip link set int5.28 mtu 9000 up down ip link set int5.28 down vlan_raw_device int5 auto int6.29 iface int6.29 inet manual up ip link set int6.29 mtu 9000 up down ip link set int6.29 down vlan_raw_device int6 # DRBD bonding auto bond_drbd iface bond_drbd inet static address 192.168.123.100 netmask 255.255.255.0 slaves drbd1 drbd2 drbd3 drbd4 bond-mode balance-rr mtu 9216
サーバー管理のフォールトトレランスも必要なため、ミリタリートリックを使用します。 アクティブバックアップモードでのボンディングでは、インターフェイス自体ではなく、VLANサブインターフェイスを収集します。 したがって、少なくとも1つのインターフェイスが実行されている限り、サーバーは使用可能になります。 これは冗長ですが、紫斑病はpaではありません。 また、同じインターフェイスをiSCSIトラフィックに自由に使用できます。
レプリケーションのために、 bond_drbdインターフェイスがbalance-rrモードで作成されました。このモードでは、すべてのインターフェイスにパケットが愚かに連続して送信されます。 彼は灰色のネットワーク/ 24からアドレスを割り当てられましたが、/ 30または/ 31のようにできます ホストは2つだけです。
これによりパケットが順番通りに到着しないことがあるため、/ etc/sysctl.conf内の異常なパケットのバッファを増やします。 以下に、非常に長い間、ファイル全体を示しますが、どのオプションについて説明しませんか。 必要に応じて自分で読むことができます。
net.ipv4.tcp_reordering = 127 net.core.rmem_max = 33554432 net.core.wmem_max = 33554432 net.core.rmem_default = 16777216 net.core.wmem_default = 16777216 net.ipv4.tcp_rmem = 131072 524288 33554432 net.ipv4.tcp_wmem = 131072 524288 33554432 net.ipv4.tcp_no_metrics_save = 1 net.ipv4.tcp_window_scaling = 1 net.ipv4.tcp_timestamps = 0 net.ipv4.tcp_sack = 0 net.ipv4.tcp_dsack = 0 net.ipv4.tcp_fin_timeout = 15 net.core.netdev_max_backlog = 300000 vm.min_free_kbytes = 720896
テスト結果によると、レプリケーションインターフェイスは3.7 Gb / sを生成しますが、これはまったく問題ありません。
マルチコアサーバーがあり、ネットワークカードとRAIDコントローラーがいくつかのキュー間で割り込みの処理を分離できるため、割り込みをカーネルにリンクするスクリプトが作成されました。
#!/usr/bin/perl -w use strict; use warnings; my $irq = 77; my $ifs = 11; my $queues = 6; my $skip = 1; my @tmpl = ("0", "0", "0", "0", "0", "0"); print "Applying IRQ affinity...\n"; for(my $if = 0; $if < $ifs; $if++) { for(my $q = 0; $q < $queues; $q++, $irq++) { my @tmp = @tmpl; $tmp[$q] = 1; my $mask = join("", @tmp); my $hexmask = bin2hex($mask); #print $irq . " -> " . $hexmask . "\n"; open(OUT, ">/proc/irq/".$irq."/smp_affinity"); print OUT $hexmask."\n"; close(OUT); } $irq += $skip; } sub bin2hex { my ($bin) = @_; return sprintf('%x', oct("0b".scalar(reverse($bin)))); }
ディスク
ディスクをエクスポートする前に、それらを暗号化し、すべての消防士のマスターキーを保護します。
# cryptsetup luksFormat --cipher aes-cbc-essiv:sha256 --hash sha256 /dev/sdb # cryptsetup luksFormat --cipher aes-cbc-essiv:sha256 --hash sha256 /dev/sdc # cryptsetup luksHeaderBackup /dev/sdb --header-backup-file /root/header_sdb.bin # cryptsetup luksHeaderBackup /dev/sdc --header-backup-file /root/header_sdc.bin
パスワードは頭蓋骨の内側に書き込まれ、決して忘れられないようにし、キーのバックアップは地獄に隠されるべきです。
マスターキーのバックアップセクションのパスワードを変更した後、古いパスワードを復号化できることに注意してください。
次に、復号化を簡素化するためのスクリプトが作成されました。
#!/usr/bin/perl -w use strict; use warnings; use IO::Prompt; my %crypto_map = ( '1bd1f798-d105-4150-841b-f2751f419efc' => 'VM_STORAGE_1', 'd7fcdb2b-88fd-4d19-89f3-5bdf3ddcc456' => 'VM_STORAGE_2' ); my $i = 0; my $passwd = prompt('Password: ', '-echo' => '*'); foreach my $dev (sort(keys(%crypto_map))) { $i++; if(-e '/dev/mapper/'.$crypto_map{$dev}) { print "Mapping '".$crypto_map{$dev}."' already exists, skipping\n"; next; } my $ret = system('echo "'.$passwd.'" | /usr/sbin/cryptsetup luksOpen /dev/disk/by-uuid/'.$dev.' '.$crypto_map{$dev}); if($ret == 0) { print $i . ' Crypto mapping '.$dev.' => '.$crypto_map{$dev}.' added successfully' . "\n"; } else { print $i . ' Failed to add mapping '.$dev.' => '.$crypto_map{$dev} . "\n"; exit(1); } }
スクリプトは、ディスクのUUIDを使用して、 / dev / sd *にバインドせずに、システム内のディスクを常に一意に識別します。
暗号化速度はプロセッサの周波数とコアの数に依存し、記録は読み取りよりも並列化されます。 次の簡単な方法で、サーバーが暗号化する速度を確認できます。
, , # echo "0 268435456 zero" | dmsetup create zerodisk # cryptsetup --cipher aes-cbc-essiv:sha256 --hash sha256 create zerocrypt /dev/mapper/zerodisk Enter passphrase: < > : # dd if=/dev/zero of=/dev/mapper/zerocrypt bs=1M count=16384 16384+0 records in 16384+0 records out 17179869184 bytes (17 GB) copied, 38.3414 s, 448 MB/s # dd of=/dev/null if=/dev/mapper/zerocrypt bs=1M count=16384 16384+0 records in 16384+0 records out 17179869184 bytes (17 GB) copied, 74.5436 s, 230 MB/s
ご覧のとおり、速度はそれほど熱くありませんが、実際にはほとんど達成されません。 通常、ランダムアクセスが優先されます。
比較のため、 Haswellコアの新しいXeon E3-1270 v3での同じテストの結果:
# dd if=/dev/zero of=/dev/mapper/zerocrypt bs=1M count=16384 16384+0 records in 16384+0 records out 17179869184 bytes (17 GB) copied, 11.183 s, 1.5 GB/s # dd of=/dev/null if=/dev/mapper/zerocrypt bs=1M count=16384 16384+0 records in 16384+0 records out 17179869184 bytes (17 GB) copied, 19.4902 s, 881 MB/s
さて、ここではもっと楽しいです。 頻度は明らかに決定的な要因です。
また、AES-NIを無効にすると、数倍遅くなります。
DRBD
レプリケーションを構成します。両端からの構成は100%同一でなければなりません。
/etc/drbd.d/global_common.conf
global { usage-count no; } common { protocol B; handlers { } startup { wfc-timeout 10; } disk { c-plan-ahead 0; al-extents 6433; resync-rate 400M; disk-barrier no; disk-flushes no; disk-drain yes; } net { sndbuf-size 1024k; rcvbuf-size 1024k; max-buffers 8192; # x PAGE_SIZE max-epoch-size 8192; # x PAGE_SIZE unplug-watermark 8192; timeout 100; ping-int 15; ping-timeout 60; # x 0.1sec connect-int 15; timeout 50; # x 0.1sec verify-alg sha1; csums-alg sha1; data-integrity-alg crc32c; cram-hmac-alg sha1; shared-secret "ultrasuperdupermegatopsecretpassword"; use-rle; } }
ここで最も興味深いパラメーターはプロトコルです。それらを比較してください。
ブロックが記録された場合、記録は成功したと見なされます...
- A-ローカルディスクにアクセスし、ローカル送信バッファをヒットする
- B-ローカルディスクに、リモート受信バッファに入った
- C-ローカルおよびリモートディスクへ
最も遅い(読み取り-高遅延)と同時に信頼できるのはCであり、私は中間地点を選択しました。
次は、DRBDとその複製に関係するノードが動作するリソースの定義です。
/etc/drbd.d/VM_STORAGE_1.res
resource VM_STORAGE_1 { device /dev/drbd0; disk /dev/mapper/VM_STORAGE_1; meta-disk internal; on vmstor1 { address 192.168.123.100:7801; } on vmstor2 { address 192.168.123.200:7801; } }
/etc/drbd.d/VM_STORAGE_2.res
resource VM_STORAGE_2 { device /dev/drbd1; disk /dev/mapper/VM_STORAGE_2; meta-disk internal; on vmstor1 { address 192.168.123.100:7802; } on vmstor2 { address 192.168.123.200:7802; } }
各リソースには独自のポートがあります。
次に、DRBDリソースメタデータを初期化してアクティブにします。これは各サーバーで実行する必要があります。
# drbdadm create-md VM_STORAGE_1 # drbdadm create-md VM_STORAGE_2 # drbdadm up VM_STORAGE_1 # drbdadm up VM_STORAGE_2
次に、1つのサーバー(リソースごとに1つ持つことができます)を選択し、それがメインサーバーであり、プライマリ同期がそのサーバーから別のサーバーに移動することを決定する必要があります。
# drbdadm primary --force VM_STORAGE_1 # drbdadm primary --force VM_STORAGE_2
すべて、行こう、同期が始まった。
アレイのサイズとネットワーク速度に応じて、長時間または非常に長い時間がかかります。
その進行はwatch -n0.1 cat / proc / drbdコマンドで観察でき、非常に穏やかで哲学的です。
原則として、デバイスはすでに同期プロセスで使用できますが、リラックスすることをお勧めします:)
最初の部分の終わり
一枚については、それで十分だと思います。 そして、非常に多くの情報がすでに吸収されています。
第2部では、この共有で動作するようにESXiクラスターマネージャーとホストを構成する方法について説明します。