 良い一日。 先日、光学式テキスト認識の結果を後処理するアルゴリズムを実装するタスクがありました。 この問題を解決するために、テキストのスペルをチェックするためのモデルの1つは悪くありませんでしたが、もちろん、タスクのコンテキストに合わせてわずかに変更されました。 この投稿では、自動スペルチェックを可能にするNoisy Channelモデルに専念します。数学的モデルを研究し、c#でコードを記述し、Peter Norwigに基づいてモデルをトレーニングし、最終的に取得するものをテストします。
良い一日。 先日、光学式テキスト認識の結果を後処理するアルゴリズムを実装するタスクがありました。 この問題を解決するために、テキストのスペルをチェックするためのモデルの1つは悪くありませんでしたが、もちろん、タスクのコンテキストに合わせてわずかに変更されました。 この投稿では、自動スペルチェックを可能にするNoisy Channelモデルに専念します。数学的モデルを研究し、c#でコードを記述し、Peter Norwigに基づいてモデルをトレーニングし、最終的に取得するものをテストします。
数学モデル-1
問題のステートメントから始めます。 ですから、 m個の文字で構成される単語wを書きたいのですが、何らかの方法で、 n個の文字で構成される単語xが紙に出てきます。 ちなみに、あなたはまったく同じうるさいチャンネルであり、正しい単語w (正しい単語の世界から)を間違ったx (書かれたすべての単語のセット)に歪ませるノイズのある情報を送信するためのチャネルです。

単語xを書くときにあなたが意味する可能性が最も高い単語を見つけたいと思います。 この考えを数学的に書きましょう。そのアイデアのモデルは、 単純なベイズ分類器のモデルに似ていますが、さらに単純です。

- Vは、自然言語のすべての単語のリストです。
次に、ベイズの定理を使用して、原因と結果を拡張し、分母から合計確率xを削除できます。 argmaxの場合、 wに依存しません。

- P(w)は、言語内の単語wの事前確率です。 このメンバーは自然言語の統計モデル( 言語モデル )です。もちろん、より複雑なモデルを使用する権利がありますが、 unigram モデルを使用します。 また、このメンバーの値は、言語の単語のデータベースから簡単に計算されることに注意してください。
- P(x | w) -正しい単語wが誤ってxとして記述された確率。このメンバーはチャネルモデルと呼ばれます。 原則として、言語の各単語を書くときに間違いを犯すすべての方法を含む十分に大きなベースを持っているので、この用語を計算することは困難ではありませんが、残念ながらそのような大きなベースはありませんが、より小さいサイズの類似したベースがあるので、何らかの方法でそれを取得する必要がありますここは英語の333333語のベースであり、7481についてのみエラーのある語があります。
確率値P(x | w)の計算
ここで、 Damerau-Levenshteinの距離が役立ちます-これは、 ソース文字列をターゲット文字列にするために、隣接する文字を挿入、削除、置換、および再配置する最小操作数として定義される、2つの文字シーケンス間の測定値です。 Levenshtein distanceを引き続き使用します 。これは、隣接する文字を並べ替える操作をサポートしていないという点で異なるため、より簡単になります。 これらのアルゴリズムと例の両方について、ここで詳しく説明しているため、繰り返しはしませんが、すぐにコードを提供します。
レーベンシュタイン距離
public static int LevenshteinDistance(string s, string t) { int[,] d = new int[s.Length + 1, t.Length + 1]; for (int i = 0; i < s.Length + 1; i++) { d[i, 0] = i; } for (int j = 1; j < t.Length + 1; j++) { d[0, j] = j; } for (int i = 1; i <= s.Length; i++) { for (int j = 1; j <= t.Length; j++) { d[i, j] = (new int[] { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }).Min(); } } return d[s.Length, t.Length]; }
この関数は、ある単語を別の単語に移動するために実行する必要がある削除、挿入、および置換の操作の数を示しますが、これでは十分ではありませんが、これらの操作のリストも取得したいので、バックトレースアルゴリズムと呼びましょう。 距離dのマトリックスを計算するときに、操作bのマトリックスも書き込まれるように、コードを変更する必要があります。 単語caおよびabcの例を考えてみましょう。
| d | b (0-左からソースから削除、1- ターゲットからソースへ挿入、2- ソース内の文字をターゲットからの文字で置換) |
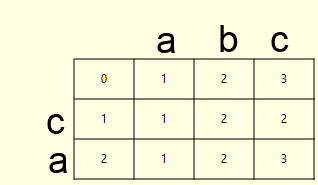 |  |
覚えているように、距離行列dのセル(i、j)の値は次のように計算されます。
d[i, j] = (new int[] { d[i - 1, j] + 1, // del - 0 d[i, j - 1] + 1, // ins - 1 d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub - 2 }).Min();
オペレーションのマトリックスbのセル(i、j)にオペレーションのインデックス(削除の場合は0、挿入の場合は1、置換の場合は2)をそれぞれ書き込む必要があります。このコードは次のように変換されます。
IList<int> vals = new List<int>() { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }; d[i, j] = vals.Min(); int idx = vals.IndexOf(d[i, j]); b[i, j] = idx;
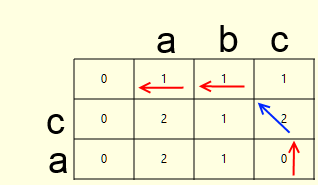
両方のマトリックスがいっぱいになると、バックトレースを計算するのは難しくありません(上の図の矢印)。 これは、距離マトリックスの最小コストのパスに沿った、操作マトリックスの右下のセルからのパスです。 アルゴリズムについて説明します。
- 現在として右下のセルを示します
- 次のいずれかを行います
- 削除する場合は、削除した文字を書き込み、現在のセルを上に移動します(赤い矢印)
- 挿入の場合、挿入された文字を書き込み、現在のセルを左に移動します(赤い矢印)
- 置換文字と置換文字が等しくない場合、置換文字を書き込み、現在のセルを左上に移動します(赤い矢印)
- 置換されたが、置換された文字が等しい場合、現在のセルを左上にのみ移動します(青い矢印)
- 記録された操作の数がレーベンシュタイン距離と等しくない場合、1ポイント戻り、それ以外の場合は停止します
その結果、レーベンシュタイン距離とバックトレースを計算する次の関数を取得します。
バックトレース付きのレーベンシュタイン距離
//del - 0, ins - 1, sub - 2 public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t) { int[,] d = new int[s.Length + 1, t.Length + 1]; int[,] b = new int[s.Length + 1, t.Length + 1]; for (int i = 0; i < s.Length + 1; i++) { d[i, 0] = i; } for (int j = 1; j < t.Length + 1; j++) { d[0, j] = j; b[0, j] = 1; } for (int i = 1; i <= s.Length; i++) { for (int j = 1; j <= t.Length; j++) { IList<int> vals = new List<int>() { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }; d[i, j] = vals.Min(); int idx = vals.IndexOf(d[i, j]); b[i, j] = idx; } } List<Tuple<int, string>> bt = new List<Tuple<int, string>>(); int x = s.Length; int y = t.Length; while (bt.Count != d[s.Length, t.Length]) { switch (b[x, y]) { case 0: x--; bt.Add(new Tuple<int, string>(0, s[x].ToString())); break; case 1: y--; bt.Add(new Tuple<int, string>(1, t[y].ToString())); break; case 2: x--; y--; if (s[x] != t[y]) { bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y])); } break; } } bt.Reverse(); return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt); }
この関数は、タプルを返します。最初の要素にはレーベンシュタインの距離が記録され、2番目にはペア<操作ID、行>のリストがあります。この行は削除および挿入操作用の1文字と置換操作用の2文字で構成されます(最初の文字を2番目の文字)
PS:熱心な読者は、右下のセルから最小コストのパスに沿って移動する方法がいくつかあることに気付くでしょう。これは選択を増やす1つの方法ですが、簡単にするために省略します。
数学モデル-2
ここで、上記で得られた結果を式の言語で説明します。 2つの単語xとwについて、最初の単語を2番目に減らすために必要な演算のリストを計算し、文字fで演算のリストを示し、 wとして単語xを書き込む確率は、正確にxを書き込んだ場合、エラーfのリスト全体を生成する確率に等しくなり、暗黙のw :

ここで、単純なベイジアン分類器にあったものと同様の単純化が始まります。
- エラー操作の順序は関係ありません
- エラーは、私たちが書いた言葉や意味に依存しません

さて、エラーの確率を計算するためには(それらがどの単語で作成されたかに関係なく)、スペルが間違っている単語のデータベースがあれば十分です。 ゼロに近い数値での作業を回避するために、ログスペースで作業する最終式を作成します。

では、何がありますか? 十分な数のテキストが手元にあれば、その言語の単語の事前確率を計算できます。 また、誤ったスペルの単語のベースを手元に置いて、エラーの確率を計算できます。これらの2つのベースは、モデルを実装するのに十分です。
エラー確率ぼかし
argmaxを使用してすべての単語ベースを実行すると、確率ゼロの単語に出会うことはありません。 しかし、編集操作を計算して、単語xを単語wにする場合、エラーデータベースで発生しなかった操作が発生する場合があります。 この場合、 加法平滑化またはラプラスぼかしが役立ちます( 単純ベイズ分類器でも使用されていました)。 現在のタスクのコンテキストで数式を思い出させてください。 修正操作fがデータベースでn回発生し、データベースのエラーの総数がmであり、修正タイプがtの場合 (たとえば、置換する場合、置換「 a by b 」が発生する回数ではなく、一意のペア「* by * ")、ぼかし確率は次のとおりです。ここで、 kはぼかし係数です。
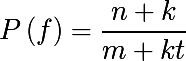
その場合、トレーニングベースで一度も遭遇したことのない操作の確率( n = 0 )は次のようになります。
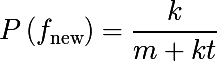
スピード
単語のデータベース全体を実行する必要があるため、アルゴリズムの速度については自然な疑問が発生します。これは、バックトレースでレーベンシュタイン距離を計算する機能の数十万回の呼び出しであり、すべての単語のエラーの確率(数値の合計、保存されている場合)を計算するためですデータベースには、事前に計算された対数が含まれています)。 次の統計的事実が助けになります。
- すべての印刷エラーの80%は1回の編集操作、つまり 統一に等しいレーベンシュタイン距離
- ほとんどすべての印刷エラーは、2つの編集操作の範囲内です
それでは、さまざまなアルゴリズムのトリックを思いつくことができます。 アルゴリズムを高速化するために、明白で非常に簡単な方法を使用しました。 明らかに、現在の単語からt個以下の編集操作で単語のみが必要な場合、それらの長さは現在の単語とt以下だけ異なります。 クラスを初期化するときに、キーが単語の長さであり、値がこの長さの単語のセットであるハッシュテーブルを作成します。これにより、検索スペースを大幅に削減できます。
コード
取得したNoisyChannelクラスのコードを提供します。
ノイズチャンネル
public class NoisyChannel { #region vars private string[] _words = null; private double[] _wLogPriors = null; private IDictionary<int, IList<int>> _wordLengthDictionary = null; //length of word - word indices private IDictionary<int, IDictionary<string, double>> _mistakeLogProbs = null; private double _lf = 1d; private IDictionary<int, int> _mNorms = null; #endregion #region ctor public NoisyChannel(string[] words, long[] wordFrequency, IDictionary<int, IDictionary<string, int>> mistakeFrequency, int mistakeProbSmoothing = 1) { _words = words; _wLogPriors = new double[_words.Length]; _wordLengthDictionary = new SortedDictionary<int, IList<int>>(); double wNorm = wordFrequency.Sum(); for (int i = 0; i < _words.Length; i++) { _wLogPriors[i] = Math.Log((wordFrequency[i] + 0d)/wNorm); int wl = _words[i].Length; if (!_wordLengthDictionary.ContainsKey(wl)) { _wordLengthDictionary.Add(wl, new List<int>()); } _wordLengthDictionary[wl].Add(i); } _lf = mistakeProbSmoothing; _mistakeLogProbs = new Dictionary<int, IDictionary<string, double>>(); _mNorms = new Dictionary<int, int>(); foreach (int mType in mistakeFrequency.Keys) { int mNorm = mistakeFrequency[mType].Sum(m => m.Value); _mNorms.Add(mType, mNorm); int mUnique = mistakeFrequency[mType].Count; _mistakeLogProbs.Add(mType, new Dictionary<string, double>()); foreach (string m in mistakeFrequency[mType].Keys) { _mistakeLogProbs[mType].Add(m, Math.Log((mistakeFrequency[mType][m] + _lf)/ (mNorm + _lf*mUnique)) ); } } } #endregion #region correction public IDictionary<string, double> GetCandidates(string s, int maxEditDistance = 2) { IDictionary<string, double> candidates = new Dictionary<string, double>(); IList<int> dists = new List<int>(); for (int i = s.Length - maxEditDistance; i <= s.Length + maxEditDistance; i++) { if (i >= 0) { dists.Add(i); } } foreach (int dist in dists) { foreach (int tIdx in _wordLengthDictionary[dist]) { string t = _words[tIdx]; Tuple<int, IList<Tuple<int, string>>> d = LevenshteinDistanceWithBacktrace(s, t); if (d.Item1 > maxEditDistance) { continue; } double p = _wLogPriors[tIdx]; foreach (Tuple<int, string> m in d.Item2) { if (!_mistakeLogProbs[m.Item1].ContainsKey(m.Item2)) { p += _lf/(_mNorms[m.Item1] + _lf*_mistakeLogProbs[m.Item1].Count); } else { p += _mistakeLogProbs[m.Item1][m.Item2]; } } candidates.Add(_words[tIdx], p); } } candidates = candidates.OrderByDescending(c => c.Value).ToDictionary(c => c.Key, c => c.Value); return candidates; } #endregion #region static helper //del - 0, ins - 1, sub - 2 public static Tuple<int, IList<Tuple<int, string>>> LevenshteinDistanceWithBacktrace(string s, string t) { int[,] d = new int[s.Length + 1, t.Length + 1]; int[,] b = new int[s.Length + 1, t.Length + 1]; for (int i = 0; i < s.Length + 1; i++) { d[i, 0] = i; } for (int j = 1; j < t.Length + 1; j++) { d[0, j] = j; b[0, j] = 1; } for (int i = 1; i <= s.Length; i++) { for (int j = 1; j <= t.Length; j++) { IList<int> vals = new List<int>() { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }; d[i, j] = vals.Min(); int idx = vals.IndexOf(d[i, j]); b[i, j] = idx; } } List<Tuple<int, string>> bt = new List<Tuple<int, string>>(); int x = s.Length; int y = t.Length; while (bt.Count != d[s.Length, t.Length]) { switch (b[x, y]) { case 0: x--; bt.Add(new Tuple<int, string>(0, s[x].ToString())); break; case 1: y--; bt.Add(new Tuple<int, string>(1, t[y].ToString())); break; case 2: x--; y--; if (s[x] != t[y]) { bt.Add(new Tuple<int, string>(2, s[x] + "" + t[y])); } break; } } bt.Reverse(); return new Tuple<int, IList<Tuple<int, string>>>(d[s.Length, t.Length], bt); } public static int LevenshteinDistance(string s, string t) { int[,] d = new int[s.Length + 1, t.Length + 1]; for (int i = 0; i < s.Length + 1; i++) { d[i, 0] = i; } for (int j = 1; j < t.Length + 1; j++) { d[0, j] = j; } for (int i = 1; i <= s.Length; i++) { for (int j = 1; j <= t.Length; j++) { d[i, j] = (new int[] { d[i - 1, j] + 1, // del d[i, j - 1] + 1, // ins d[i - 1, j - 1] + (s[i - 1] == t[j - 1] ? 0 : 1) // sub }).Min(); } } return d[s.Length, t.Length]; } #endregion }
クラスは、次のパラメーターで初期化されます。
- string [] words-言語の単語のリスト。
- long [] wordFrequency-単語の頻度。
- IDictionary <int、IDictionary <string、int >> mistakeFrequency
- int errorProbSmoothing = 1-エラー率ぼかし係数
テスト中
テストには、Peter Norvigデータベースを使用します 。このデータベースには 、頻度のある333333の単語と、誤ったスペルの7481の単語が含まれています。 次のコードを使用して、NoisyChannelクラスを初期化するために必要な値を計算します。
読書拠点
string[] words = null; long[] wordFrequency = null; #region read priors if (!File.Exists("../../../Data/words.bin") || !File.Exists("../../../Data/wordFrequency.bin")) { IDictionary<string, long> wf = new Dictionary<string, long>(); Console.Write("Reading data:"); using (StreamReader sr = new StreamReader("../../../Data/count_1w.txt")) { string line = sr.ReadLine(); while (line != null) { string[] parts = line.Split('\t'); wf.Add(parts[0].Trim(), Convert.ToInt64(parts[1])); line = sr.ReadLine(); Console.Write("."); } sr.Close(); } Console.WriteLine("Done!"); words = wf.Keys.ToArray(); wordFrequency = wf.Values.ToArray(); using (FileStream fs = File.Create("../../../Data/words.bin")) { BinaryFormatter bf = new BinaryFormatter(); bf.Serialize(fs, words); fs.Flush(); fs.Close(); } using (FileStream fs = File.Create("../../../Data/wordFrequency.bin")) { BinaryFormatter bf = new BinaryFormatter(); bf.Serialize(fs, wordFrequency); fs.Flush(); fs.Close(); } } else { using (FileStream fs = File.OpenRead("../../../Data/words.bin")) { BinaryFormatter bf = new BinaryFormatter(); words = bf.Deserialize(fs) as string[]; fs.Close(); } using (FileStream fs = File.OpenRead("../../../Data/wordFrequency.bin")) { BinaryFormatter bf = new BinaryFormatter(); wordFrequency = bf.Deserialize(fs) as long[]; fs.Close(); } } #endregion //del - 0, ins - 1, sub - 2 IDictionary<int, IDictionary<string, int>> mistakeFrequency = new Dictionary<int, IDictionary<string, int>>(); #region read mistakes IDictionary<string, IList<string>> misspelledWords = new SortedDictionary<string, IList<string>>(); using (StreamReader sr = new StreamReader("../../../Data/spell-errors.txt")) { string line = sr.ReadLine(); while (line != null) { string[] parts = line.Split(':'); string wt = parts[0].Trim(); misspelledWords.Add(wt, parts[1].Split(',').Select(w => w.Trim()).ToList()); line = sr.ReadLine(); } sr.Close(); } mistakeFrequency.Add(0, new Dictionary<string, int>()); mistakeFrequency.Add(1, new Dictionary<string, int>()); mistakeFrequency.Add(2, new Dictionary<string, int>()); foreach (string s in misspelledWords.Keys) { foreach (string t in misspelledWords[s]) { var d = NoisyChannel.LevenshteinDistanceWithBacktrace(s, t); foreach (Tuple<int, string> ml in d.Item2) { if (!mistakeFrequency[ml.Item1].ContainsKey(ml.Item2)) { mistakeFrequency[ml.Item1].Add(ml.Item2, 0); } mistakeFrequency[ml.Item1][ml.Item2]++; } } } #endregion
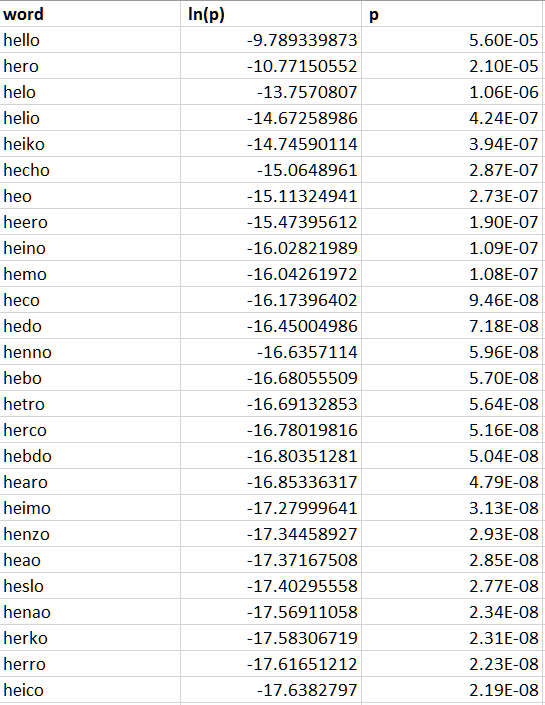
次のコードは、モデルを初期化し、「 he ;; o 」という単語の正しい単語を検索します(もちろん、 helloを意味し、セミコロンはlの右側にあり、印刷時にミスを犯しやすいため、データベースにはhelloのスペルリストにheloという単語が含まれていません。 ; o )記録されている時間で、2以下の距離で:
NoisyChannel nc = new NoisyChannel(words, wordFrequency, mistakeFrequency, 1); Stopwatch timer = new Stopwatch(); timer.Start(); IDictionary<string, double> c = nc.GetCandidates("he;;o", 2); timer.Stop(); TimeSpan ts = timer.Elapsed; Console.WriteLine(ts.ToString());
私にとって、このような計算は平均で1秒弱かかりますが、もちろん最適化プロセスは上記の方法に限定されるものではなく、それらの方法でのみ開始されます。 交換オプションとその可能性を見てください。
参照資料
コードを含むアーカイブはここからマージできます 。