1日あたり約1億通の手紙がメールに届き、そのうち1,000万通が添付ファイル付きです。 添付ファイルが含まれているのは文字の10%だけであるにもかかわらず、添付ファイルがある文字の中で、複数のファイルが存在する文字のかなりの割合です。 平均して、文字の総数は添付ファイルの総数に等しいことがわかりました。
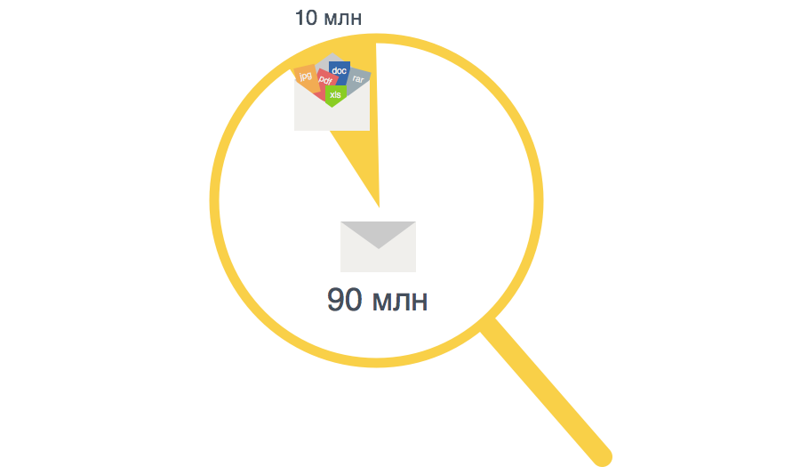
添付ファイル付きのレターの平均サイズは400 kb、添付ファイルなしのレターは4 kbです。 1文字の添付ファイルの合計サイズは30 MBに達する可能性があります。 添付ファイルのトップ10種類:.jpg、.pdf、.xls、.rar、.doc、.zip、.eml、.mp3、.tif、.docx。 テキストを除くほとんどすべてのファイル形式には、大量の冗長オーバーヘッド情報が含まれています。 したがって、たとえば、.docx形式には、平均してテキスト情報が10%しか含まれておらず、jpgからは、検索のインデックス作成用のメタ情報が0.25%しか得られません。
これにより、1日あたり25 Tbのオーダーの着信トラフィックの合計量が得られます。これは、大きく複雑なメール製品の機能を確保するために数回増加します。 このような負荷に対応するために、Yandex.Mailは大規模なネットワーク、サーバー、およびサービスインフラストラクチャを作成しました。これには、異なるデータセンターに分散されたいくつかのクラスターが含まれます。
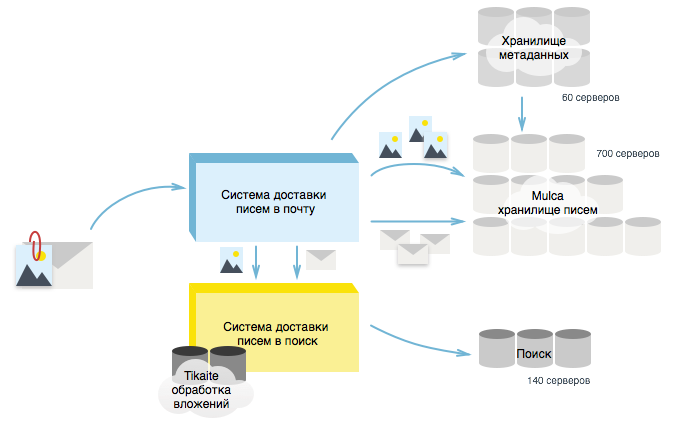
メールのすべての文字は配信システム(数百のサーバーのクラスター)に送られます。 配信システムは、レターをメールリポジトリ、メタ情報リポジトリに保存し、検索で送信します。つまり、3つの異なる場所に一度に送信し、それぞれが独自のタスクを実行します。
手紙の保管庫は 、要求に応じて各手紙の内容全体を保存および返却する責任があり、何らかの理由で歴史的に「マルカ」と呼ばれます。 Yandex.Mailにレターを保存するために、700台のラバサーバーを展開しました。 手紙、見出し、添付ファイルの内容を保存します-つまり、手紙に関連するすべてのものです。
メタ情報リポジトリは、受信ボックスをすばやく表示するために使用され、レターの説明部分のみが含まれます。 たとえば、「From」、「To」、「Subject」フィールド、レターが現在配置されているフォルダーの名前、現在のラベル、作成日など。 メタ情報クラスターは60台のサーバーを占有します。
検索リポジトリは、形態を考慮して、メールボックスでの迅速な全文検索を提供するために必要なレターのすべての情報を含む検索インデックスです。 インデックス作成と検索のタスクを実行する検索サービスは、同時に140台のサーバーに関与しました。
手紙の保管場所とメタ情報の保管場所にある手紙は配達されたとみなされます。 検索でのレターの配信は、リポジトリに配置された後に実行されます。 25台のサーバーで構成される別のサービスクラスターが、検索中のレターの配信用に割り当てられています。 このクラスターには、インデックス作成を待機している文字のキューと、インデックス作成用のデータを準備するプログラムがあります。
このように、手紙がメールに入ってくると、大いに役立ちます。 まず、リポジトリに追加され、次にサービスクラスタに分類され、そこで検索用に送信される準備が整います。
ただし、 文字検索は 、 文字の本文の検索だけでなく、添付ファイルの内容の検索でもあります。 それを提供するには、添付ファイルとして送信されるファイルを前処理し、テキストを抽出してテキスト形式で送信して検索する必要があります。
数年前、上記で発表した元のアーキテクチャを変更せずに、添付ファイルの内容の検索を開始しました。 これには多くの問題が伴いました。 まず、いくつかの種類のファイル(特に.pdf)が長時間(最大数分)処理され、検索での新しい文字の配信が遅くなりました。 次に、インデックス作成プログラムとサービスクラスター上の変換プログラムの間でリソースの競合が絶えず発生し、新しいメッセージの検索も遅くなりました。 そして第三に、添付ファイル付きのレター全体をサービスクラスターに送信し始めたとき、Yandexネットワーク内のメールトラフィックを実際に2倍にしました。 ネットワーク内トラフィックは1日あたり25 Tb増加しました。これは、サーバー、ネットワークインフラストラクチャ、およびネットワークパフォーマンス全体として、パーソナルサービスおよびYandex全体にとって有用なリソースへの負荷です。
そのため、サービスの質のために戦わなければなりませんでした。 数分後に手紙が検索されるようにすることは不可能でした。 さらに、添付ファイルの検索を開始する前に、すべての受信文字の95%が1秒未満で検索に落ちました。
文字全体をリポジトリにのみ配信し、構造化テキストのみをリポジトリから直接返す検索で配信するというアイデアがありました。 予備調査では、検索に必要なテキストの平均サイズは、メールの文字の平均サイズの10倍小さいことが示されています。 したがって、検索でテキストのみが表示される場合、検索で消費されるネットワークトラフィックは10倍少なくなり、1日あたり約22 Tb節約されます。 トラフィックを節約するために、ゲームはろうそくに値するようです。
また、リポジトリのパフォーマンスを使用して、小さなサービスクラスターよりも2桁大きいストレージパフォーマンスを検索することも魅力的でした。 これにより、加速することができます。 彼らはそうしました。
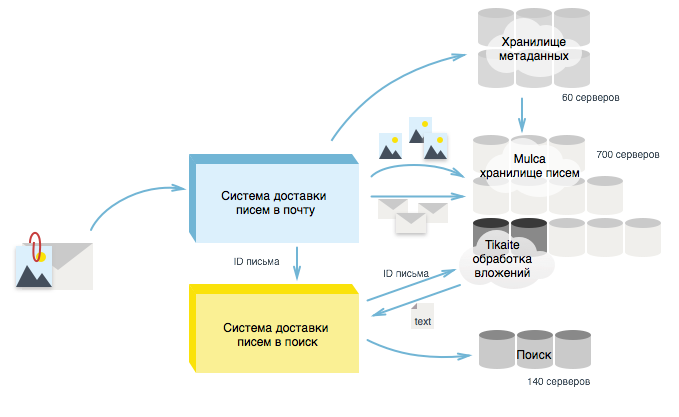
発声されたアイデアを実装し、レターおよび添付ファイルのコンテンツをリポジトリから直接受信できるように、添付ファイルのコンテンツを抽出するプログラムをサーバーに配置する必要がありました。 このプログラムはApache Tikaライブラリに基づいているため、開発者はロシア語との単純化と調和のために、それをTikaiteと呼びました。 MulcaにTikaiteを配置する場合、レターのストレージを傷つけないことが重要でした。したがって、負荷を詳細に調査し、ストレージがディスクスペースにロードされ、使用可能な十分な空きプロセッサパフォーマンスリソースがあることを確認しました。
ストレージに厳しい制限があるさまざまな形式からテキストを抽出するためのプログラムを配置しました。プログラムにはプロセッサパフォーマンスの50%が提供され、各サーバーに1 GBのRAMが割り当てられました。 このような制限により、リポジトリで変換プロセスを開始することができ、ストレージプロセスに干渉することはありません。
その結果、偽のイントラネットトラフィックを減らし、検索に文字を配信するシステムのパフォーマンスを2桁向上させました。再び文字の95%が1秒以内に検索を開始しました。 配信時に、検索用の文字を配信するためにクラスターの25の無料サーバーで追加のボーナスを受け取りました。 最初にサービスクラスターを2倍に拡張し、増え続けるフローに対処するためにここに50台のサーバーを配置することを計画した場合、検索に必要なすべてのデータはメールリポジトリーで直接準備されるため、実際には25のサーバーのクラスター全体が無料になります。 そのため、近い将来、他のタスクに使用できるようになる予定です。
PSそして、メールで検索するには、Yandex.Mailの存在全体に蓄積されたすべての文字のインデックスの再作成が定期的に必要です。 これは、検索アルゴリズムを変更する必要があり、このための検索に十分なデータがない場合に発生します。 現時点では、実際にメールに保存されている文字の配列全体を処理していますが、これは現在約10ペタバイトです。 ここで、ネットワークトラフィックとパフォーマンスの大幅な節約になります。
PPS結果にもかかわらず、私たちはそこで停止する予定はありません。 手紙を保管するのと同時に検索で手紙を配達できるように努力し、そのために解放されたクラスターを使用します。 Yandex.Mailでの検索に関する新しい出版物でこれに関する情報を待ちます。