この投稿では(そして、シリーズがうまくいけば、人々が興味を持っているなら) 、コライダーが毎年生成する「20キロの高さのCDの山」がどうなるかを伝えようとします来年か二年でそうなりません)。
データはどうなりますか?
シェフィールド大学からの写真
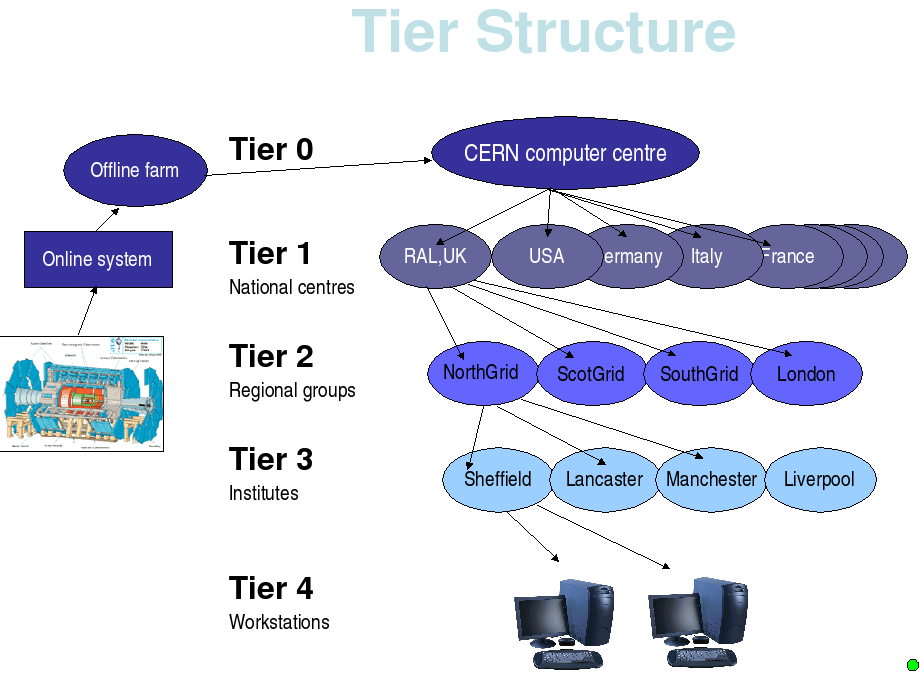
4つの実験(ATLAS、Alice、LHCb、CMS)の検出器は、それらを通る素粒子(イベント)の通過を記録します。 検出器が記録したのは、生データ(RAWデータ)です。 それらのフローは膨大で、時間の経過とともに非常に不均一に分散します。1日あたり約40Tbの生データ(年間15Pb)が蓄積されますが、これらはすべて実験の数時間で発生します。 レベル0(Tier-0)でこのスレッドを使用して実行できる唯一のことは、さらなる処理のためにデータを保存することです。 データが保存された後、その処理が開始されます。 Tier-0の計算能力は大きくなく 、「わずか」〜50,000コアです。これは、LHCにサービスを提供するグリッド全体の合計計算能力の約10%です。 Tier-0では、データの前処理が実行されます。自然ノイズが除去されるなどです(残念ながら、これらの問題には強くありません) 。 したがって、Tier-0には、LHCで受信したデータの完全なコピーがあります。 Tier-0ストレージ容量は、83Pbテープと33Pbディスクです。
さらに、このデータは世界中の11のコンピューティングセンター (カナダ、ドイツ、スペイン、フランス、イタリア、オランダ、台湾、イギリス、アメリカx2、北ヨーロッパの国々のコラボレーション。ロシアでは12番目) -Tier-1に配布されます。 Tier-0は各Tier-1高速リンクに関連付けられます(通常、2Gb / sから)。
各Tier-1では、生データもテープに保存されます。 さらに、基本的なデータ処理が開始されます。
各実験ではTierの計算能力が異なりますが、本質は同じです。検出器と物理法則からのデータに基づいて、数百万の粒子の軌跡とビームの衝突の画像が復元されます。 イベントの回復に加えて、特定の数学的モデルが実験中に得られた結果にどれだけうまく対応しているかがチェックされます。
Tier-1の計算能力とストレージ容量は比較的大きいです。 たとえば、 英語のTier-1には約10Pbのテープとディスクと約14,000のコアがあります。
実験に参加したい人全員がそれを買う余裕があるわけではありません。 したがって、小規模なデータセンター(Tier-2、そのうち約140 、Tier-3)がTier-1からデータを「フィード」します。
Tier-2は独自のテープストレージを持たなくなり、その地域のTier-1から受信したデータのみを処理します。
ロシアのティア2レベルのセンター9 。 比較のために:すべてのロシアのTier-2コンピューティングシステムは「唯一の」4Pbディスクと7,500コアを占めており、それらはコンピューターセンター間で不均等に分散されています。