
良い一日!
今日は、トレンドを追跡する方法についてお話します。 グーグルがそれをどのように行うかを見て、Habrタグに基づいて同様の傾向を作りたいという要望がありました。 すべてのユーザーが誠意を持ってタグを設定しているわけではありませんが、それが正しいと認めれば、良い結果を得ることができます。 それでは試してみましょう。
1.説明
正直なところ、最初からすべてのタグを収集して降順で並べ替え、最も頻繁に使用されるタグとそうでないタグを確認することだけが考えられていました。 しかし、私はもう少し先に進むことにしました-日付を追加することで、この頻度を時間内に見ることが可能になり、明確にするためにグラフを追加しました。 これはすべて終わりになりますが、今のところは最初から始めます。
「タグ」という単語がテキストの後半にあることをすぐに予約します。これはタグ、タグ、ラベルと同じです。 ユニコードに問題はなかったので、Python 3.3.2で記述します。
2.構造と準備
このタスクには、データベースが必要です。 post_tagsとtagsの2つのテーブルが含まれます。 最初のpidのフィールドは投稿ID、tidはタグID、日付はタグ付きの投稿日です。 2番目のROWIDのフィールドはタグID、tag_titleはタグタイトルです。 ここではすべてが非常に単純なので、データベースを操作するためのクラスを作成しましょう。
import sqlite3 class Base: def __init__(self,dbname): self.con=sqlite3.connect(dbname) def __del__(self): self.con.close( ) def maketables(self): """ """ self.con.execute('create table post_tags(pid,tid,date)') self.con.execute('create table tags(tag_title)') self.con.commit( )
すべてがtags.pyファイルに保存されているので、試してみましょう:
import tags extend = tags.Base('tags.db') extend.maketables()
これで空のベースができました。それを埋めましょう。
3.タグの解析
すべてのタグを収集し、投稿の公開日と一緒に書き留めてください。 これを行うには、 beautifulsoupとurllib.requestを使用します。
作成したクラスに関数を追加します。
- get_tag-データベースからタグを取得します
- add_tag-タグを追加します
- add_post-投稿を表示および追加します
解析のための機能コード
def get_tag(self, name, added = True): """ , tid, cur - res - added - / , false """ cur=self.con.execute("select rowid from %s where %s='%s'" % ('tags','tag_title',name)) res=cur.fetchone( ) if res==None: if added: cur=self.con.execute("insert into %s (%s) values ('%s')" % ('tags','tag_title',name)) self.con.commit( ) return cur.lastrowid else: return False else: return res[0] def add_tag(self, pid, name, date): """ pid - name - date - """ rowid = self.get_tag(name); print(pid,rowid ,name, date) self.con.execute("insert into %s (%s,%s,%s) values (%d,%d,'%s')" % ('post_tags','pid','tid','date',pid,rowid,date)) self.con.commit( ) def add_post(self, pid): """ ( ) """ if (self.get_post(pid)): return print('-'*10,'http://habrahabr.ru/post/'+str(pid),'-'*10) cur=self.con.execute("select pid from %s where %s=%d" % ('post_tags','pid',pid)) res=cur.fetchone( ) if res==None: try: soup=BeautifulSoup(urllib.request.urlopen('http://habrahabr.ru/post/'+str(pid)).read( )) except (urllib.request.HTTPError): self.add_tag(pid,"parse_error_404","") print("error 404") else: published = soup.find("div", { "class" : "published" }) tags = soup.find("ul", { "class" : "tags" }) if tags: for tag in tags.findAll("a"): self.add_tag(pid, tag.string, get_date(published.string)) else: self.add_tag(pid,"parse_access_denied","") print("access denied") else: print("post has already")
データベースを満たすには、すべての投稿のサイクルを開始するだけで十分です。 196,000に制限され、彼は2013年10月1日に転倒します。
for pid in range(196000): extend.add_post(pid+1)
この方法は完全ではなく、メガビットインターネットでは約170時間動作することを知っています。
プロセスを高速化するために、論理部分に関連付けられていない別の投稿IDを保存する別の投稿テーブルを追加し、それをフラグとして使用することにしました。 そのため、ほとんどの場合、プログラムはハングします。 ページがロードされるのを待っている間に、これらのプログラムをさらにいくつか実行し、1つのデータベースを設定して並列に入力できます。 衝突の発生は確かに可能であり、最終的に、損失または部分的な記録は投稿の3%に達しましたが、それほど多くありません。 このようなアクションの後、8つを超えるプログラムが並行して動作できないことが判明しました。 開始9で、Habrは503にかなり論理的なエラーを与えます 。 したがって、6つのインスタンスを起動することで(このような量ではエラーが発生せず、互いに競合しませんでした)、 ベース (17 Mb)が取得されました。
4.データ処理
実際、今の主要部分は受信したデータを処理することです。
作成したクラスに関数を追加します。
- get_count_byid-タグIDによる番号
- get_graph-タプルのリスト(日付、数量)を取得します
- get_image-画像を表示
- get_all_tags_sorted-降順で並べ替え
- get_all_tag_count-タプル(ID、タグ、数量)のリストを取得します
データ処理の機能コード
def get_count_byname(self, name, date = ''): """ name tid get_count_byid name - date - (*) mm_yyyy """ tid = self.get_tag(name, False) return self.get_count_byid(tid, date) def get_count_byid(self, tid, date = ''): """ """ if tid: if date: count=self.con.execute("select count(pid) from %s where %s=%d and %s='%s'" % ('post_tags','tid',tid,'date',date)) else: count=self.con.execute("select count(pid) from %s where %s=%d" % ('post_tags','tid',tid)) res=count.fetchone( ) return res[0] else: return False def get_graph(self, name): """ - """ month = ('01',''),('02',''),('03',''),('04',''),('05',''),('06',''),('07',''),('08',''),('09',''),('10',''),('11',''),('12','') years = [2006,2007,2008,2009,2010,2011,2012,2013] graph = [] for Y in years: for M,M_str in month: date = str(M)+'_'+str(Y) graph.append((date, self.get_count_byname(name, date))) return graph def get_image(self, name): """ m_x - X m_y - Y img_x - img_y - """ img_x = 960 img_y = 600 img=Image.new('RGB',(img_x,img_y),(255,255,255)) draw=ImageDraw.Draw(img) graph = self.get_graph(name) max_y = max(graph,key=lambda item:item[1])[1] if max_y == 0: print('tag not found') return False m_x, m_y = int(img_x/(len(graph))), int(img_y/max_y) draw.text((10, 10), str(max_y), (0,0,0)) draw.text((10, 20), name, (0,0,0)) x,prev_y = 0,-1 for x_str, y in graph: x += 1 if (x%12 == 1): draw.text((x*m_x, img_y - 30), str(x_str[3:]),(0,0,0)) if prev_y >= 0: draw.line(((x-1)*m_x, img_y-prev_y*m_y-1, x*m_x, img_y-y*m_y-1), fill=(255,0,0)) prev_y = y img.save('graph.png','PNG') Image.open('graph.png').show() def get_all_tags_sorted(self, tags): """ """ return sorted(tags, key=lambda tag:tag[2], reverse=True) def get_all_tag_count(self): count=self.con.execute("select count(rowid) from %s" % ('tags')) res=count.fetchone( ) alltag_count = res[0] tags = [] for tag_id in range(alltag_count-1): tags.append((tag_id+1,self.get_tag_name(tag_id+1),self.get_count_byid(tag_id+1))) print (tag_id+1,self.get_tag_name(tag_id+1),self.get_count_byid(tag_id+1)) return tags
5.結果(統計のファン向け)
トップ25リーダータグ
- グーグル-2611
- アンドロイド-2188
- Google-2024
- Linux-1978
- php-1947
- JavaScript-1877
- マイクロソフト-1801
- リンゴ-1668
- ソーシャルネットワーク-1509
- スタートアップ-1484
- スタートアップ-1317
- プログラミング-1229
- マイクロソフト-1220
- Java-1180
- ゲーム-1141
- アップル-1135
- iphone-1122
- デザイン-1110
- パイソン-1108
- ユーモア-1061
- インターネット-1040
- オタク雑誌-983
- ビデオ-970
- 広告-968
- Android-876
完全なリストはここにあります (id形式、title_tag、参照数)。
さて、実際には、トレンドの概念に戻ります。 以下にいくつかの例を示します(クリック可能):
| python | javascript | アンドロイド |
 | 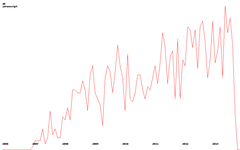 | 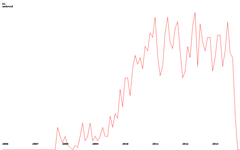 |
同様の結果を得るためのより良い方法があると確信していますが、「私は魔術師ではありませんが、ただ学ぶだけです。」 コメントでみんなに議論と改善をお願いします。
原則として、私の目標は達成されました。 ただし、ケースの独立性と形態、およびタグのリストをすぐに送信する機能の追加についてはすでに考えられています。
完全なコードはgithubに投稿されています。
ご清聴ありがとうございました、私は批判することをうれしく思います。