たとえば、「The Texas Chainsaw Massacre」など、次に何が起こるかを見出しが明確に述べているとき、私はいつもそれが好きでした。 そのため、カットの下で、DBMSに空間検索を実際に追加しますが、元々そこにはありませんでした。
入門
空間検索の重要性と有用性について一般的な言葉を使わずにやってみましょう。
既に統合された空間検索を備えたオープンDBMSを使用できない理由を尋ねられたとき、答えは「あなたが何かをうまくやりたいなら、自分でやりなさい」(C)です。 しかし、真剣に、私たちは、実際の空間問題のほとんどが、過電圧や特別なコストなしに完全に普通のデスクトップで解決できることを示しようとします。
実験的なDBMSとして、 OpenLink Virtuosoのオープンエディションを使用します。 有料版では、空間インデックスが利用できますが、これはまったく別の話です。 なぜこのDBMSなのか? 著者は彼女が好きです。 高速、簡単、強力。 すべてをコピーして実行します。 通常のツールのみを使用し、Cプラグインや特別なアセンブリは使用せず、公式のアセンブリとテキストエディタのみを使用します。
インデックスの種類
ピクセルコード(ブロック)インデックスを使用してポイントにインデックスを付けます。
ピクセルコードインデックスとは何ですか? これは、スイープカーブの妥協バージョンであり、2次元検索空間で不正確なオブジェクトを操作できます。 このクラスで次のすべてのメソッドを組み合わせます。
- サーチスペースを何らかの方法でブロックに分割する
- すべてのブロックには番号が付けられています。
- 各インデックス付きオブジェクトには、それが配置されている1つ以上のブロック番号が割り当てられます
- 検索する場合、エクステントはブロックに分割され、各ブロックまたは通常の整数インデックス(Bツリー)からのブロックの連続チェーンについて、それらに属するすべてのオブジェクトが取得されます。
最も有名な方法は次のとおりです。
- 限られた精度の古き良きイグルー(または他の掃引曲線 )。 スペースはラティスによってカットされ、そのステップは(通常)インデックス付けされたオブジェクトの特徴的なサイズです。 セルにはX ... xY ... yZ ... z ...つまり 法線に沿って細胞数を接着します。
- HEALPix この名前は、階層的等面積アイソラティチュードピクセル化に由来します。 この方法は、Iglooの主な欠点(異なる緯度のセルの下の異なる領域)を回避するために、球面を分割するように設計されています。 球体は12の等しい領域に分割され、各領域はさらに4つのサブセクションに階層的に分割されます。 このメソッドの図は、記事のヘッダーにあります。
- Hierarchical Triangular Mesh( HTM ):これは、それぞれが4つのサブ三角形に階層的に分割されている8つの開始三角形から開始して、三角形を使用して連続的に球に近づくためのスキームです

- 最もよく知られているブロックインデックススキームの1つはGRIDです。 空間データは、多次元インデックスの特殊なケースと見なされます。 この場合:
- グリルを使用してスペースを分割します
- 結果のセルには何らかの方法で番号が付けられます
- 特定のセルのデータは一緒に保存されます
- 属性値は、「ディレクトリ」を使用して軸に沿ってセル番号に変換され、小さいと想定され、メモリに保存されます
- 「ディレクトリ」が大きい場合は、ツリーに沿ってレベルに分割されます
- 変更すると、逆にラティスが適応し、セルまたは列が分割またはマージされます
主なものはおそらく、非適応性であり、特定のタスクのインデックスをカスタマイズする必要があるため、ブロックインデックスには利点があります:シンプルさと雑多です。 本質的に、これは追加のセマンティックロードを持つ通常のツリーです。 インデックス作成時にジオメトリを何らかの方法で数値に変換し、同様にインデックスを検索するためのキーを取得します。
この論文では、PL / SQLを使用して座標を安価に数値に変換できるため、水平スキャン(+1 ystein )を使用します。 Cプラグインを使用せずにHTMまたはヒルベルト曲線を使用することは困難です。
データ型
なぜドットなのか? 既に述べたように、ブロックインデックスはインデックス付けと同じです。 同時に、ポイントのラスタライザーは簡単であり、ポリゴンの場合は記述する必要があります。これは、トピックを開示する上で絶対に重要ではありません。
実際のデータ
さらに苦労せずに、
- ラティス4000X4000のノードに(0,0)およびステップ1で始まるポイントを配置します。
- 1600万ポイントの正方形が得られます。
- 10X10のブロックインデックスセルを取得し、
- 100ポイントごとに400x400のセルがあります。
データを生成するには、 AWKで次の種類のスクリプトを使用します(「data.awk」とします)。
BEGIN { cnt = 1; sz = 4000; # Set the checkpoint interval to 100 hours -- enough to complete most of experiments. print"checkpoint_interval (6000);"; print"SET AUTOCOMMIT MANUAL;"; for (i=0; i < sz; i++) { for (j=0; j < sz; j++) { print "insert into \"xxx\".\"YYY\".\"_POINTS\""; print " (\"oid_\",\"x_\", \"y_\") values ("cnt","i","j");"; cnt++; } print"commit work;" } print"checkpoint;" print"checkpoint_interval (60);"; exit; }
サーバー
- 会社のWebサイトから公式ビルドを入手します。
作者は最新バージョン7.0.0(x86_64)を使用しましたが、これは重要ではありません。他のものでも構いません。 - インストールされていない場合、 Microsoft Visual C ++ 2010再頒布可能パッケージ(x64)をインストールします。
- 実験用のディレクトリを選択し、libeay32.dll、ssleay32.dll、isql.exe、virtuoso-t.exeをアーカイブ「bin」から、virtuoso.iniをアーカイブ「database」からコピーします
- 「start virtuoso-t.exe + foreground」を使用してサーバーを起動し、ファイアウォールがポートを開くことを許可します
- 「isql localhost:1111 dba dba」コマンドを使用してサーバーの可用性をテストします。 接続を確立した後、たとえば紹介します。 「選択1;」 サーバーが稼働していることを確認してください。
データスキーマ
まず、ポイントテーブルを作成します。
create user "YYY"; create table "xxx"."YYY"."_POINTS" ( "oid_" integer, "x_" double precision, "y_" double precision, primary key ("oid_") );
インデックス自体:
create table "xxx"."YYY"."_POINTS_spx" ( "node_" integer, "oid_" integer references "xxx"."YYY"."_POINTS", primary key ("node_", "oid_") );
ここで、node_はスペースセルの識別子です。 インデックスはテーブルとして作成されますが、両方のフィールドが主キーに存在するため、ツリーにパッケージ化されることに注意してください。
インデックスオプションを構成します。
registry_set ('__spx_startx', '0'); registry_set ('__spx_starty', '0'); registry_set ('__spx_nx', '4000'); registry_set ('__spx_ny', '4000'); registry_set ('__spx_stepx', '10'); registry_set ('__spx_stepy', '10');
registry_setシステム関数を使用すると、文字列の名前と値のペアをシステムレジストリに書き込むことができます。これは、補助テーブルに保持するよりもはるかに高速であり、トランザクションでカバーされます。
記録トリガー:
create trigger "xxx_YYY__POINTS_insert_trigger" after insert on "xxx"."YYY"."_POINTS" referencing new as n { declare nx, ny integer; nx := atoi (registry_get ('__spx_nx')); declare startx, starty double precision; startx := atof (registry_get ('__spx_startx')); starty := atof (registry_get ('__spx_starty')); declare stepx, stepy double precision; stepx := atof (registry_get ('__spx_stepx')); stepy := atof (registry_get ('__spx_stepy')); declare sx, sy integer; sx := floor ((n.x_ - startx)/stepx); sy := floor ((n.y_ - starty)/stepy); declare ixf integer; ixf := (nx / stepx) * sy + sx; insert into "xxx"."YYY"."_POINTS_spx" ("oid_","node_") values (n.oid_,ixf); };
これらすべてを、たとえば「sch.sql」に入れて、実行します
isql.exe localhost:1111 dba dba <sch.sql
データの読み込み
スキームの準備ができたら、データを入力できます。
gawk -f data.awk | isql.exe localhost:1111 dba dba >log 2>errlog
著者は8Gbのメモリを搭載したIntel i7-3612QM 2.1GHzで45分(毎秒6000)かかりました。
このサーバーが占有するメモリのサイズは約1 Gbで、ディスク上のデータベースのサイズは540 Mbでした。 ポイントあたり約34バイトとそのインデックス。
次に、結果が正しいことを確認する必要があります。isqlに入力します
select count(*) from "xxx"."YYY"."_POINTS"; select count(*) from "xxx"."YYY"."_POINTS_spx";
両方の要求は16,000,000を発行する必要があります。
ガイドとして、 ここで公開されているデータを使用できます。
 。
。
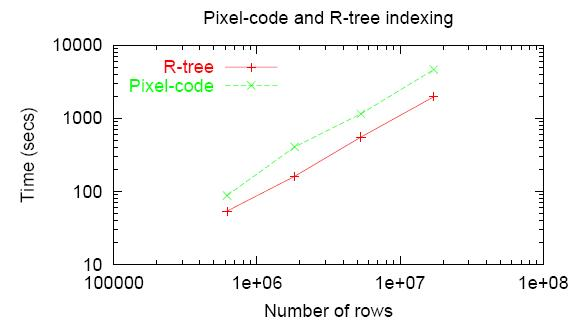
これらは、PostgreSQL(Linux)、2.2GHz Xeonで受信されます。
一方で、データは9年前に取得されました。 一方、この場合、ディスク操作はボトルネックであり、過去の期間のディスクへのランダムアクセスはそれほど加速していません。
そして、 ここで 、空間インデックス付けの時間は、実際のデータを埋める時間と釣り合っていることがわかります。
後続のインデックス付けでデータがいっぱいになることは、明らかな理由で、オンザフライでインデックス付けするよりもはるかに高速であることに注意してください。 ただし、その場でインデックスを作成することに興味があります。 実際には、空間DBMSは空間検索エンジンよりも興味深いものです。
それでもなお、空間データを入力するときは、入力の順序が非常に重要であることに注意してください。
この作業と前述のポイントの両方で、空間インデックスの観点から理想的な(またはそれに近い)送り順序が理想的でした。 データを混在させると、選択するDBMSに関係なく、パフォーマンスが大幅に低下します。
データがランダムに来る場合は、データをサンプに蓄積し、オーバーフローしたときに部分的にソートして入力することをお勧めします。
検索を設定しています
これを行うために、Virtuosoのこのような素晴らしい機能を手続き型ビューとして使用します。
create procedure "xxx"."YYY"."_POINTS_spx_enum_items_in_box" ( in minx double precision, in miny double precision, in maxx double precision, in maxy double precision) { declare nx, ny integer; nx := atoi (registry_get ('__spx_nx')); ny := atoi (registry_get ('__spx_ny')); declare startx, starty double precision; startx := atof (registry_get ('__spx_startx')); starty := atof (registry_get ('__spx_starty')); declare stepx, stepy double precision; stepx := atof (registry_get ('__spx_stepx')); stepy := atof (registry_get ('__spx_stepy')); declare sx, sy, fx, fy integer; sx := floor ((minx - startx)/stepx); fx := floor (1 + (maxx - startx - 1)/stepx); sy := floor ((miny - starty)/stepy); fy := floor (1 + (maxy - starty - 1)/stepy); declare mulx, muly integer; mulx := nx / stepx; muly := ny / stepy; declare res any; res := dict_new (); declare cnt integer; for (declare iy integer, iy := sy; iy < fy; iy := iy + 1) { declare ixf, ixt integer; ixf := mulx * iy + sx; ixt := mulx * iy + fx; for select "node_", "oid_" from "xxx"."YYY"."_POINTS_spx" where "node_" >= ixf and "node_" < ixt do { dict_put (res, "oid_", 0); cnt := cnt + 1; } } declare arr any; arr := dict_list_keys (res, 1); gvector_digit_sort (arr, 1, 0, 1); result_names(sx); foreach (integer oid in arr) do { result (oid); } }; create procedure view "xxx"."YYY"."v_POINTS_spx_enum_items_in_box" as "xxx"."YYY"."_POINTS_spx_enum_items_in_box" (minx, miny, maxx, maxy) ("oid" integer);
本質的に、この手順は非常に簡単です。ブロックインデックスのどのセルが検索範囲に入るかを見つけ、これらのセルの各行に対してサブリクエストを作成し、エントリの識別子をハッシュマップに書き込み、重複を排除し、結果として識別子のセットを提供します。
空間インデックスの使用方法 たとえば、次のように:
select count(*), avg(x.x_), avg(x.y_) from "xxx"."YYY"."_POINTS" as x, "xxx"."YYY"."v_POINTS_spx_enum_items_in_box" as a where a.minx = 91. and a.miny = 228. and a.maxx = 139. and a.maxy = 295. and x."oid_" = a.oid and x.x_ >= 91. and x.x_ < 139. and x.y_ >= 228. and x.y_ < 295.;
ここで、結合は、識別子によってプロシージャビューからのポイントテーブルと合成レコードの間で行われます。 ここで、手続き型ビューは、セルに対して正確に機能する粗いフィルターとして機能します。 したがって、最後の行に薄いフィルターを配置します。
期待される結果:
- 番号:(139-91)*(295-228)= 3216
- X平均:(139 + 91-1)/ 2 = 114.5(右境界線が除外されているため-1)
- Y平均:(295 + 228-1)/ 2 = 261(...)
ベンチマーク
リクエストフローを準備するには、次のAWKスクリプトを使用します。
BEGIN { srand(); for (i=0; i < 100; i++) { for (j=0; j < 100; j++) { startx = int(rand() * 3900); finx = int(startx + rand() * 100); starty = int(rand() * 3900); finy = int(starty + rand() * 100); print "select count(*), avg(x.x_), avg(x.y_) from"; print "\"xxx\".\"YYY\".\"_POINTS\" as x, " print "\"xxx\".\"YYY\".\"v_POINTS_spx_enum_items_in_box\" as a" print "where a.minx = "startx". and a.miny = "starty"." print " and a.maxx = "finx". and a.maxy = "finy". and" print "x.\"oid_\" = a.oid and x.x_ >= "startx". and x.x_ < "finx"." print " and x.y_ >= "starty". and x.y_ < "finy".;" } } exit; }
ご覧のとおり、ランダムなサイズ(0〜100)のランダムな場所で10,000件のリクエストを受け取ります。 このようなセットを4つ準備し、3つの一連のテストを実行します。テストで1つのisqlを実行し、2つを並列に、4つを並列に実行します。 8コアプロセッサでは、さらに並列化する意味がありません。 パフォーマンスを測定します。
- 1スレッド:151秒=スレッドあたり1秒あたり約66リクエスト
- 2スレッド:159秒=〜63 ...
- 4スレッド:182秒=〜55 ...
2つの通常のインデックスx_&y_を使用して、これらの時間を脳脊髄路で得られた時間と比較することができます。 これらのフィールドでテーブルのインデックスを作成し、タイプのクエリで同様の一連のテストを実行します
select count(*), avg(x.x_), avg(x.y_) from "xxx"."YYY"."_POINTS" as x where x.x_ >= 91. and x.x_ < 139. and x.y_ >= 228. and x.y_ < 295.;
結果は次のとおりです。一連の10,000件のクエリが417秒で完了し、1秒あたり24件のクエリがあります。
おわりに
提示された方法にはいくつかの欠点がありますが、その主な点は、既に述べたように、特定のタスク用に構成する必要があることです。 そのパフォーマンスは、インデックスの作成後に変更できない設定に大きく依存します。 ただし、これはほとんどの空間インデックス一般に当てはまります。
しかし、膝の上に書かれたそのようなインデックスでさえ、まともなパフォーマンスをもたらします。 さらに、プロセスを完全に制御しているため、これに基づいて、通常の方法では構成が難しいマルチテーブルインデックスなど、より複雑な構造を作成できます。 でも、次回はどうにかして。