みんなに敬礼! 気分が良いことを願っています。 今日、太陽は雲の後ろから少しの間覗いていたので、私は確かにすべてを完璧に持っています!
この記事では、Rubyと組み合わせて使用するための多数のコンパイルツールについて説明します。 そして、主題に飛び込むために、JSONパーサーを作成します。 すでに私は次のような不機嫌な感嘆の声を聞いています。「まあ、アーロン、なぜ? すでに1,234,567の作品が書かれていませんか?」それだけです! すでに1,234,567個のRuby JSONパーサーがあります! また、JSON分析も行います。その文法は、一度にジョブを完了するのに十分なほど単純であり、Ruby用に開発されたコンパイルツールを賢く使用するのに十分に複雑だからです。
読み続ける前に、これは決してJSONの解析方法に関する記事ではなく、Rubyでの分析およびコンパイルツールの使用方法に関する記事であるという事実に注目したいと思います。
何が必要ですか
Ruby 1.9.3でテストしますが、選択した実装で動作するはずです。 主に
Racc
や
StringScanner
などのツールを使用します。
ラック:
アナライザーを自動的に生成するには、Raccが必要です。 これは、YACCに似た多くの点でLALRアナライザージェネレーターです。 最後の略語は「Yet Another Compiler Compiler」(別のコンパイラコンパイラ)を表しますが、これはRubyのバージョンであるため、Raccが判明しました。 Raccは、一連の文法規則(拡張子が
.y
ファイル)を、状態マシンの遷移規則を記述するRubyファイルに変換することを約束しています。 後者は、Raccステートマシン(ランタイム)によって解釈されます。 ランタイムにはRubyが付属していますが、拡張子が「.y」のファイルをマシンの状態テーブルに変換するツールはありません。
gem install racc
実行して
gem install racc
。
以降、「。y」ファイルを作成しますが、エンドユーザーはそれらを実行できません。 これを行うには、まずRuby実行可能コードに変換してから、このコードをgemにパックする必要があります。 実際、これはgem Raccのみをインストールすることを意味し、エンドユーザーには必要ありません。
これらすべてが頭に収まらない場合でも心配しないでください。 理論から実践に移行し、コードの記述を開始すると、すべてが明らかになります。
StringScanner:
StringScannerは、スキャナーの原理に従って、文字列を順番に処理できるクラスです(名前が示すとおり)。 行のどこにいるかに関する情報を保存し、正規表現と文字の直接読み取りを使用して最初から最後まで移動できるようにします。
さあ始めましょう! まず、
StringScanner
オブジェクトを作成し、
StringScanner
使用していくつかの文字を処理します。
irb(main):001:0> require 'strscan' => true irb(main):002:0> ss = StringScanner.new 'aabbbbb' => #<StringScanner 0/7 @ "aabbb..."> irb(main):003:0> ss.scan /a/ => "a" irb(main):004:0> ss.scan /a/ => "a" irb(main):005:0> ss.scan /a/ => nil irb(main):006:0> ss => #<StringScanner 2/7 "aa" @ "bbbbb"> irb(main):007:0>
この位置の正規表現が適合しなくなったため、 StringScanner#scanの 3回目の呼び出しで
nil
返されたことに注意してください。 また、
StringScanner
インスタンスに対して
inspect
が呼び出されると、文字列内のハンドラーの現在位置(この場合は
2/7
)を確認できます。
StringScanner#getchを使用して、ハンドラーを文字ごとに移動することもできます。
irb(main):006:0> ss => #<StringScanner 2/7 "aa" @ "bbbbb"> irb(main):007:0> ss.getch => "b" irb(main):008:0> ss => #<StringScanner 3/7 "aab" @ "bbbb"> irb(main):009:0>
getch
メソッドは次の文字を返し、ポインターを1つ進めます。
順次文字列処理の基本を理解したので、Raccの使用方法を見てみましょう。
Raccの基本
先ほど言ったように、RaccはLALRアナライザージェネレーターです。 これは、制限された正規表現セットを作成できるメカニズムであり、比較の実行過程でさまざまな位置で任意のコードを実行できるメカニズムであると想定できます。
例を見てみましょう。 次の形式の正規表現の置換を確認したいとします:
(a|c)*abb
。 つまり、任意の数の文字「a」または「c」の後に「abb」が続く場合を登録します。 これをRacc文法に変換するために、この正規表現を構成部分に分割してから、再度組み立てようとします。 個々の文法要素は、生成規則または生成物と呼ばれます。 したがって、この表現を分解して、製品の外観とRaccの文法の形式を見てみましょう。
まず、文法ファイルを作成します。 ファイルの先頭には、取得したいRubyクラスの宣言があり、その後に製品を宣言することを意味する
rule
キーワードが続き、その後に
end
を示す
end
キーワードが続きます。
class Parser rule end
「a | c」の製品を追加します。 彼女を
a_or_c
と呼びましょう:
class Parser rule a_or_c : 'a' | 'c' ; end
結果として、文字「a」または「c」とのマッチングを実行するルール
a_or_c
があります。 比較を1回以上実行するために、
a_or_cs
呼ばれる再帰的な製品を作成します。
class Parser rule a_or_cs : a_or_cs a_or_c | a_or_c ; a_or_c : 'a' | 'c' ; end
前述したように、
a_or_cs
は再帰的であり、正規表現
(a|c)+
と同等です。 次に、「abb」の製品を追加します。
class Parser rule a_or_cs : a_or_cs a_or_c | a_or_c ; a_or_c : 'a' | 'c' ; abb : 'a' 'b' 'b'; end
そして、すべての弦製作を完了します。
class Parser rule string : a_or_cs abb | abb ; a_or_cs : a_or_cs a_or_c | a_or_c ; a_or_c : 'a' | 'c' ; abb : 'a' 'b' 'b'; end
この最終出力は、1つ以上の文字「a」または「c」の後に「abb」または独立した文字列「abb」が存在するパターンと一致します。 これはすべて、
(a|c)*abb
という形式の元の正規表現と同等です。
アーロン、でもつまらない!
これは、正規表現よりもはるかに長いことを知っています。 しかし、1つプラスがあります。マッピングプロセスの任意の場所で任意のRubyコードを追加して実行できます。 たとえば、独立した文字列「abb」に出会うたびに、次のようなものを印刷できます。
class Parser rule string : a_or_cs abb | abb { puts " abb, !" } ; a_or_cs : a_or_cs a_or_c | a_or_c ; a_or_c : 'a' | 'c' ; abb : 'a' 'b' 'b'; end
実行するコードは中括弧で囲み、その実行を担当するルールの直後に配置する必要があります。 これで、独自のJSONアナライザーを作成する準備が整いました。この場合、このアナライザーは、取得した知識を備えたイベントベースのイベントです。
アナライザーを作成する
アナライザーは、パーサー、字句アナライザー、ドキュメントプロセッサの3つのコンポーネントオブジェクトで構成されます。 Racc文法に基づいて構築されたパーサーは、入力ストリームからのデータについて字句解析プログラムにアクセスします。 パーサーは、共通のデータストリームからJSON要素を分離するたびに、対応するイベントをドキュメントハンドラーに送信します。 ドキュメントハンドラーは、JSONからデータを収集し、それをRubyのデータ構造に変換します。 JSON形式のソースデータを分析するプロセスでは、以下のグラフに示すように、呼び出しが行われます。
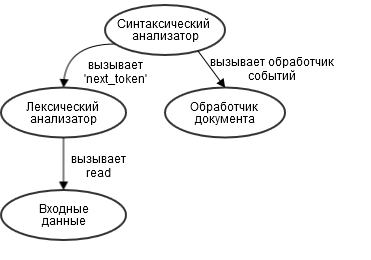
しかし、ビジネスに取り掛かりましょう。 まず、字句解析に焦点を当て、次にパーサーの文法を扱い、最後にドキュメントハンドラーを作成してプロセスを完了します。
字句解析器
字句アナライザはIO機能に基づいて構築されています。 それからソースデータを読み取ります。
next_token
呼び出されるたび
next_token
字句解析
next_token
入力ストリームから1つのトークンを読み取り、それを返します。 JSON仕様から借用した次のトークンのリストで動作します 。
- ひも
- 数字
- 本当
- 偽
- ヌル
配列やオブジェクトのような複雑なタイプの場合、パーサーが責任を負います。
next_token
によって返される値はnext_token
。
パーサーは、字句解析
next_token
呼び出すときに、結果として2つの要素の配列または
nil
を受け取ることを想定しています。 配列の最初の要素にはトークンの名前を含める必要があり、2番目の要素には何でもかまいません(通常、これは単なるテキストの一致です)。
nil
返すことにより
nil
字句解析
nil
トークンがもうないことを報告します。
Tokenizer
レキシカルアナライザーTokenizer
:
クラスコードを見て、それが何をするのか見てみましょう:
module RJSON class Tokenizer STRING = /"(?:[^"\\]|\\(?:["\\\/bfnrt]|u[0-9a-fA-F]{4}))*"/ NUMBER = /-?(?:0|[1-9]\d*)(?:\.\d+)?(?:[eE][+-]?\d+)?/ TRUE = /true/ FALSE = /false/ NULL = /null/ def initialize io @ss = StringScanner.new io.read end def next_token return if @ss.eos? case when text = @ss.scan(STRING) then [:STRING, text] when text = @ss.scan(NUMBER) then [:NUMBER, text] when text = @ss.scan(TRUE) then [:TRUE, text] when text = @ss.scan(FALSE) then [:FALSE, text] when text = @ss.scan(NULL) then [:NULL, text] else x = @ss.getch [x, x] end end end end
最初に、StringScanner文字列ハンドラーと組み合わせて使用するいくつかの正規表現の宣言があります。 これらはjson.orgから取得した定義に基づいて構築されます。 StringScannerインスタンスがコンストラクターで作成されます。 作成時に文字列が必要なため、IOオブジェクトの読み取りを呼び出します。 ただし、これは、字句解析プログラムがオブジェクトのIOからデータを読み取らない代替実装を除外するものではありませんが、必要に応じて行います。
主な作業は
next_token
メソッドで行われます。 文字列ハンドラーにデータがない場合は
nil
返します。そうでない場合は、正しい正規表現が見つかるまで各正規表現をチェックします。 一致が見つかった場合、パターンに一致するテキストとともにトークン名(例
:STRING
)を返します。 どの正規表現も一致しない場合、ハンドラーから1文字が読み取られ、読み取られた値がトークンの名前とその値として同時に返されます。
字句解析器にJSON形式の文字列の例を示し、出力で取得するトークンを確認しましょう。
irb(main):003:0> tok = RJSON::Tokenizer.new StringIO.new '{"foo":null}' => #<RJSON::Tokenizer:0x007fa8529fbeb8 @ss=#<StringScanner 0/12 @ "{\"foo...">> irb(main):004:0> tok.next_token => ["{", "{"] irb(main):005:0> tok.next_token => [:STRING, "\"foo\""] irb(main):006:0> tok.next_token => [":", ":"] irb(main):007:0> tok.next_token => [:NULL, "null"] irb(main):008:0> tok.next_token => ["}", "}"] irb(main):009:0> tok.next_token => nil
この例では、IOを使用してダックタイピングを実現するために、JSON文字列を
StringIO
オブジェクトにラップしました。 次に、いくつかのトークンを読み取ってください。 アナライザーによく知られている各トークンは、配列の最初の要素に付いている名前で構成されていますが、不明なトークンでは、この場所は1文字で占められています。 たとえば、行トークンは
[:STRING, "foo"]
になり、特定の場合、不明なトークンは
['(', '(']
ます。最後に、入力データがなくなると、出力は
nil
ます。
これで、字句アナライザーでの作業が完了しました。 入力での初期化中に、
IO
オブジェクトを受け取り、1つの
next_token
メソッドを実装します。 パーサーに行くことができるすべて。
パーサー
構文に入る時間です。 始めに、少しすくい作業を始めましょう。
.y
ファイルに基づくRubyベースのファイル生成を実装する必要があります。
rake
だけの仕事 1
コンパイルタスクについて説明します。
まず、 「次のコマンドを使用して
.y
ファイルを
.rb
ファイルに変換する」というルールをrake-file に
.rb
ます 。
rule '.rb' => '.y' do |t| sh "racc -l -o #{t.name} #{t.source}" end
次に、生成された
parser.rb
ファイルに依存する「コンパイル」タスクを追加します。
task :compile => 'lib/rjson/parser.rb'
文法ファイルは
lib/rjson/parser.y
に保存されている
rake compile
、rake
rake compile
を実行
rake compile
、rakeは
.rb
を使用して
.y
ファイルを拡張子
.rb
ファイルに自動的に変換します。
そして最後に、「テスト」タスクを「コンパイル」タスクに依存させるため、
rake test
を実行すると、コンパイルされたバージョンが自動的に生成されます。
task :test => :compile
これで、
.y
ファイルのコンパイルと検証に直接進むことができます。
JSON.org仕様の解析:
ここで、 json.orgからのグラフをRacc文法形式に変換します。 オブジェクトまたは配列のいずれかがソースドキュメントのルートにある必要があるため、object-
object
またはarray-
array
一致する
document
作成を作成し
document
。
rule document : object | array ;
次に、
array
の積を定義します。 配列の積は、空にするか、1つ以上の値を含めることができます。
array : '[' ']' | '[' values ']' ;
値の生産は、単一の値、またはコンマで区切られた複数の値として再帰的に定義されます。
values : values ',' value | value ;
JSON仕様では、
value
文字列、数値、オブジェクト、配列、true(true)、false(false)、またはnull(値なし)として定義されています。 定義は似ていますが、唯一の違いは、NUMBER(数値)、TRUE(真)、FALSE(偽)などの即値に対して、字句アナライザで定義された対応するトークン名を使用することです。
value : string | NUMBER | object | array | TRUE | FALSE | NULL ;
オブジェクト(
object
)の製品の定義に進み
object
。 オブジェクトは空にすることも、ペアで構成することもできます。
object : '{' '}' | '{' pairs '}' ;
1つまたは複数のペアがあり、それらはコンマで区切る必要があります。 繰り返しますが、再帰的な定義を使用します。
pairs : pairs ',' pair | pair ;
最後に、コロンで区切られた文字列と数値であるペアを定義します。
pair : string ':' value ;
Raccに語彙トークンについて通知し、最初に定義を追加すると、パーサーの準備が整います。
class RJSON::Parser token STRING NUMBER TRUE FALSE NULL rule document : object | array ; object : '{' '}' | '{' pairs '}' ; pairs : pairs ',' pair | pair ; pair : string ':' value ; array : '[' ']' | '[' values ']' ; values : values ',' value | value ; value : string | NUMBER | object | array | TRUE | FALSE | NULL ; string : STRING ; end
ドキュメントハンドラー
ドキュメントハンドラーは、パーサーからイベントを受け取ります。 彼は驚異的なJSONから比類なきRubyオブジェクトを構築します! 私があなたの裁量で残すイベントの数ですが、私は自分自身を5に制限します:
-
start_object
オブジェクトの先頭で呼び出されます -
end_object
オブジェクトの終わりに呼び出されます -
start_array
配列の先頭で呼び出されます -
end_array
配列の最後で呼び出されます -
scalar
-文字列、true、falseなどのターミナルケースで呼び出されます。
これらの5つのイベントを使用して、元のJSON構造を反映するオブジェクトを組み立てます。
イベントをフォローします
ハンドラーは、パーサーからのイベントを単に追跡します。 結果はツリー構造になり、それに基づいて最終的なRubyオブジェクトを構築します。
module RJSON class Handler def initialize @stack = [[:root]] end def start_object push [:hash] end def start_array push [:array] end def end_array @stack.pop end alias :end_object :end_array def scalar(s) @stack.last << [:scalar, s] end private def push(o) @stack.last << o @stack << o end end end
パーサーがオブジェクトの先頭を検出するたびに、ハンドラーはハッシュ記号付きのリストをスタックの先頭に追加して、連想配列の先頭を示します。 子であるイベントは親に追加され、オブジェクトの終わりが検出されると、親はスタックからポップされます。
初めて理解するのが難しいことを除外しませんので、いくつかの例を見てみましょう。 入力で
{"foo":{"bar":null}}
の形式のJSON文字列を渡すと、
@stack
stackスタック変数に次のようになります。
[[:root, [:hash, [:scalar, "foo"], [:hash, [:scalar, "bar"], [:scalar, nil]]]]]
たとえば、
["foo",null,true]
という形式の配列を
@stack
で取得すると、次のようになります。
[[:root, [:array, [:scalar, "foo"], [:scalar, nil], [:scalar, true]]]]
Rubyに変換:
このようにしてJSONドキュメントの中間表現を取得したら、Rubyでのデータ構造への変換に進みます。 これを行うには、結果のツリーを処理するための再帰関数を作成します。
def result root = @stack.first.last process root.first, root.drop(1) end private def process type, rest case type when :array rest.map { |x| process(x.first, x.drop(1)) } when :hash Hash[rest.map { |x| process(x.first, x.drop(1)) }.each_slice(2).to_a] when :scalar rest.first end end
result
メソッドは
root
ノードを削除し、残ったものを
process
メソッドに渡します。
process
が
hash
文字を検出すると、
process
再帰呼び出しの子を使用して連想配列を形成し
process
。 これと同様に、配列の子に対する再帰呼び出しは、文字
array
に遭遇したときに配列を構築します。 スカラー値-
scalar
処理なしで返されます(無限再帰を防ぎます)。 ハンドラから
result
を呼び出すと、出力で完成したRubyオブジェクトが取得されます。
実際にどのように機能するか見てみましょう:
require 'rjson' input = StringIO.new '{"foo":"bar"}' tok = RJSON::Tokenizer.new input parser = RJSON::Parser.new tok handler = parser.parse handler.result # => {"foo"=>"bar"}
ソフトウェアインターフェースの改善:
完全に機能するJSONアナライザーを自由に使用できます。 確かに、1つの欠点があります-非常に便利なソフトウェアインターフェイスがありません。 前の例を使用して改善してみましょう。
module RJSON def self.load(json) input = StringIO.new json tok = RJSON::Tokenizer.new input parser = RJSON::Parser.new tok handler = parser.parse handler.result end end
アナライザーは元々IOオブジェクトに基づいて構築されたため、入力時にソケットまたはファイル記述子を転送したい人のためのメソッドを追加できます。
module RJSON def self.load_io(input) tok = RJSON::Tokenizer.new input parser = RJSON::Parser.new tok handler = parser.parse handler.result end def self.load(json) load_io StringIO.new json end end
インターフェースがもう少し便利になったことを確認します。
require 'rjson' require 'open-uri' RJSON.load '{"foo":"bar"}' # => {"foo"=>"bar"} RJSON.load_io open('http://example.org/some_endpoint.json')
大声で考え
これで、アナライザーの作業が完了しました。 その過程で、解析と字句解析の基本を含むコンパイルテクノロジーに精通し、さらにインタープリターに触れました(実際、JSONの解釈に従事していました)。 誇りに思うものがあります!
私たちが書いたアナライザーは非常に柔軟であることがわかりました。 できること:
- ハンドラーハンドラーを実装して、イベントパラダイムで使用する
- 簡素化されたインターフェイスを使用し、文字列を入力に渡すだけです
- IOオブジェクトを介してJSON形式でストリームを送信するには
この記事があなたに自信を与えてくれることを願っています。そして、Rubyで実装された分析およびコンパイル技術を自分で試してみてください。 まだ私に質問がある場合は、 コメントで歓迎します 。
PS
結論として、追加のあいまいさを導入しないように、プレゼンテーション中に省略したいくつかの詳細を明確にしたいと思います。
- アナライザーの最終文法は次のとおりです。 .yファイルの-innerセクションに注意してください。 このセクションで示されるすべてのものは、自動生成の結果として取得されるパーサークラスに追加されます。 これは、ハンドラオブジェクトをパーサーに渡す方法です。
- パーサーは、実際にターミナルJSONノードからRuby への変換を行います。 そのため、パーサーとドキュメントハンドラーでJSONをRubyに2回変換します。 後者は構造を担当し、前者は即時値(true、falseなど)を担当します。 すべての変換をパーサーで実行するか、逆にパーサーから完全に除外する必要があることに注意することは非常に合理的です。
- 最後に、 字句解析プログラムはバッファリングを使用します。 ここから取得できる非バッファバージョンをスケッチしました。 それはかなり粗雑ですが、有限状態マシンのロジックを使用して頭に浮かぶことができます。
以上です。 ご清聴ありがとうございました!
1英語 熊手-熊手
翻訳に関するコメントは、個人で送ってください。