 翻訳者から:これは、Mozilla IdentityチームによるNode.jsシリーズの 5番目の記事で、 ペルソナプロジェクトに関係しています。
翻訳者から:これは、Mozilla IdentityチームによるNode.jsシリーズの 5番目の記事で、 ペルソナプロジェクトに関係しています。
サイクルのすべての記事:
- 「 Node.jsでのメモリリークのハンティング 」
- 「 ノードを眼球にロードします 」
- 「 アプリケーションのスケーリングを簡素化するために、クライアントにセッションを保存します 」
- 「 フロントエンドのパフォーマンス。パート1-連結、圧縮、キャッシング 」
- 「 負荷がかかってもクラッシュしないサーバーを作成しています 」
- 「 フロントエンドのパフォーマンス。パート2-etagifyを使用した動的コンテンツのキャッシュ 」
- 「 node-convictを使用したWebアプリケーション構成の調整 」
- 「 フロントエンドのパフォーマンス。パート3-フォントの最適化 」
- 「 Node.jsアプリケーションのローカライズパート1 」
- 「 Node.jsアプリケーションのローカライズパート2:ツールキットとプロセス 」
- 「 Node.jsアプリケーションのローカライズパート3:アクションのローカライズ 」
- 「 Awsbox-Amazon CloudにNode.jsアプリケーションをデプロイするためのPaaSインフラストラクチャ 」
不可能な負荷がかかっても機能し続けるNode.jsアプリケーションを作成する方法は? この記事では、ノードを混雑させる方法論とそれを実装するライブラリを示します。その本質は、このコードフラグメントによって最も簡単に伝えることができます。
var toobusy = require('toobusy'); app.use(function(req, res, next) { if (toobusy()) res.send(503, "I'm busy right now, sorry."); else next(); });
問題は何ですか?
アプリケーションが人々にとって重要なタスクを実行する場合、最も悲惨なシナリオについて考える時間を費やす価値があります。 それは良い意味で災害になる可能性があります-あなたのサイトがソーシャルメディアの注目の的になり、1日あたり1万人の訪問者の代わりに、100万人が突然あなたに来ます。 事前に準備しておけば、突然の出勤に耐えることができ、通常の負荷を桁違いに超えるサイトを作成できます。 これらの準備を怠ると、サイトは完全に表示されているときに、必要なときに正確に落ちます。
これは、DoS攻撃などによる悪意のあるトラフィックの急増です。 このような攻撃に対処する最初のステップは、クラッシュしないサーバーを作成することです。
サーバーに負荷がかかっています
出席者の急増に備えていない通常のサーバーの動作を示すために、リクエストごとに5つの非同期呼び出しを行い、合計で5ミリ秒のプロセッサー時間を費やすデモアプリケーションを作成しました。
これはおおよそ、通常のアプリケーションに対応しており、リクエストごとにログに何かを書き込んだり、データベースにアクセスしたり、テンプレートをレンダリングしたり、クライアントに応答を送信したりできます。 以下は、TCP遅延とエラー対接続数のグラフです。
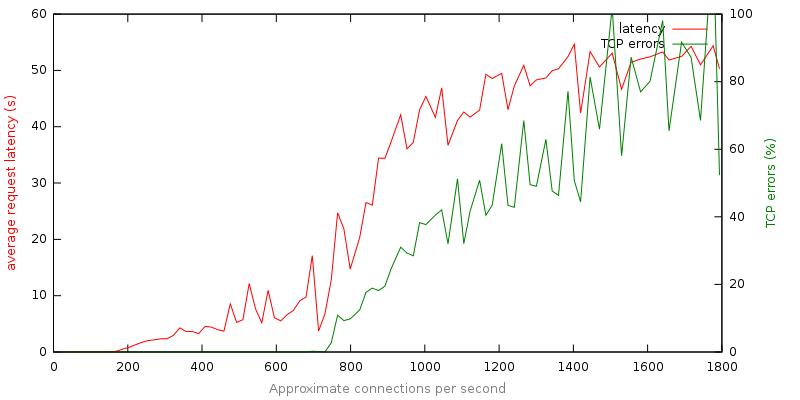
このデータの分析は非常に明白です。
- サーバーをレスポンシブと呼ぶことはできません。 標準の負荷(1秒あたり1200リクエスト)の6倍の負荷では、40秒後に平均応答できしみ音が聞こえます。
- 失敗はひどく見えます。 80%のケースでは、ユーザーはほぼ1分間の退屈な待機の後にエラーメッセージを受け取ります。
丁寧に拒否することを学ぶ
比較のために、記事の冒頭で説明したアプローチをデモアプリケーションに適用しました。 これにより、負荷が許容範囲を超えたときを判断し、すぐにエラーメッセージで応答できます。 以下は、彼の最初の例に似たグラフです。
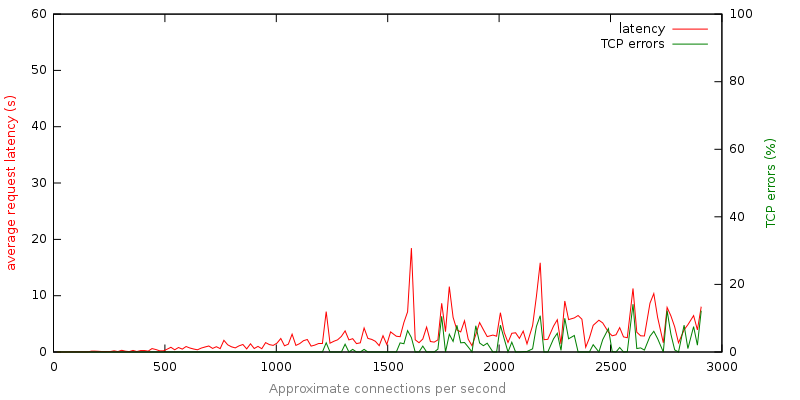
グラフには、コード503( サービスが利用不可 )のエラーの数は表示されません。負荷が増加するにつれて徐々に増加します。 このグラフを見て、どのような結論を導き出すことができますか?
- 転送エラーメッセージは信頼性を高めます。 標準負荷の10倍の負荷の下では、アプリケーションは非常に責任を持って動作します。
- 成功した応答または失敗はすぐに発生します。 平均応答時間はほとんどの場合10秒未満です。
- 障害は丁寧に発生します。 輻輳中にリクエストを事前に拒否すると、厄介なタイムアウトの脱落が、503番目のエラーを伴う即時応答に置き換えられます。
サーバーに503番目のエラーを正確に報告させるには、ユーザーへのメッセージを含む小さなテンプレートを作成するだけです。 このような回答の例は、多くの人気サイトで見ることができます。
node-toobusyの使用方法
node-toobusyモジュールはnpmパッケージとしてgithubで利用可能です。 インストール後(
npm install toobusy
)、通常はアプリケーションに含まれます:
var toobusy = require('toobusy');
接続後、モジュールはプロセスの監視を開始し、いつ過負荷になるかを判断します。 アプリケーション内のどこでもそのステータスを確認できますが、リクエスト処理の初期段階で確認することをお勧めします。
// middleware, // , - app.use(function(req, res, next) { // - toobusy() , // if (toobusy()) res.send(503, "I'm busy right now, sorry."); else next(); });
すでにこの形式であるため、node-toobusyモジュールは負荷時のアプリケーションの安定性を大幅に向上させます。 アプリケーションに最適な感度値を選択する必要があります。
どのように機能しますか?
Nodeアプリケーションがビジー状態であると確実に判断するにはどうすればよいですか?
これは、ノードツービジーがすべてのアプリケーションですぐに動作することを特に考慮すると、予想されるよりも興味深い質問です。 この問題を解決するためのいくつかのアプローチを検討してください。
現在のプロセスのCPU使用率を追跡します。
top
コマンドで示される数値(プロセッサがアプリケーションに費やす時間の割合)を使用できます。 たとえば、この数値が90%を超える場合、アプリケーションが過負荷になっていると結論付けることができます。 しかし、マシン上で複数のプロセスが実行されている場合、それがプロセッサを100%使用できるNodeアプリケーションを備えたプロセスであるかどうかを確認できなくなります。 このようなシナリオでは、アプリケーションがこれらの90%に達することはなく、同時に実質的に横たわることがあります。
総システム負荷の追跡。 アプリケーションの過負荷を判断する際に考慮するために、システムの合計負荷を計算できます。 利用可能なプロセッサコアの数なども考慮する必要があります。 非常に迅速に、このアプローチは非常に複雑であることが判明し、プラットフォーム依存の拡張が必要になりますが、プロセスの優先度を考慮する必要があります!
うまく機能するソリューションが必要です。 必要なのは、アプリケーションが許容可能なレートでリクエストに応答できないことを判断することだけです。 この基準は、プラットフォームやシステム内の他のプロセスに依存しません。
node-toobusyでは、メインイベントループのレイテンシ測定が使用されます。 このループは、Node.jsアプリケーションの心臓部です。 すべての作業はキューに入れられ、メインサイクルでは、このキューのタスクが順番に実行されます。 プロセスが過負荷になると、キューが大きくなり始めます-実行できる以上の作業があります。 輻輳の程度を調べるには、キュー全体を守るために小さなタスクにかかる時間を測定するだけで十分です。 これを行うために、node-toobusyは500ミリ秒ごとに呼び出す必要があるコールバックを使用します。 間隔の実際の測定値から500ミリ秒を引くと、タスクがキューに入っていた時間、つまり希望の遅延を取得できます。
したがって、node-toobusyは、メインイベントループの遅延を絶えず測定して、プロセスの過負荷を判断します。これは、あらゆるサーバーのあらゆる環境で機能するシンプルで信頼性の高い方法です。
サイクルのすべての記事:
- 「 Node.jsでのメモリリークのハンティング 」
- 「 ノードを眼球にロードします 」
- 「 アプリケーションのスケーリングを簡素化するために、クライアントにセッションを保存します 」
- 「 フロントエンドのパフォーマンス。パート1-連結、圧縮、キャッシング 」
- 「 負荷がかかってもクラッシュしないサーバーを作成しています 」
- 「 フロントエンドのパフォーマンス。パート2-etagifyを使用した動的コンテンツのキャッシュ 」
- 「 node-convictを使用したWebアプリケーション構成の調整 」
- 「 フロントエンドのパフォーマンス。パート3-フォントの最適化 」
- 「 Node.jsアプリケーションのローカライズパート1 」
- 「 Node.jsアプリケーションのローカライズパート2:ツールキットとプロセス 」
- 「 Node.jsアプリケーションのローカライズパート3:アクションのローカライズ 」
- 「 Awsbox-Amazon CloudにNode.jsアプリケーションをデプロイするためのPaaSインフラストラクチャ 」