John Torjoの本Boost.Asio C ++ Network Programmingの翻訳を続けています。
内容:
- 第1章:Boost.Asioの使用開始
- 第2章:Boost.Asioの基本
- 第3章:エコーサーバー/クライアント
- 第4章:クライアントとサーバー
- 第5章:同期と非同期
- 第6章:Boost.Asio-その他の機能
- 第7章:Boost.Asio-追加トピック
Boost.Asioの作成者は素晴らしい仕事をし、同期パスまたは非同期パスを選択することで、アプリケーションに最適なものを選択する機会を与えてくれました。
前の章では、同期クライアント、同期サーバー、およびそれらの非同期オプションなど、すべてのタイプのアプリケーションのフレームワークを見てきました。 これらのそれぞれをアプリケーションの基礎として使用できます。 各タイプのアプリケーションの詳細を詳しく調べる必要がある場合は、読み進めてください。
同期プログラミングと非同期プログラミングを混在させる
Boost.Asioライブラリを使用すると、同期プログラミングと非同期プログラミングを混在させることができます。 個人的には、これは悪い考えだと思いますが、Boost.Asioは、一般的にC ++と同様に、必要に応じて自分自身を撃ちます。
特にアプリケーションが非同期で実行される場合、簡単にトラップに陥ることがあります。 たとえば、非同期の書き込み操作に応答して、たとえば非同期の読み取り操作を実行します。
io_service service; ip::tcp::socket sock(service); ip::tcp::endpoint ep( ip::address::from_string("127.0.0.1"), 8001); void on_write(boost::system::error_code err, size_t bytes) { char read_buff[512]; read(sock, buffer(read_buff)); } async_write(sock, buffer("echo"), on_write);
確かに同期読み取り操作は現在のスレッドをブロックするため、他の不完全な非同期操作はスタンバイモードになります(このスレッドの場合)。 これは悪いコードであり、アプリケーションの速度が低下したり、ブロックされたりする可能性があります(非同期アプローチを使用する主な目的は、ブロックを回避することです。したがって、同期操作を使用すると、これは拒否されます) 同期アプリケーションを使用している場合は、非同期の読み取りまたは書き込み操作を使用することはほとんどありません。同期的に考えることは、既に線形に考えることを意味します(A、B、Cなど)。
私の意見では、同期操作と非同期操作が連携できる唯一のケースは、たとえば、同期ネットワークとデータベースからの入出力の非同期操作など、完全に分離されている場合です。
クライアントからサーバーへ、またはその逆へのメッセージの配信
優れたクライアント/サーバーアプリケーションの非常に重要な部分は、メッセージを(サーバーからクライアントへ、およびクライアントからサーバーへ)前後に配信することです。 メッセージを識別するものを指定する必要があります。 つまり、着信メッセージが読み取られているときに、メッセージが完全に読み取られたことをどのようにして知ることができますか?
メッセージの終わりを判別する必要があります(最初は判別が容易です。これは最後のメッセージの終わりの後に受信される最初のバイトです)が、それほど簡単ではないことがわかります。
次のことができます。
- 固定サイズのメッセージを作成する(これは良い考えではありません。さらにデータを送信する必要がある場合はどうしますか?)
- 「\ n」や「\ 0」など、メッセージを終了する特定の文字を作成します
- メッセージの長さをメッセージプレフィックスとして指定します。
本全体を通して、「各メッセージの最後に「\ n」文字を使用することにしました。」 したがって、メッセージを読むと、次のコードフラグメントが示されます。
char buff_[512]; // synchronous read read(sock_, buffer(buff_), boost::bind(&read_complete, this, _1, _2)); // asynchronous read async_read(sock_ buffer(buff_),MEM_FN2(read_complete,_1,_2), MEM_FN2(on_read,_1,_2)); size_t read_complete(const boost::system::error_code & err, size_t bytes) { if ( err) return 0; already_read_ = bytes; bool found = std::find(buff_, buff_ + bytes, '\n') < buff_ + bytes; // we read one-by-one until we get to enter, no buffering return found ? 0 : 1; }
読者の練習として、メッセージプレフィックスとして長さの指示を残すことは非常に簡単です。
クライアントアプリケーションの同期I / O
原則として、同期クライアントには2つのタイプがあります。
- サーバーに何かを要求し、応答を読み取って処理します。 次に、他の何かなどを要求します。 これは基本的に同期クライアントであり、前の章で説明しました。
- サーバーから着信メッセージを読み取り、処理して応答を書き込みます。 次に、次の着信メッセージなどを読み取ります。
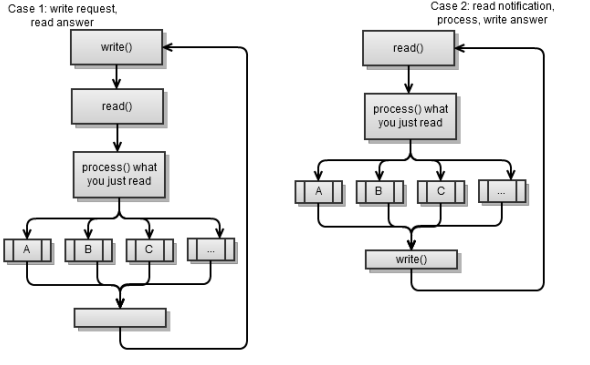
両方のシナリオは、次の戦略を使用します。要求を作成する-応答を読み取ります。 つまり、一方の当事者が要求を行い、他方の当事者が応答します。 これは、クライアント/サーバーアプリケーションを実装する簡単な方法であり、これがお勧めです。
Mambo Jamboのクライアント/サーバーをいつでも作成できます。各サイドはいつでも好きなときに書き込みますが、このパスが災害につながる可能性が非常に高くなります(クライアントまたはサーバーがブロックされたときに何が起こったのかをどうやって知るのですか?)。
以前のスクリプトは同じように見えるかもしれませんが、非常に異なっています:
- 最初のケースでは、サーバーはリクエストに応答します(サーバーはクライアントからのリクエストを待機し、リクエストに応答します)。 これは、クライアントがサーバーからの要求に応じて必要なものを受信する場合のプルのような接続です。
- 後者の場合、サーバーは応答するクライアントイベントを送信します。 これは、サーバーがクライアントに通知/イベントをプッシュするときのプッシュのような接続です。
基本的には、通常の標準と同様に、開発を容易にするプル型のクライアント/サーバーアプリケーションに遭遇します。
これらの2つのアプローチを混在させることができます。オンデマンド(クライアントサーバー)で取得し、要求(サーバークライアント)をプッシュしますが、それは困難であり、回避することをお勧めします。 これらの2つのアプローチを混合する問題があります;戦略を使用して要求を行う場合、答えを読んでください; 以下が発生する可能性があります。
- クライアントは書き込みます(リクエストを行います)
- サーバーは書き込みます(クライアントに通知を送信します)
- クライアントは、サーバーが書き込んだ内容を読み取り、これを要求への応答として解釈します
- サーバーは、クライアントが新しい要求を行ったときに到着するクライアントからの応答を待機してブロックします
- クライアントは書き込みます(新しい要求を作成します)
- サーバーは、この要求を待機していた応答として解釈します
- クライアントはブロックされます(サーバーは、クライアントの要求を通知への応答として解釈したため、サーバーは応答を返しません)。
プル型のクライアント/サーバーアプリケーションでは、前のシナリオを簡単に回避できます。 クライアントがサーバーとの接続を確認するときに、たとえば5秒ごとにpingプロセスを実装することで、プッシュのような動作をシミュレートできます。 サーバーは、報告するものがない場合はping_ok、通知するイベントがある場合はping_ [event_name]などの応答を返します。 その後、クライアントはこのイベントを処理する新しいリクエストを開始できます。
繰り返しますが、前のスクリプトは前の章の同期クライアントを示しています。 メインループ:
void loop() { // read answer to our login write("login " + username_ + "\n"); read_answer(); while ( started_) { write_request(); read_answer(); ... } }
最後のシナリオに合わせて変更します。
void loop() { while ( started_) { read_notification(); write_answer(); } } void read_notification() { already_read_ = 0; read(sock_, buffer(buff_), boost::bind(&talk_to_svr::read_complete, this, _1, _2)); process_notification(); } void process_notification() { // ... see what the notification is, and prepare answer }
サーバーアプリケーションの同期I / O
クライアントと同様に、サーバーには2つのタイプがあり、前のセクションの2つのシナリオに対応しています。 繰り返しますが、どちらのシナリオも戦略を使用しています。リクエストを作成し、レスポンスを読み取ります。
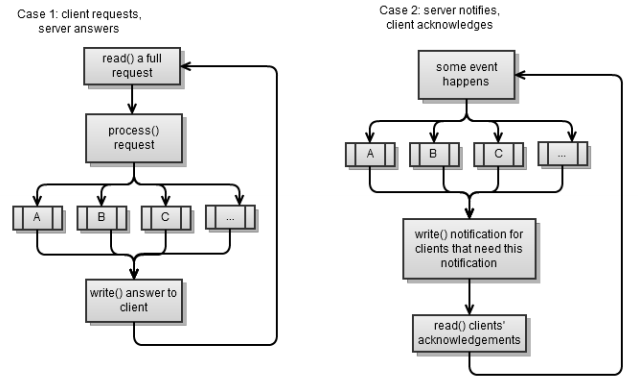
最初のシナリオは、前の章で実装した同期サーバーです。 ブロッキングを回避したいので、同期的に作業している場合は、要求を完全に読み取ることは簡単ではありません(常に可能な限り読み取ります)。
void read_request() { if ( sock_.available()) already_read_ += sock_.read_some(buffer(buff_ + already_read_, max_msg –already_read_)); }
メッセージが完全に読み取られた後、単純にメッセージを処理してクライアントに応答します。
void process_request() { bool found_enter = std::find(buff_, buff_ + already_read_, '\n') < buff_ + already_read_; if ( !found_enter) return; // message is not full size_t pos = std::find(buff_, buff_ + already_read_, '\n') - buff_; std::string msg(buff_, pos); ... if ( msg.find("login ") == 0) on_login(msg); else if ( msg.find("ping") == 0) on_ping(); else ... }
サーバーをプッシュ型サーバーにしたい場合は、次のように変更します。
typedef std::vector<client_ptr> array; array clients; array notify; std::string notify_msg; void on_new_client() { // on a new client, we notify all clients of this event notify = clients; std::ostringstream msg; msg << "client count " << clients.size(); notify_msg = msg.str(); notify_clients(); } void notify_clients() { for ( array::const_iterator b = notify.begin(), e = notify.end(); b != e; ++b) { (*b)->sock_.write_some(notify_msg); } }
on_new_client()
関数は1つのイベントの関数であり、すべてのクライアントに通知する必要があります。
notify_clients
は、このイベントにサブスクライブしているクライアントに通知する関数です。 サーバーはメッセージを送信しますが、各クライアントからの応答を待機しません。これにより、ブロックが発生する可能性があります。 クライアントから応答が来ると、クライアントはこれが通知への回答であることを伝えることができます(そしてそれを正しく処理できます)。
同期サーバーのスレッド
これは非常に重要な要素です。顧客の処理にいくつのスレッドを割り当てるのでしょうか?
同期サーバーの場合、新しい接続を処理するスレッドが少なくとも1つ必要です。
void accept_thread() { ip::tcp::acceptor acceptor(service, ip::tcp::endpoint(ip::tcp::v4(),8001)); while ( true) { client_ptr new_( new talk_to_client); acceptor.accept(new_->sock()); boost::recursive_mutex::scoped_lock lk(cs); clients.push_back(new_); } }
既存のお客様の場合:
- 片道で行くことができます。 これが最も簡単な方法であり、 第4章で同期サーバーを実装したときに選択しました。 100〜200の同時接続に簡単に対応できますが、それ以上の場合もあります。これは、ほとんどの場合に十分です。
- クライアントごとにフローを作成できます。 これはめったに良いオプションではありません。多くのスレッドを費やし、デバッグを困難にすることがあります。おそらく200人以上の同時ユーザーを処理しますが、すぐに限界に達します。
- 既存の顧客を処理するために、固定数のスレッドを作成できます。
3番目のオプションは、同期サーバーに実装するのが非常に困難です。
talk_to_client
クラス全体がスレッドセーフになりました。 次に、どのスレッドがどのクライアントを処理するかを知るための特別なメカニズムが必要になります。 これには2つのオプションがあります。
- 特定のクライアントを特定のスレッドに割り当てます。 たとえば、最初のスレッドは最初の20個のクライアントを処理し、2番目のスレッドは21〜40個のクライアントを処理します。 顧客が使用中の場合、多くの既存の顧客から抽出します。 このクライアントと協力した後、彼をリストに戻しました。 各スレッドは、既存のすべてのクライアントを循環し、最初のクライアントを完全なリクエストで処理し(クライアントからの着信メッセージを完全に読み取ります)、それに応答します。
- サーバーが応答を停止する場合があります。
- 最初のケースでは、1つのスレッドで処理された複数のクライアントが同時に要求を作成し、1つのスレッドは一度に1つの要求しか処理できません。 ただし、この場合は何もできません。
- 2番目のケースでは、スレッドよりも多くのリクエストを同時に受け取ります。 この場合、単純に新しいスレッドを作成して負荷を処理できます。
元の
answer_to_client
関数に似た次のコードは、最後のスクリプトを実装する方法を示しています。
struct talk_to_client : boost::enable_shared_from_this<talk_to_client> { ... void answer_to_client() { try { read_request(); process_request(); } catch ( boost::system::system_error&) { stop(); } } };
以下に示すように変更します。
struct talk_to_client : boost::enable_shared_from_this<talk_to_client> { boost::recursive_mutex cs; boost::recursive_mutex cs_ask; bool in_process; void answer_to_client() { { boost::recursive_mutex::scoped_lock lk(cs_ask); if ( in_process) return; in_process = true; } { boost::recursive_mutex::scoped_lock lk(cs); try { read_request(); process_request(); } catch ( boost::system::system_error&) { stop(); } } { boost::recursive_mutex::scoped_lock lk(cs_ask); in_process = false; } } };
クライアントを処理する間、その
in_process
インスタンスは
true
に設定され、他のスレッドはこのクライアントを無視します。 追加のボーナスは、
handle_clients_thread()
関数を変更できないことです。 必要なだけ
handle_clients_thread()
関数を作成できます。
クライアントアプリケーションの非同期I / O
メインのワークフローは、同期クライアントアプリケーションの同じプロセスに似ていますが、Boost.Asioが各
async_write
と
async_write
間にあるという違いがあります。
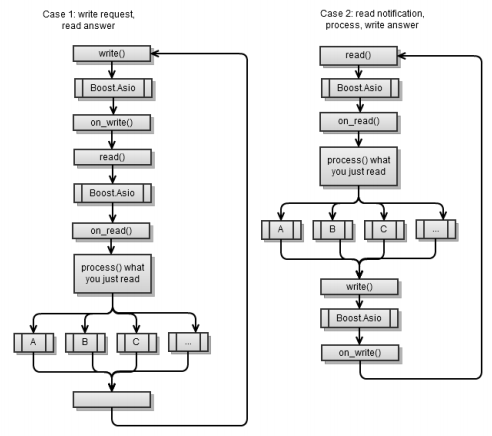
最初のシナリオは、 第4章の非同期クライアントが実装されたものと同じです。 各非同期操作の最後に、
service.run()
関数がそのアクティビティを終了しないように、別の非同期操作を開始する必要があることに注意してください。
最初のシナリオを2番目のシナリオにするには、次のコードフラグメントを使用する必要があります。
void on_connect() { do_read(); } void do_read() { async_read(sock_, buffer(read_buffer_), MEM_FN2(read_complete,_1,_2), MEM_FN2(on_read,_1,_2)); } void on_read(const error_code & err, size_t bytes) { if ( err) stop(); if ( !started() ) return; std::string msg(read_buffer_, bytes); if ( msg.find("clients") == 0) on_clients(msg); else ... } void on_clients(const std::string & msg) { std::string clients = msg.substr(8); std::cout << username_ << ", new client list:" << clients ; do_write("clients ok\n"); }
接続に成功するとすぐに、サーバーからの読み取りを開始することに注意してください。 各
on_[event]
関数は終了し、サーバーに応答を書き込みます。
非同期アプローチの利点は、Boost.Asioを使用してネットワークI / Oと他の非同期操作を混在させて、これらすべてを整理できることです。 ストリームは同期ストリームほど明確ではありませんが、実際には同期ストリームと考えることができます。
Webサーバーからファイルを読み取り、データベースに(非同期で)保存するとします。 次のフローチャートに示すように、実際にそれについて考えることができます。

サーバーアプリケーションの非同期I / O
再び、ユビキタスな2つのケース、最初のスクリプト(プル)と2番目のスクリプト(プッシュ):

最初の非同期サーバースクリプトは、前の章で実装されました。 各非同期操作の最後に、
service.run()
が期限切れにならないように別の非同期操作を開始する必要があります。
トリミングされたコードフレームワークを次に示します。 以下は、
talk_to_client
クラスのすべてのメンバーです。
void start() { ... do_read(); // first, we wait for client to login } void on_read(const error_code & err, size_t bytes) { std::string msg(read_buffer_, bytes); if ( msg.find("login ") == 0) on_login(msg); else if ( msg.find("ping") == 0) on_ping(); else ... } void on_login(const std::string & msg) { std::istringstream in(msg); in >> username_ >> username_; do_write("login ok\n"); } void do_write(const std::string & msg) { std::copy(msg.begin(), msg.end(), write_buffer_); sock_.async_write_some( buffer(write_buffer_, msg.size()), MEM_FN2(on_write,_1,_2)); } void on_write(const error_code & err, size_t bytes) { do_read(); }
簡単に言うと、読み取り操作が完了するとすぐに、読み取り操作を常に待機し、メッセージを処理してクライアントに応答します。
前のコードをプッシュサーバーに変換します。
void start() { ... on_new_client_event(); } void on_new_client_event() { std::ostringstream msg; msg << "client count " << clients.size(); for ( array::const_iterator b = clients.begin(), e = clients.end();b != e; ++b) (*b)->do_write(msg.str()); } void on_read(const error_code & err, size_t bytes) { std::string msg(read_buffer_, bytes); // basically here, we only acknowledge // that our clients received our notifications } void do_write(const std::string & msg) { std::copy(msg.begin(), msg.end(), write_buffer_); sock_.async_write_some( buffer(write_buffer_, msg.size()), MEM_FN2(on_write,_1,_2)); } void on_write(const error_code & err, size_t bytes) { do_read(); }
on_new_client_event
などのイベントが発生すると、このイベントについて通知する必要があるすべてのクライアントにメッセージが送信されます。 回答すると、受信したイベントを処理したことがわかります。 私たちは常に新しい顧客を待っているため、イベントを非同期的に待つことは決してありません(したがって
service.run()
は動作を終了しません)。
非同期サーバーのスレッド
非同期サーバーは第4章で説明しましたが、すべてが
main()
関数で発生するため、シングルスレッドです。
int main() { talk_to_client::ptr client = talk_to_client::new_(); acc.async_accept(client->sock(), boost::bind(handle_accept,client,_1)); service.run(); }
非同期アプローチの利点は、シングルスレッドバージョンからマルチスレッドバージョンへの移行が容易なことです。 少なくとも顧客が同時に200人以上になるまで、いつでも片道で行くことができます。 次に、1つのスレッドから100のスレッドに切り替えるには、次のコードフラグメントを使用する必要があります。
boost::thread_group threads; void listen_thread() { service.run(); } void start_listen(int thread_count) { for ( int i = 0; i < thread_count; ++i) threads.create_thread( listen_thread); } int main(int argc, char* argv[]) { talk_to_client::ptr client = talk_to_client::new_(); acc.async_accept(client->sock(), boost::bind(handle_accept,client,_1)); start_listen(100); threads.join_all(); }
もちろん、マルチスレッドの使用を開始したら、スレッドセーフについて考える必要があります。 スレッドAで
async_*
を呼び出した場合でも、それを完了するための手順をスレッドBで呼び出すことができます(スレッドBが
service.run()
呼び出す限り)。 これ自体は問題ではありません。 論理シーケンスに従う限り、つまり
async_read()
から
on_read()
、
on_read()
から
process_reques
t、
process_request
から
async_write()
、
async_write()
から
on_write()
、
on_write()
から
on_write()
から
async_read()
on_write()
に
async_read()
、
talk_to_client
クラスを呼び出す
public
関数はありません。異なるスレッドで異なる関数を呼び出すことができますが、それらは引き続き順番に呼び出されます。 したがって、ミューテックスは必要ありません。
ただし、これは、クライアントに対して保留できる非同期操作は1つだけであることを意味します。 ある時点で、クライアントに2つの保留中の非同期関数がある場合、ミューテックスが必要になります。 2つの保留中の操作はほぼ同時に完了することができ、最終的には2つの異なるスレッドで同時にハンドラーを呼び出すことができるためです。 したがって、スレッドセーフ、つまりミューテックスが必要です。
非同期サーバーでは、実際には同時に2つの保留中の操作があります。
void do_read() { async_read(sock_, buffer(read_buffer_), MEM_FN2(read_complete,_1,_2), MEM_FN2(on_read,_1,_2)); post_check_ping(); } void post_check_ping() { timer_.expires_from_now(boost::posix_time::millisec(5000)); timer_.async_wait( MEM_FN(on_check_ping)); }
読み取り操作を実行するとき、非同期的に一定期間その完了を待ちます。 したがって、スレッドセーフが必要です。 私のアドバイスは、マルチスレッドオプションを選択する場合は、クラスを最初からスレッドセーフにすることです。 これは通常、パフォーマンスを低下させません(もちろんこれを確認できます)。 また、マルチストリームパスを使用する場合は、最初からそれを実行してください。 したがって、初期段階で潜在的な問題が発生します。 問題が見つかったらすぐに、最初に確認する必要があるのは、実行中の1つのスレッドでこれが起こっていることですか? はいの場合、これは簡単で、デバッグするだけです。 それ以外の場合は、おそらくいくつかの機能をミューテックスするのを忘れていました。
この例ではスレッドセーフが必要なため、mutexを使用して
talk_to_client
を変更し
talk_to_client
。 さらに、コード内で何度も参照するクライアントの配列があり、独自のミューテックスも必要です。
デッドロックとメモリ破損を回避することはそれほど簡単ではありません。
update_clients_changed()
関数を変更する方法は
update_clients_changed()
です。
void update_clients_changed() { array copy; { boost::recursive_mutex::scoped_lock lk(clients_cs); copy = clients; } for( array::iterator b = copy.begin(), e = copy.end(); b != e; ++b) (*b)->set_clients_changed(); }
回避したいのは、2つのミューテックスが同時にロックされることです(デッドロック状態になる可能性があります)。 この場合、
clients_cs
とclient
clients_cs
mutexが同時にロックされないようにします。
非同期操作
Boost.Asioでは、任意の機能を非同期で実行することもできます。 次のコードスニペットを使用するだけです。
void my_func() { ... } service.post(my_func);
service.run()
を呼び出すスレッドの1つで
my_func
が呼び出されることを確認できます。 非同期関数を実行して、関数がいつ完了するかを通知するトレーリングハンドラーを作成することもできます。 擬似コードは次のようになります。
void on_complete() { ... } void my_func() { ... service.post(on_complete); } async_call(my_func);
async_call
関数はありません。独自に作成する必要があります。 幸いなことに、これはそれほど難しくありません。 次のコードスニペットを参照してください。
struct async_op : boost::enable_shared_from_this<async_op>, ... { typedef boost::function<void(boost::system::error_code)> completion_func; typedef boost::function<boost::system::error_code ()> op_func; struct operation { ... }; void start() { { boost::recursive_mutex::scoped_lock lk(cs_); if ( started_) return; started_ = true; } boost::thread t( boost::bind(&async_op::run,this)); } void add(op_func op, completion_func completion, io_service &service) { self_ = shared_from_this(); boost::recursive_mutex::scoped_lock lk(cs_); ops_.push_back( operation(service, op, completion)); if ( !started_) start(); } void stop() { boost::recursive_mutex::scoped_lock lk(cs_); started_ = false; ops_.clear(); } private: boost::recursive_mutex cs_; std::vector<operation> ops_; bool started_; ptr self_; };
async_op
構造体では、追加(
add()
)するすべての非同期関数で機能する(
run()
)バックグラウンドスレッドが作成されます。 私にとって、これは複雑なことではないようです。なぜなら、各操作に対して次のことが実行されるからです。
- 関数は非同期に呼び出されます。
-
completion
関数は、関数が最初にcompletion
するときに呼び出されます -
completion
関数を実行するio_service
インスタンス。 , . :
struct async_op : boost::enable_shared_from_this<async_op> , private boost::noncopyable { struct operation { operation(io_service & service, op_func op, completion_func completion): service(&service), op(op)completion(completion), work(new o_service::work(service)){} operation() : service(0) {} io_service * service; op_func op; completion_func completion; typedef boost::shared_ptr<io_service::work> work_ptr; work_ptr work; }; ... };
, ,
io_service::work
,
service.run()
, ( ,
io_service::work, service.run()
, ). :
struct async_op : ... { typedef boost::shared_ptr<async_op> ptr; static ptr new_() { return ptr(new async_op); } ... void run() { while ( true) { { boost::recursive_mutex::scoped_lock lk(cs_); if ( !started_) break; } boost::this_thread::sleep( boost::posix_time::millisec(10)); operation cur; { boost::recursive_mutex::scoped_lock lk(cs_); if ( !ops_.empty()) { cur = ops_[0]; ops_.erase( ops_.begin()); } } if ( cur.service) cur.service->post(boost::bind(cur.completion, cur.op() )); } self_.reset(); } };
run()
, , ; , . .
,
compute_file_checksum
, :
size_t checksum = 0; boost::system::error_code compute_file_checksum(std::string file_name) { HANDLE file = ::CreateFile(file_name.c_str(), GENERIC_READ, 0, 0, OPEN_ALWAYS, FILE_ATTRIBUTE_NORMAL | FILE_FLAG_OVERLAPPED, 0); windows::random_access_handle h(service, file); long buff[1024]; checksum = 0; size_t bytes = 0, at = 0; boost::system::error_code ec; while ( (bytes = read_at(h, at, buffer(buff), ec)) > 0) { at += bytes; bytes /= sizeof(long); for ( size_t i = 0; i < bytes; ++i) checksum += buff[i]; } return boost::system::error_code(0, boost::system::generic_category()); } void on_checksum(std::string file_name, boost::system::error_code) { std::cout << "checksum for " << file_name << "=" << checksum << std::endl; } int main(int argc, char* argv[]) { std::string fn = "readme.txt"; async_op::new_()->add( service, boost::bind(compute_file_checksum,fn), boost::bind(on_checksum,fn,_1)); service.run(); }
, . , ,
io_service
, (
post()
) . .
, (, ). , -, .
. , , . , , .
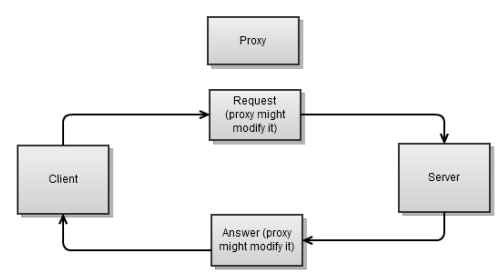
-? , , , . .
, ; ( ), ( ). , , , , , , .
:
- , . , , - .
- , , -:
class proxy : public boost::enable_shared_from_this<proxy> { proxy(ip::tcp::endpoint ep_client, ip::tcp::endpoint ep_server) : ... {} public: static ptr start(ip::tcp::endpoint ep_client, ip::tcp::endpoint ep_svr) { ptr new_(new proxy(ep_client, ep_svr)); // ... connect to both endpoints return new_; } void stop() { // ... stop both connections } bool started() { return started_ == 2; } private: void on_connect(const error_code & err) { if ( !err) { if ( ++started_ == 2) on_start(); } else stop(); } void on_start() { do_read(client_, buff_client_); do_read(server_, buff_server_); } ... private: ip::tcp::socket client_, server_; enum { max_msg = 1024 }; char buff_client_[max_msg], buff_server_[max_msg]; int started_; };
これは非常に単純なプロキシです。両端で接続すると、両方の接続で読み取りを開始します(関数
on_start()
):
class proxy : public boost::enable_shared_from_this<proxy> { ... void on_read(ip::tcp::socket & sock, const error_code& err, size_t bytes) { char * buff = &sock == &client_ ? buff_client_ : buff_server_; do_write(&sock == &client_ ? server_ : client_, buff, bytes); } void on_write(ip::tcp::socket & sock, const error_code &err, size_t bytes) { if ( &sock == &client_) do_read(server_, buff_server_); else do_read(client_, buff_client_); } void do_read(ip::tcp::socket & sock, char* buff) { async_read(sock, buffer(buff, max_msg), MEM_FN3(read_complete,ref(sock),_1,_2), MEM_FN3(on_read,ref(sock),_1,_2)); } void do_write(ip::tcp::socket & sock, char * buff, size_t size) { sock.async_write_some(buffer(buff,size), MEM_FN3(on_write,ref(sock),_1,_2)); } size_t read_complete(ip::tcp::socket & sock, const error_code & err, size_t bytes) { if ( sock.available() > 0) return sock.available(); return bytes > 0 ? 0 : 1; } };
読み取りが成功するたびに(on_read)、メッセージを反対側に渡します。メッセージが正常に送信されると(on_write)、再び読み取りを開始します。
これを機能させるには、次のコードスニペットを使用します。
int main(int argc, char* argv[]) { ip::tcp::endpoint ep_c( ip::address::from_string("127.0.0.1"), 8001); ip::tcp::endpoint ep_s( ip::address::from_string("127.0.0.1"), 8002); proxy::start(ep_c, ep_s); service.run(); }
, (
buff_client_
buff_server_
) . , , . , . , , ( ). , , :
- , , ( ).
- ( ) .
.
まとめ
, , : .
:
- ,
- (pull-like push-like)
- ,
Boost.Asio, Boost.Asio –
co-routines
, .
この記事のリソース: リンク
, !